

 Technology peripheralsAI1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Technology peripheralsAI1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT


Paper address: https://arxiv.org/abs/2307.09283
Code address: https:/ /github.com/THU-MIG/RepViT

RepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study.
- It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (
MSHA) allows the model to learn global representation. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. - In this study, the authors gradually improve the mobile-friendliness of standard lightweight CNNs (especially
MobileNetV3) by integrating effective architectural choices of lightweight ViTs. This makes Derived the birth of a new pure lightweight CNN family, namelyRepViT. It is worth noting that although RepViT has a MetaFormer structure, it is entirely composed of convolutions. - Experimental results It is shown that
RepViTsurpasses existing state-of-the-art lightweight ViTs and shows better performance and efficiency than existing state-of-the-art lightweight ViTs on various visual tasks, including ImageNet classification, Object detection and instance segmentation on COCO-2017, and semantic segmentation on ADE20k. In particular, onImageNet,RepViTachieved the best performance oniPhone 12With a latency of nearly 1ms and a Top-1 accuracy of over 80%, this is the first breakthrough for a lightweight model.
Okay, what everyone should be concerned about next is "How How can a model designed with such low latency but high accuracy come out?
Method
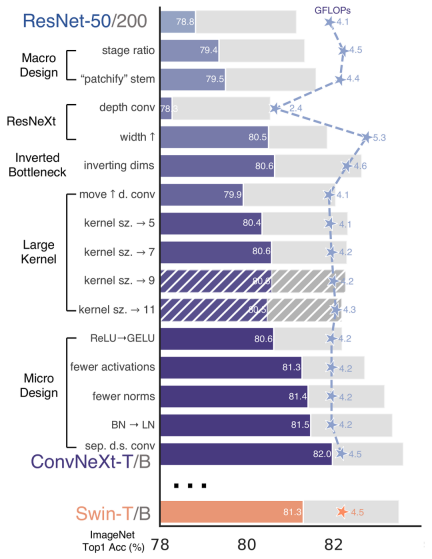
ConvNeXt , the authors based on the ResNet50 architecture through rigorous theoretical and experimental analysis, finally designed a very excellent pure convolutional neural network architecture comparable to Swin-Transformer. Similarly, RepViT also mainly performs targeted transformations by gradually integrating the architectural design of lightweight ViTs into standard lightweight CNN, namely MobileNetV3-L ( Magic modification). In this process, the authors considered design elements at different levels of granularity and achieved the optimization goal through a series of steps.

Alignment of training recipes
In the paper, a new metric is introduced to measure latency on mobile devices and ensures that the training strategy is consistent with the currently popular lightweight Level ViTs remain consistent. The purpose of this initiative is to ensure the consistency of model training, which involves two key concepts of delay measurement and training strategy adjustment.
Latency Measurement Index
In order to more accurately measure the performance of the model on real mobile devices, the author chose to directly measure the actual delay of the model on the device. as a baseline measure. This metric differs from previous studies, which mainly optimize the model's inference speed through metrics such as FLOPs or model size, which do not always reflect the actual latency in mobile applications well.
Alignment of training strategy
Here, the training strategy of MobileNetV3-L is adjusted to align with other lightweight ViTs models. This includes using the AdamW optimizer [a must-have optimizer for ViTs models], 5 epochs of warm-up training, and 300 epochs of training using cosine annealing learning rate scheduling. Although this adjustment results in a slight decrease in model accuracy, fairness is guaranteed.
Optimization of Block Design
Next, the authors explored the optimal block design based on consistent training settings. Block design is an important component in CNN architecture, and optimizing block design can help improve the performance of the network.
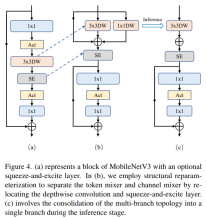
Separate Token mixer and channel mixer
This is mainly for MobileNetV3-L The block structure was improved to separate token mixers and channel mixers. The original MobileNetV3 block structure consists of a 1x1 dilated convolution, followed by a depthwise convolution and a 1x1 projection layer, and then connects the input and output via residual connections. On this basis, RepViT advances the depth convolution so that the channel mixer and token mixer can be separated. To improve performance, structural reparameterization is also introduced to introduce multi-branch topology for deep filters during training. Finally, the authors succeeded in separating the token mixer and the channel mixer in the MobileNetV3 block and named such block the RepViT block.
Reduce the dilation ratio and increase the width
In the channel mixer, the original dilation ratio is 4, which means that the hidden dimension of the MLP block is four times the input dimension times, which consumes a large amount of computing resources and has a great impact on the inference time. To alleviate this problem, we can reduce the dilation ratio to 2, thereby reducing parameter redundancy and latency, bringing the latency of MobileNetV3-L down to 0.65ms. Subsequently, by increasing the width of the network, i.e. increasing the number of channels at each stage, the Top-1 accuracy increased to 73.5%, while the latency only increased to 0.89ms!
Optimization of macro-architectural elements
In this step, this article further optimizes the performance of MobileNetV3-L on mobile devices, mainly starting from the macro-architectural elements, including stem, downsampling layer, classifier as well as overall stage proportions. By optimizing these macro-architectural elements, the performance of the model can be significantly improved.
Shallow network using convolutional extractor
 Picture
Picture
ViTs typically use a "patchify" operation that splits the input image into non-overlapping patches as the stem. However, this approach has problems with training optimization and sensitivity to training recipes. Therefore, the authors adopted early convolution instead, an approach that has been adopted by many lightweight ViTs. In contrast, MobileNetV3-L uses a more complex stem for 4x downsampling. In this way, although the initial number of filters is increased to 24, the total latency is reduced to 0.86ms, while the top-1 accuracy increases to 73.9%.
Deeper Downsampling Layers
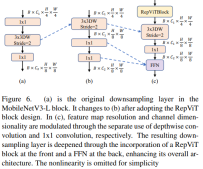
In ViTs, spatial downsampling is usually implemented through a separate patch merging layer. So here we can adopt a separate and deeper downsampling layer to increase the network depth and reduce the information loss due to resolution reduction. Specifically, the authors first used a 1x1 convolution to adjust the channel dimension, and then connected the input and output of two 1x1 convolutions through residuals to form a feedforward network. Additionally, they added a RepViT block in front to further deepen the downsampling layer, a step that improved the top-1 accuracy to 75.4% with a latency of 0.96ms.
Simpler classifier
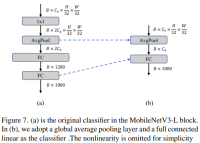
In lightweight ViTs, the classifier is usually followed by a global average pooling layer consists of a linear layer. In contrast, MobileNetV3-L uses a more complex classifier. Because the final stage now has more channels, the authors replaced it with a simple classifier, a global average pooling layer and a linear layer. This step reduced the latency to 0.77ms while being top-1 accurate. The rate is 74.8%.
Overall stage proportion
The stage proportion represents the proportion of the number of blocks in different stages, thus indicating the distribution of calculations in each stage. The paper chooses a more optimal stage ratio of 1:1:7:1, and then increases the network depth to 2:2:14:2, thereby achieving a deeper layout. This step increases top-1 accuracy to 76.9% with a latency of 1.02 ms.
Adjustment of micro-design
Next, RepViT adjusts the lightweight CNN through layer-by-layer micro design, which includes selecting the appropriate convolution kernel size and optimizing squeeze-excitation (Squeeze- and-excitation, referred to as SE) layer location. Both methods significantly improve model performance.
Selection of convolution kernel size
It is well known that the performance and latency of CNNs are usually affected by the size of the convolution kernel. For example, to model long-range context dependencies like MHSA, ConvNeXt uses large convolutional kernels, resulting in significant performance improvements. However, large convolution kernels are not mobile-friendly due to its computational complexity and memory access cost. MobileNetV3-L mainly uses 3x3 convolutions, and 5x5 convolutions are used in some blocks. The authors replaced them with 3x3 convolutions, which resulted in latency being reduced to 1.00ms while maintaining a top-1 accuracy of 76.9%.
Position of SE layer
One advantage of self-attention modules over convolutions is the ability to adjust weights based on the input, which is called a data-driven property. As a channel attention module, the SE layer can make up for the limitations of convolution in the lack of data-driven properties, thereby leading to better performance. MobileNetV3-L adds SE layers in some blocks, mainly focusing on the last two stages. However, the lower-resolution stage gains smaller accuracy gains from the global average pooling operation provided by SE than the higher-resolution stage. The authors designed a strategy to use the SE layer in a cross-block manner at all stages to maximize the accuracy improvement with the smallest delay increment. This step improved the top-1 accuracy to 77.4% while delaying reduced to 0.87ms. [In fact, Baidu has already done experiments and comparisons on this point and reached this conclusion a long time ago. The SE layer is more effective when placed close to the deep layer]
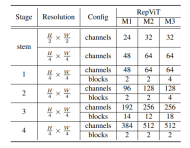
Network Architecture
Finally, by integrating the above improvement strategies, we obtained the overall architecture of the model RepViT, which has multiple variants, such as RepViT-M1/ M2/M3. Likewise, the different variants are mainly distinguished by the number of channels and blocks per stage.
Experiment
Image Classification


The above is the detailed content of 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Chinese version
Chinese version, very easy to use

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

