
Home >Technology peripherals >AI >The GPT-4 crown is gone! Claude 3 arena human voting results are released: only ranked third
The GPT-4 crown is gone! Claude 3 arena human voting results are released: only ranked third

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-03-08 15:07:27519browse
Claude 3’s arena rankings are finally here:
In just 3 days, 20,000 votes were cast, pushing the ranking’s traffic to unprecedented levels.
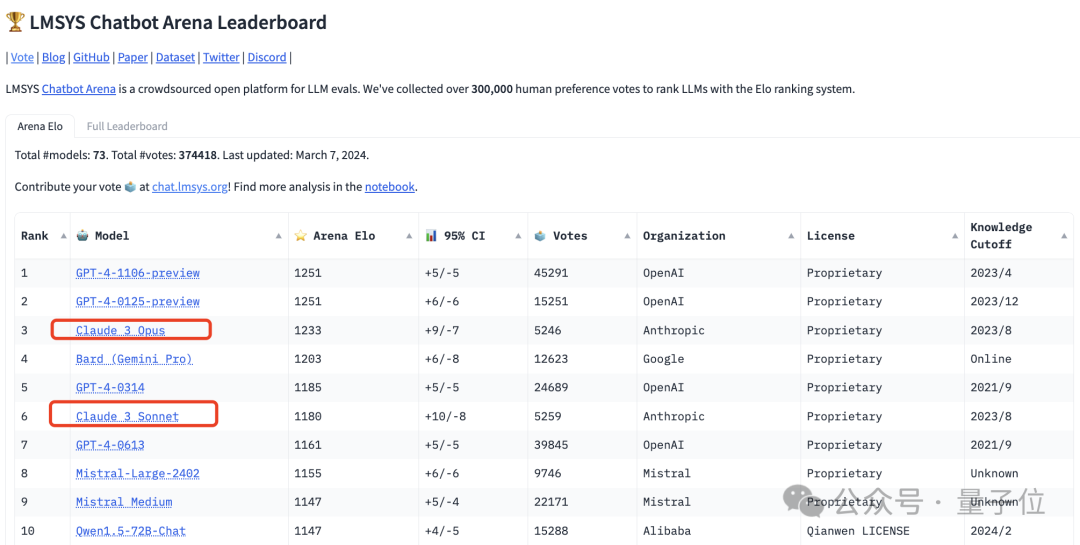
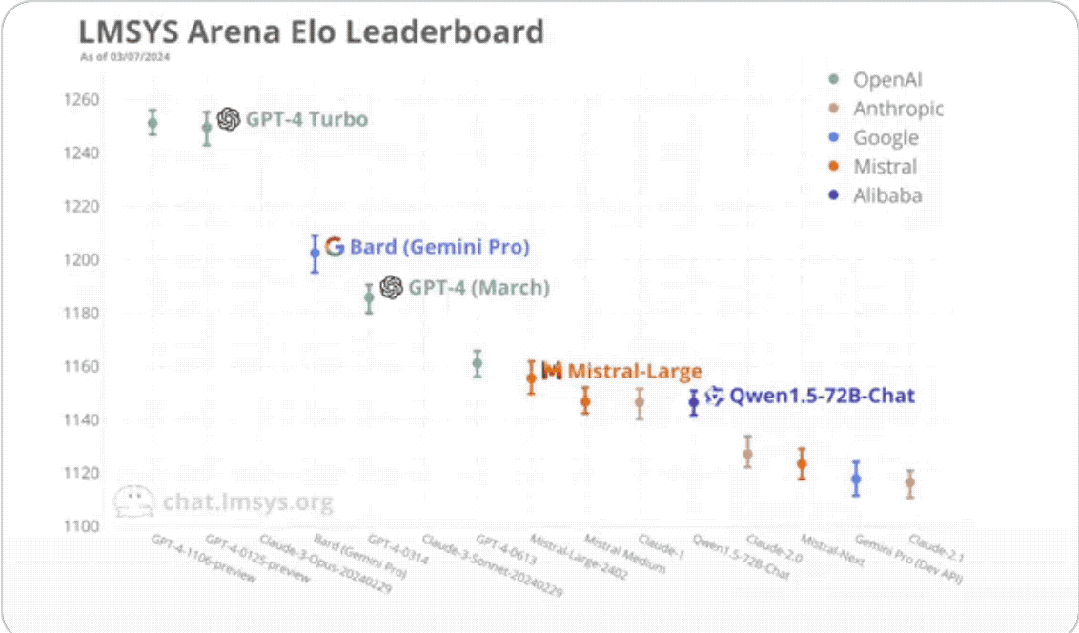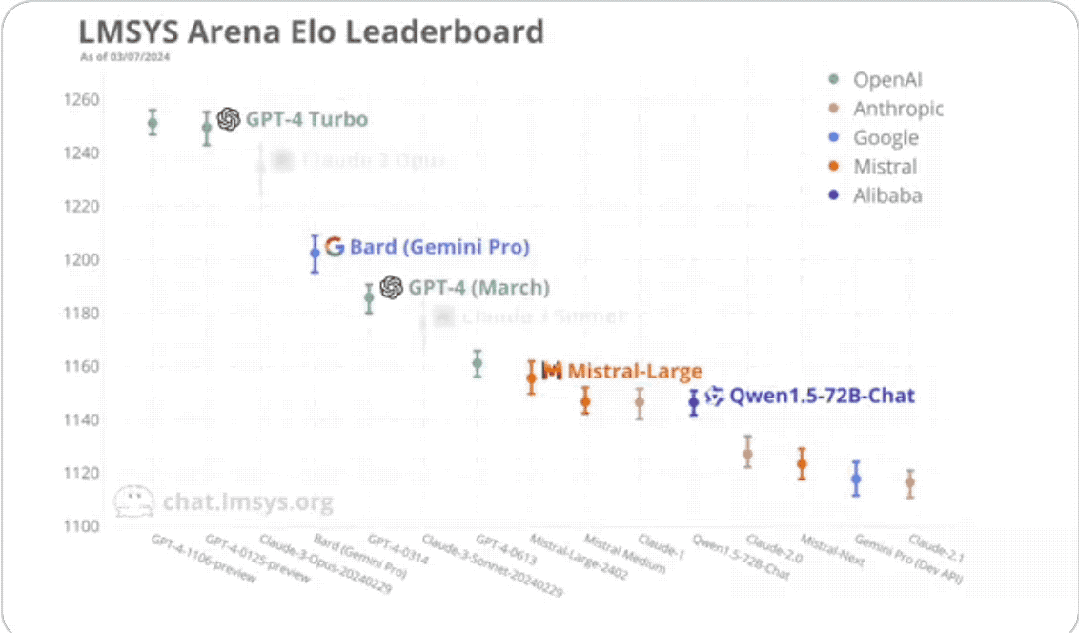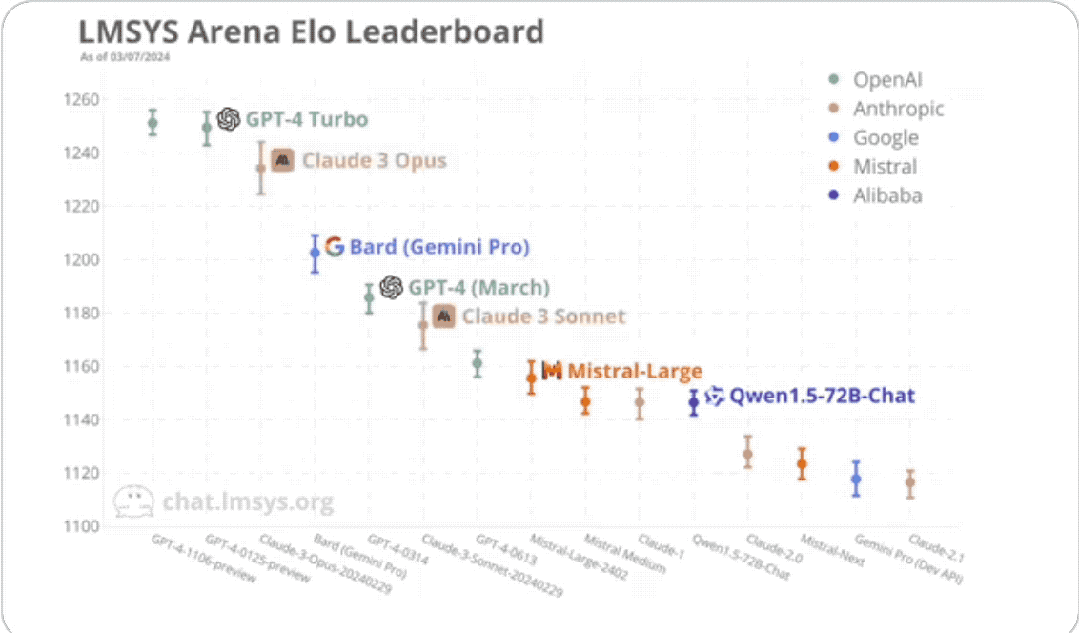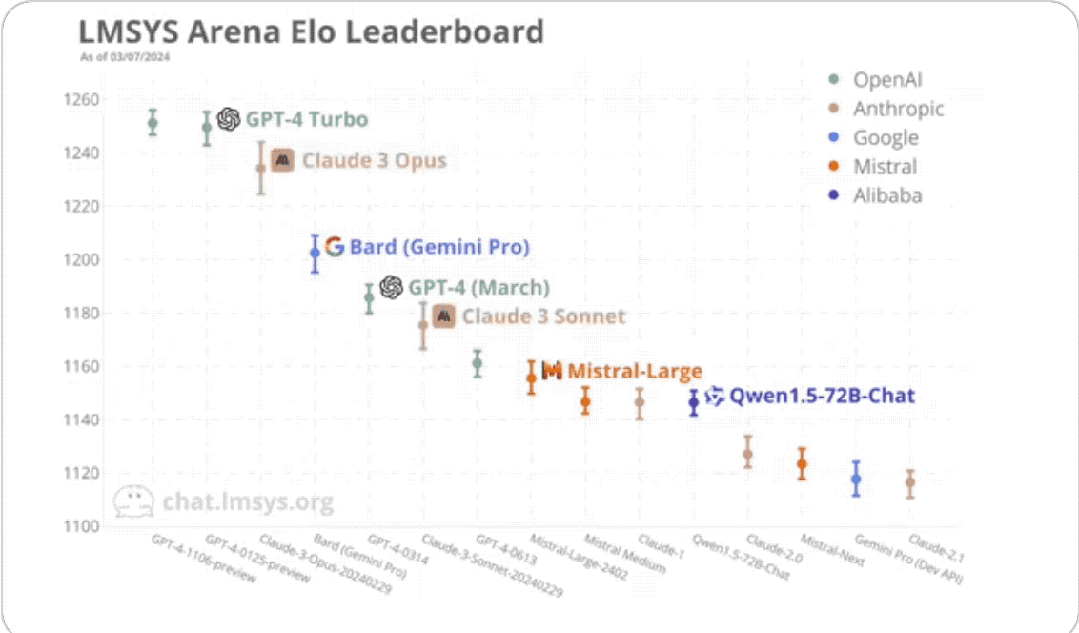
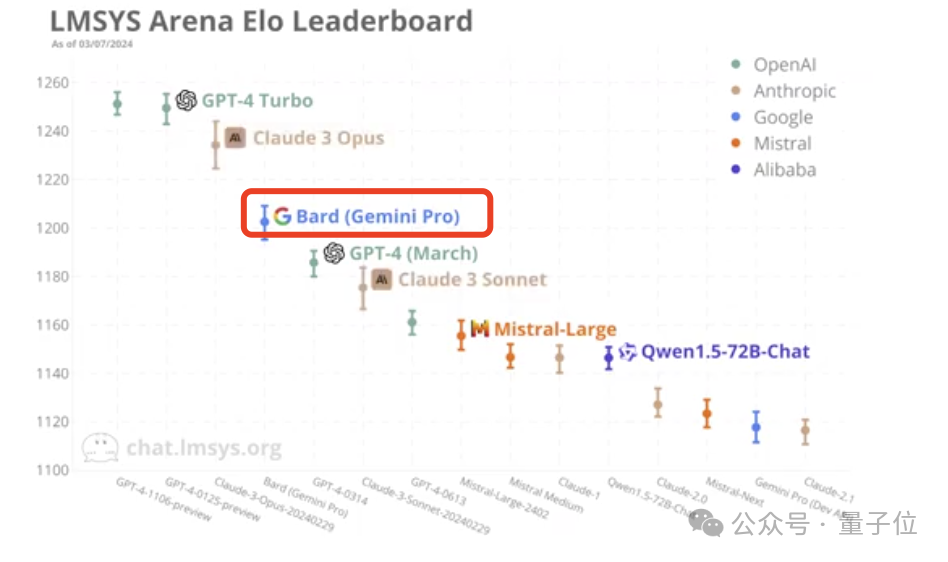
In the end, Claude 3’s strongest “big cup” model Opus scored 1233, becoming the first player to compete with GPT-4-Turbo.
The "Medium Cup" Sonnet is also pretty good, on par with the two older versions of GPT-4.
 Picture
Picture
But in general, the GPT-4 series has the upper hand.
The performance of Claude 3 is slightly different from the promotion. As netizens summarized:
GPT-4 is still the king of large models!
However, the free "medium cup" Claude 3 (Sonnet) is more value for money.
 Pictures
Pictures
The large-scale model arena is released, and the "New King" ranks third
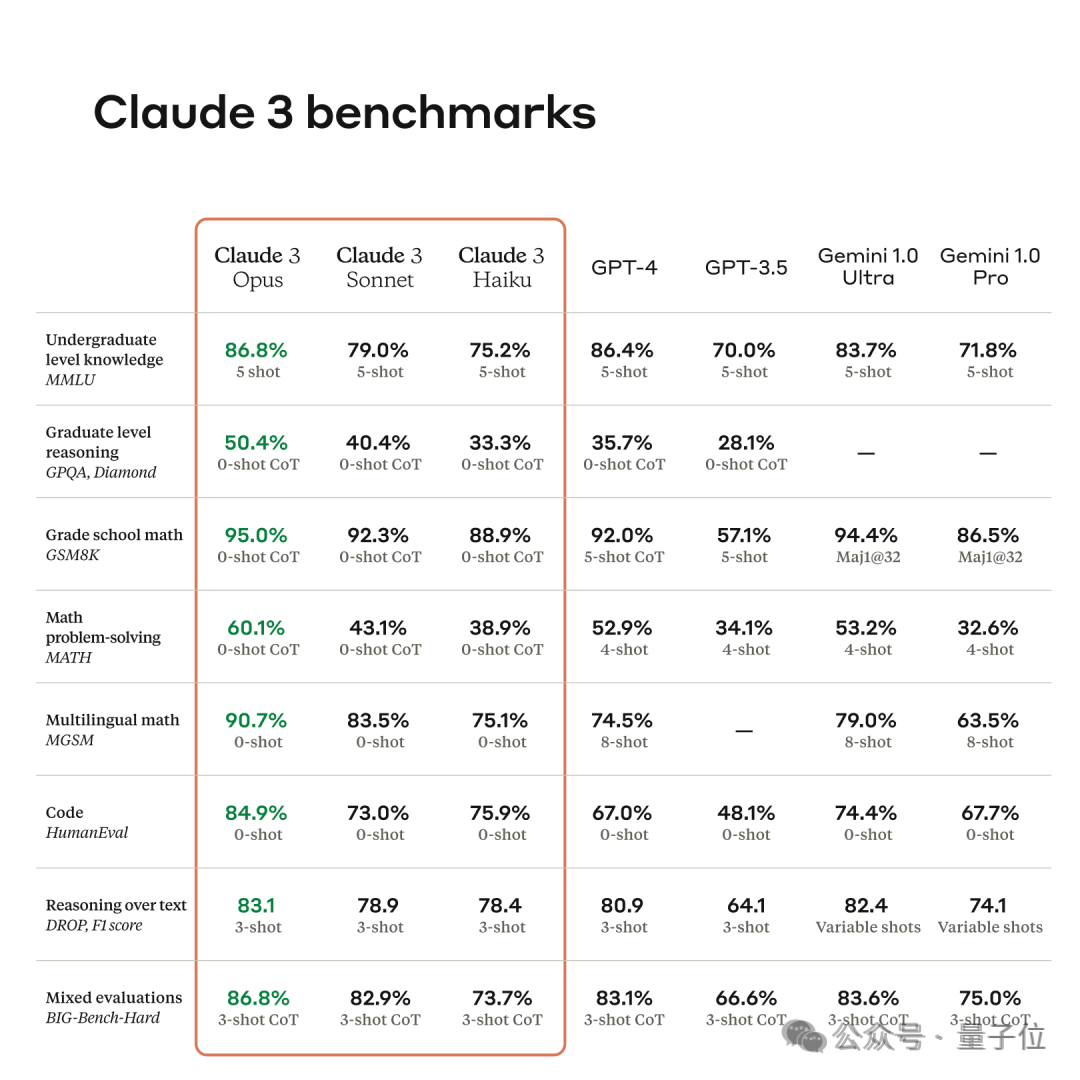
The official promotion when Claude 3 was released was comprehensive It exceeds GPT-4, but it does not mention which version of GPT-4 it is.
 Picture
Picture
The latest update of the Arena Leaderboard (LMSYS Chatbot Arena Leaderboard) helps us find out.
Let’s see the details.
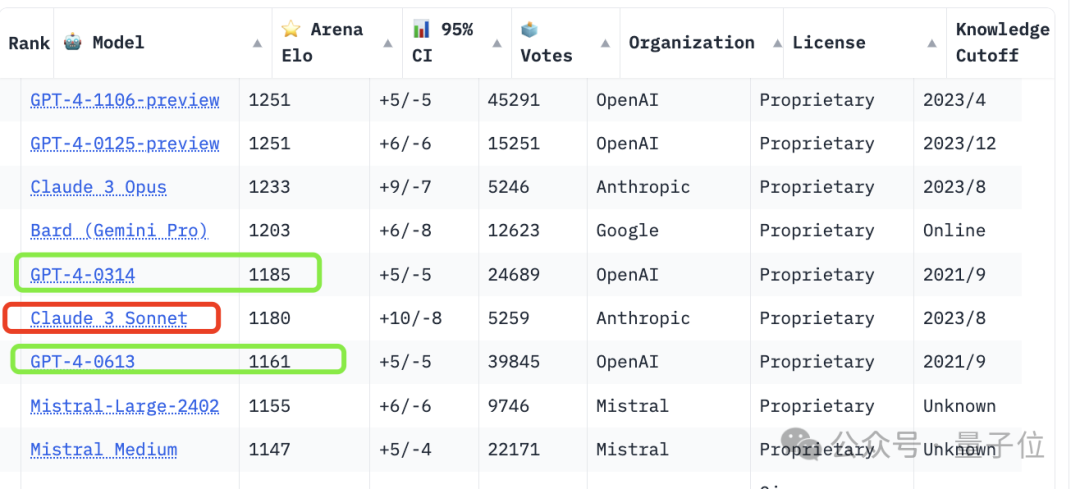
Ranked first is GPT-4 Turbo launched by OpenAI in November last year, which is:
GPT-4-1106-preview.
It is more powerful and cheaper, has 128k context, and the training data has been updated from September 2021 to April 2023.
Tie with it for first place is the latest version of GPT-4 Turbo, released in January this year:
GPT-4-0125-preview.
Its training data is wider, extending to December 2023.
Both achieved a score of 1251.
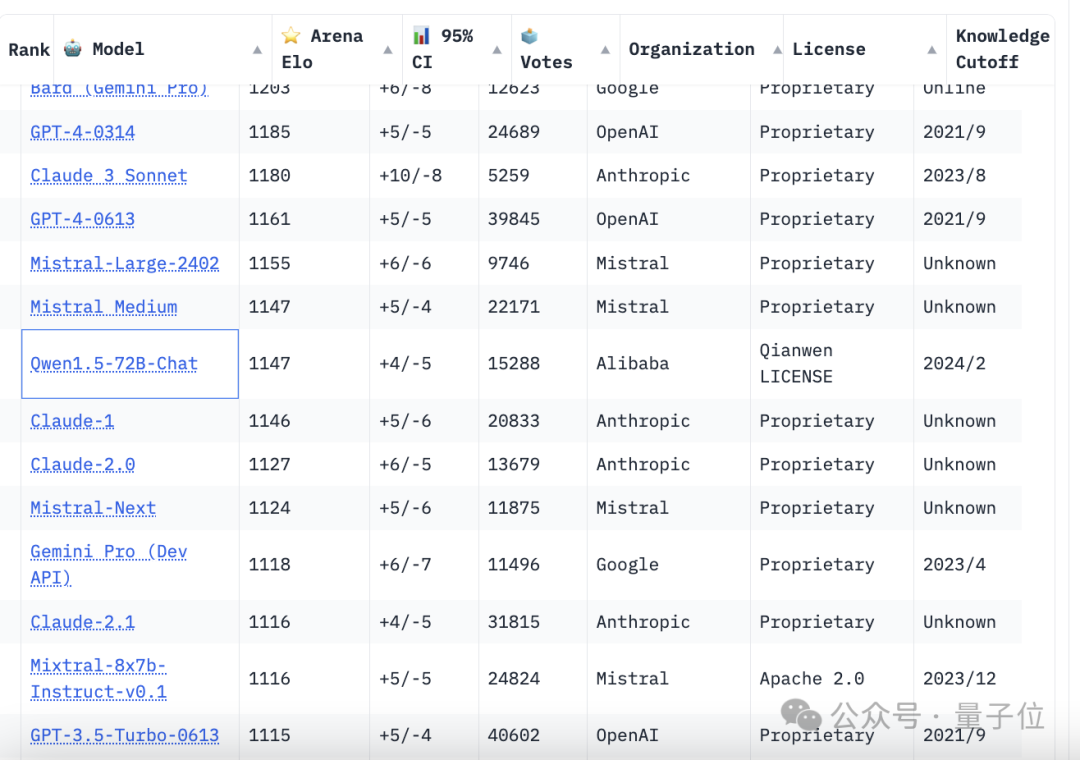
Then comes Claude 3 (training data ends in August 2023).
Its strongest version, Opus, scored 1233, 18 points lower than GPT-4 Turbo.
 Picture
Picture
This gap is not too big in comparison. After all, look further down:
It is better than GPT-4 The two versions (0314, 0613) are 48 points and 72 points higher respectively.
As for the medium-performance Claude 3 Sonnet, it ranks 6th, between the two GPT-4 versions:
However, it is only 5 points lower than the 0314 version, and has great potential to surpass it in one fell swoop. .
 Picture
Picture
So in general, there is nothing wrong with what the official publicity says. It surpasses the old version of GPT-4 in all aspects, but is far from GPT-4. Turbo is still a little far away, although not too much.
——Judging from the evaluation mechanism of this list, its results are quite recognized by the industry.
It is initiated by the author team of "Vicuna".
But the magistrate is not a "little alpaca", let alone GPT-4, but is based on human preferences.
In detail, we randomly ask any questions to two anonymous models, then evaluate their respective answers and vote for the better one.
 Picture
Picture
If we can’t vote in one round, we can choose to continue asking questions. If a model accidentally reveals their identity during the chat, the vote will be void.
Specially, the scoring rules adopt the Elo mechanism to ensure fairness (all friends who play Honor of Kings are familiar with it).
For example: If a certain model loses, its score is not necessarily low because it is weak. This is expected.
As of now, this list can be said to be very popular. 73 models from around the world have participated in the challenge, and a total of 370,000 votes have been received from netizens.
Tongyi Qianwen squeezed into the top 10
In addition to Claude 3, let’s take a look at other players who performed well.
The first thing to mention is Bard based on Gemini Pro, which ranks fourth, second only to GPT-4Turbo and Claude 3.
 Picture
Picture
It can be said to be a bit surprising.
Netizens joked:
Google has opened a "hole" in the rankings.
And hurriedly responded to JeffDean and the person in charge of DeepMind: Hey, work harder (Wangchai)
 Picture
Picture
The next thing I want to talk about is Ali Tongyi Qianwen (version 1.5, released last month).
It squeezed into the top ten and tied for ninth in this ranking, and is the best performer among domestic players.
 Picture
Picture
Left behind by it are, in addition to other domestic players, Claude 2, Gemini Pro, GPT-3.5, etc.
Complete list: https://www.php.cn/link/e39505ef839c38f61139ae78da3f7615
Reference link: https://www.php.cn/link/ 30637ce29549ac951061fd211d43c3b0
The above is the detailed content of The GPT-4 crown is gone! Claude 3 arena human voting results are released: only ranked third. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- OpenAI releases GPT-4, which has stronger question-solving ability. It also accepts image input, making it easy to understand memes!
- King of Glory rank ranking refresh (King of Glory rank ranking refresh mechanism)
- Recommended order of Wang Zhaojun's six divine outfits in 2024 'Glory of the King' to help you become the strongest king
- Glory of Kings Amber Era Parallel World Series skin purchase cost
- The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.