

 Technology peripheralsAIOccFusion: A simple and effective multi-sensor fusion framework for Occ (Performance SOTA)
Technology peripheralsAIOccFusion: A simple and effective multi-sensor fusion framework for Occ (Performance SOTA)OccFusion: A simple and effective multi-sensor fusion framework for Occ (Performance SOTA)

A comprehensive understanding of 3D scenes is crucial in autonomous driving, and recent 3D semantic occupancy prediction models have successfully addressed the challenge of describing real-world objects with different shapes and categories. However, existing 3D occupancy prediction methods rely heavily on panoramic camera images, which makes them susceptible to changes in lighting and weather conditions. By integrating the capabilities of additional sensors such as lidar and surround-view radar, our framework improves the accuracy and robustness of occupancy prediction, resulting in top performance on the nuScenes benchmark. Furthermore, extensive experiments on the nuScene dataset, including challenging nighttime and rainy scenes, confirm the superior performance of our sensor fusion strategy across various sensing ranges.
Paper link: https://arxiv.org/pdf/2403.01644.pdf
Paper name: OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
The main contributions of this paper are summarized as follows:
- A multi-sensor fusion framework is proposed to integrate camera, lidar and radar information to perform 3D semantic occupancy prediction tasks.
- In the 3D semantic occupancy prediction task, our method is compared with other state-of-the-art (SOTA) algorithms to demonstrate the advantages of multi-sensor fusion.
- Thorough ablation studies were conducted to evaluate the performance gains achieved by different sensor combinations under challenging lighting and weather conditions, such as night and rain.
- Considering various sensor combinations and challenging scenarios, a comprehensive study was conducted to analyze the impact of perceptual range factors on the performance of our framework in the 3D semantic occupancy prediction task!
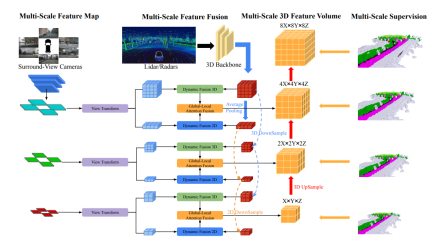
Network structure overview
The overall architecture of OccFusion is as follows. First, surround view images are input into a 2D backbone to extract multi-scale features. Subsequently, view transformation is performed at each scale to obtain global BEV features and local 3D feature volume at each level. The 3D point clouds generated by lidar and surround radar are also input into the 3D backbone to generate multi-scale local 3D feature quantities and global BEV features. Dynamic fusion 3D/2D modules at each level combine the capabilities of cameras and lidar/radar. After this, the merged global BEV features and local 3D feature volume at each level are fed into the global-local attention fusion to generate the final 3D volume at each scale. Finally, the 3D volume at each level is upsampled and skip-connected with a multi-scale supervision mechanism.
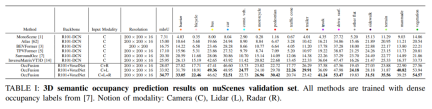
Experimental comparative analysis
On the nuScenes validation set, various methods based on dense occupancy label training are demonstrated in 3D semantics Results in occupancy forecasts. These methods involve different modal concepts including camera (C), lidar (L) and radar (R).
On the rainy scene subset of the nuScenes dataset, we predict 3D semantic occupancy and use dense occupancy labels for training. In this experiment, we considered data from different modalities such as camera (C), lidar (L), radar (R), etc. The fusion of these modes can help us better understand and predict rainy scenes, providing an important reference for the development of autonomous driving systems.
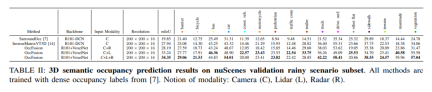
#nuScenes validates 3D semantic occupancy prediction results for a subset of nighttime scenes. All methods are trained using dense occupancy labels. Modal concepts: camera (C), lidar (L), radar (R).

Performance change trend. (a) Performance change trend of the entire nuScenes validation set, (b) nuScenes validation night scene subset, and (c) nuScene validation performance change trend of the rainy scene subset.
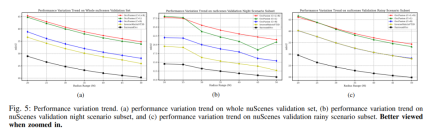
Table 4: Comparison of model efficiency of different methods. Experiments were conducted on an A10 using six multi-camera images, lidar and radar data. For input image resolution, 1600×900 is used for all methods. ↓:The lower the better.

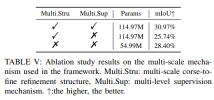
More ablation experiments:


The above is the detailed content of OccFusion: A simple and effective multi-sensor fusion framework for Occ (Performance SOTA). For more information, please follow other related articles on the PHP Chinese website!

 Tool Calling in LLMsApr 14, 2025 am 11:28 AM
Tool Calling in LLMsApr 14, 2025 am 11:28 AMLarge language models (LLMs) have surged in popularity, with the tool-calling feature dramatically expanding their capabilities beyond simple text generation. Now, LLMs can handle complex automation tasks such as dynamic UI creation and autonomous a
 How ADHD Games, Health Tools & AI Chatbots Are Transforming Global HealthApr 14, 2025 am 11:27 AM
How ADHD Games, Health Tools & AI Chatbots Are Transforming Global HealthApr 14, 2025 am 11:27 AMCan a video game ease anxiety, build focus, or support a child with ADHD? As healthcare challenges surge globally — especially among youth — innovators are turning to an unlikely tool: video games. Now one of the world’s largest entertainment indus
 UN Input On AI: Winners, Losers, And OpportunitiesApr 14, 2025 am 11:25 AM
UN Input On AI: Winners, Losers, And OpportunitiesApr 14, 2025 am 11:25 AM“History has shown that while technological progress drives economic growth, it does not on its own ensure equitable income distribution or promote inclusive human development,” writes Rebeca Grynspan, Secretary-General of UNCTAD, in the preamble.
 Learning Negotiation Skills Via Generative AIApr 14, 2025 am 11:23 AM
Learning Negotiation Skills Via Generative AIApr 14, 2025 am 11:23 AMEasy-peasy, use generative AI as your negotiation tutor and sparring partner. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining
 TED Reveals From OpenAI, Google, Meta Heads To Court, Selfie With MyselfApr 14, 2025 am 11:22 AM
TED Reveals From OpenAI, Google, Meta Heads To Court, Selfie With MyselfApr 14, 2025 am 11:22 AMThe TED2025 Conference, held in Vancouver, wrapped its 36th edition yesterday, April 11. It featured 80 speakers from more than 60 countries, including Sam Altman, Eric Schmidt, and Palmer Luckey. TED’s theme, “humanity reimagined,” was tailor made
 Joseph Stiglitz Warns Of The Looming Inequality Amid AI Monopoly PowerApr 14, 2025 am 11:21 AM
Joseph Stiglitz Warns Of The Looming Inequality Amid AI Monopoly PowerApr 14, 2025 am 11:21 AMJoseph Stiglitz is renowned economist and recipient of the Nobel Prize in Economics in 2001. Stiglitz posits that AI can worsen existing inequalities and consolidated power in the hands of a few dominant corporations, ultimately undermining economic
 What is Graph Database?Apr 14, 2025 am 11:19 AM
What is Graph Database?Apr 14, 2025 am 11:19 AMGraph Databases: Revolutionizing Data Management Through Relationships As data expands and its characteristics evolve across various fields, graph databases are emerging as transformative solutions for managing interconnected data. Unlike traditional
 LLM Routing: Strategies, Techniques, and Python ImplementationApr 14, 2025 am 11:14 AM
LLM Routing: Strategies, Techniques, and Python ImplementationApr 14, 2025 am 11:14 AMLarge Language Model (LLM) Routing: Optimizing Performance Through Intelligent Task Distribution The rapidly evolving landscape of LLMs presents a diverse range of models, each with unique strengths and weaknesses. Some excel at creative content gen


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver CS6
Visual web development tools

