
Home >Technology peripherals >AI >3D reconstruction of two pictures in 2 seconds! This AI tool is popular on GitHub, netizens: Forget about Sora
3D reconstruction of two pictures in 2 seconds! This AI tool is popular on GitHub, netizens: Forget about Sora

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-03-07 08:40:02967browse
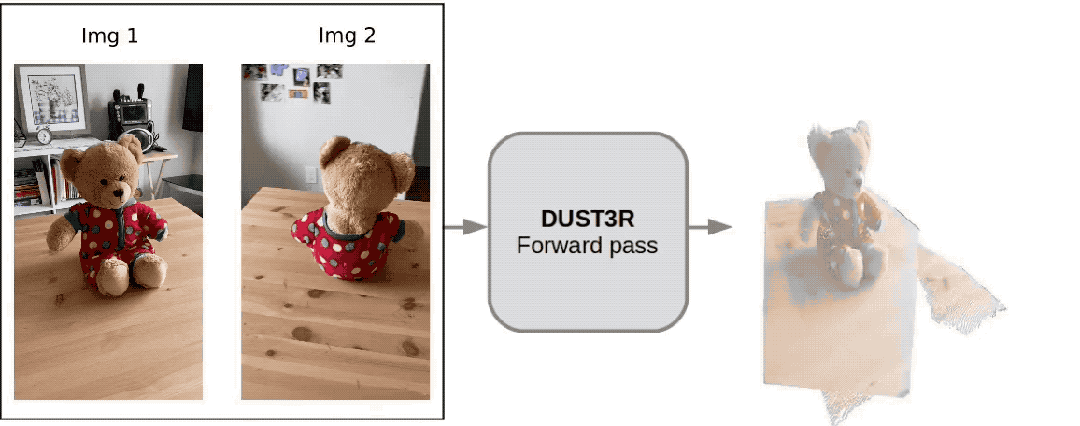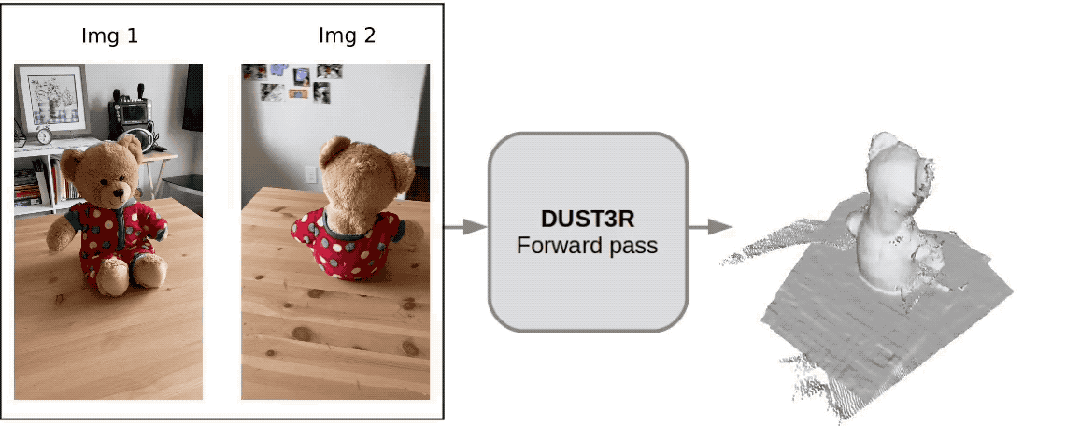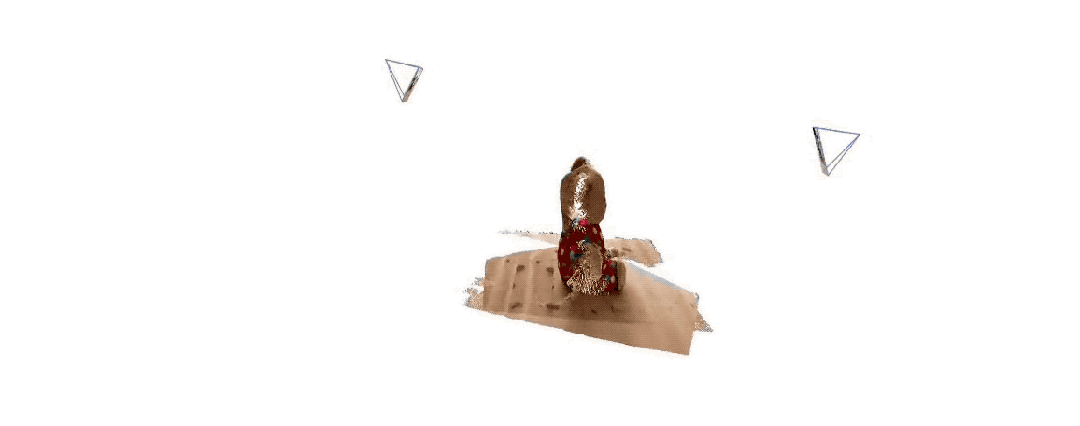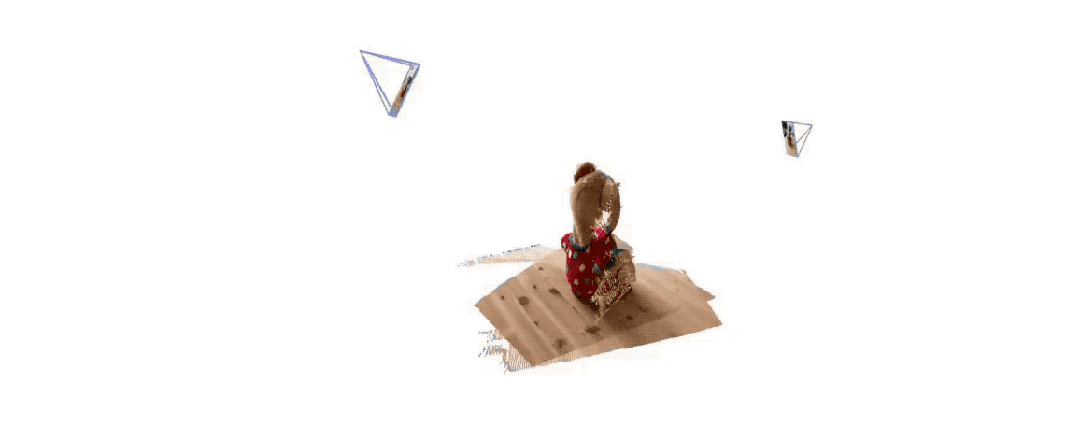
Only 2 pictures, no need to measure any additional data——
Dangdang, a complete 3D bear is there:
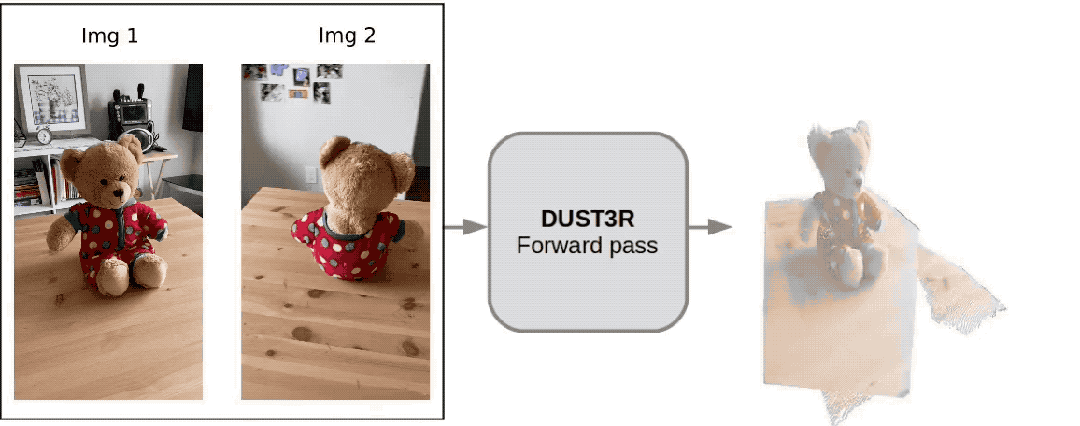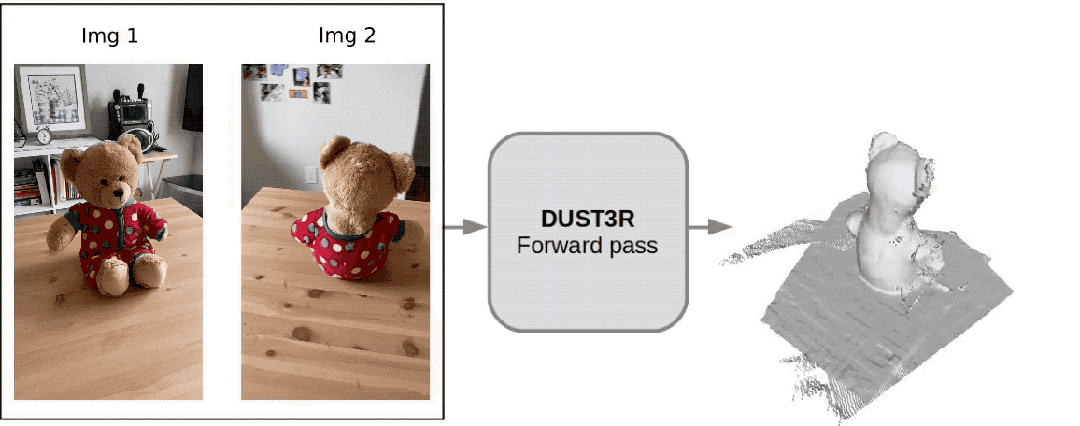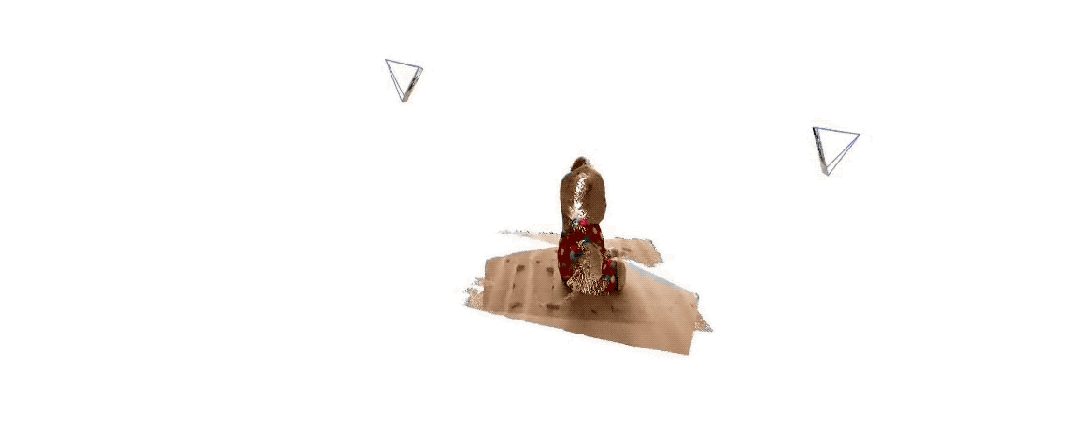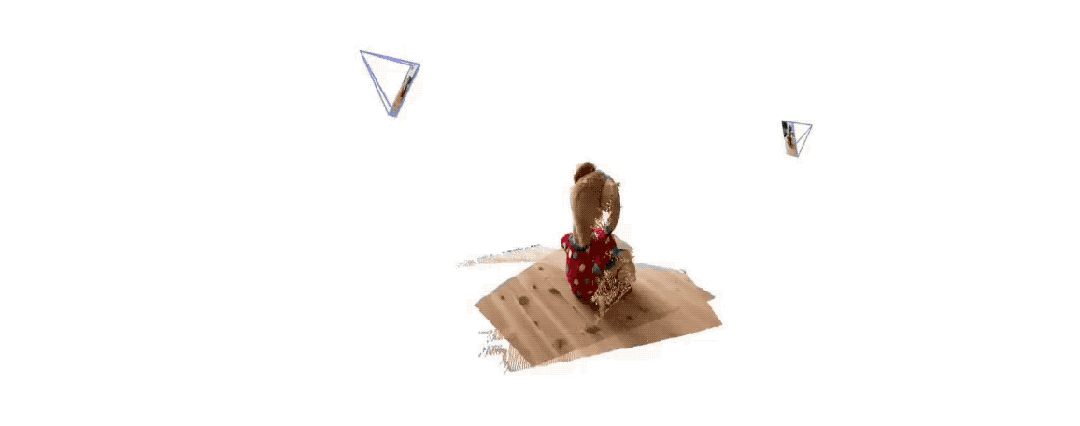
This new tool called DUSt3R is so popular that it ranked second on the GitHub Hot List not long after it was launched. ##.
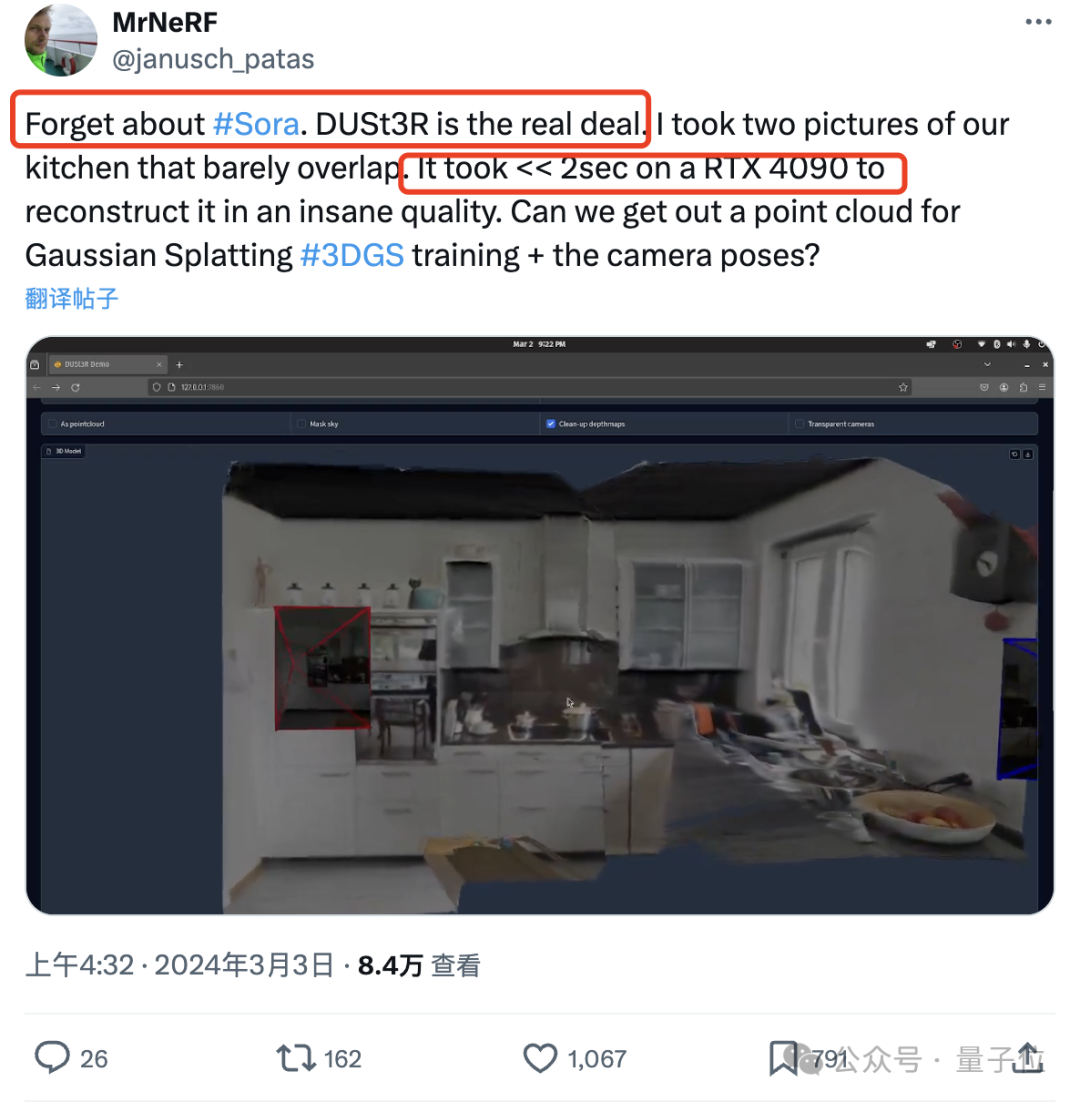
Netizen actually tested, took two photos, and really reconstructed his kitchen, the whole processIt takes less than 2 seconds!
(In addition to 3D images, it can also provide depth maps, confidence maps and point cloud images)
EveryoneForget about sora first, this is what we can really see and touch.
(from the European branch of NAVER LABS Institute of Artificial Intelligence, Aalto University, Finland) ’s “manifesto” is also full of momentum:
We It is to make the world have no difficult 3D visual tasks.So, how is it done? “all-in-one”For the multi-view stereo reconstruction
(MVS) task, the first step is to estimate the camera parameters, including internal and external parameters.
This operation is boring and troublesome, but it is indispensable for subsequent triangulation of pixels in three-dimensional space, and this is an inseparable part of almost all MVS algorithms with better performance. In the study of this article, the DUSt3R introduced by the author's team adopted a completely different approach. Itdoes not require any prior information about camera calibration or viewpoint pose, and can complete dense or unconstrained 3D reconstruction of arbitrary images.
Here, the team formulates the pairwise reconstruction problem as point-plot regression, unifying the monocular and binocular reconstruction situations. When more than two input images are provided, all pairs of point images are represented into a common reference frame through a simple and effective global alignment strategy. As shown in the figure below, given a set of photos with unknown camera poses and intrinsic features, DUSt3R outputs a corresponding set of point maps, from which we can directly recover various geometric quantities that are usually difficult to estimate simultaneously. Such as camera parameters, pixel correspondence, depth map, and completely consistent 3D reconstruction effect.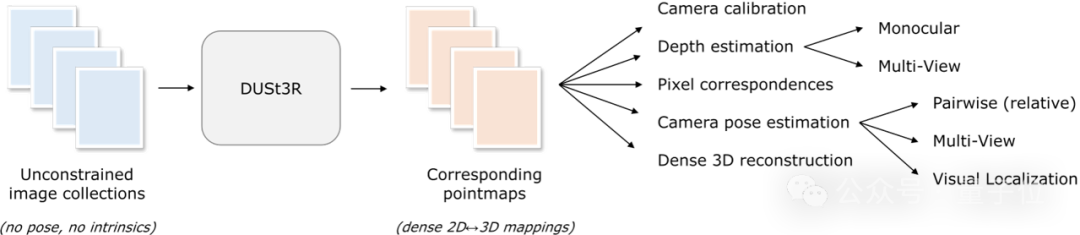
(The author reminds that DUSt3R is also applicable to a single input image)
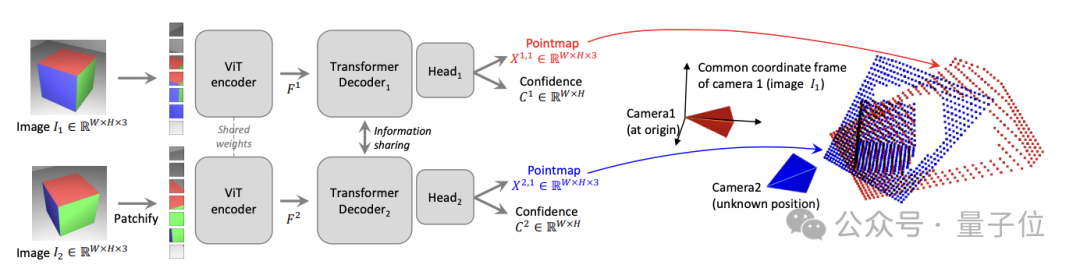
In terms of specific network architecture, DUSt3R is based onStandard Transformer encoder and decoder, inspired by CroCo (a study on self-supervised pre-training of 3D vision tasks across views), and adopted Simple regression loss training is completed.
As shown in the figure below, the two views of the scene(I1, I2) are first encoded in Siamese (Siamese) mode using the shared ViT encoder.
The resulting token representation(F1 and F2) is then passed to two Transformer decoders, which pass the cross attention Information is constantly exchanged.
Многозадачность SOTA
В ходе эксперимента сначала оценивается DUST3R на 7 сценах (7 сцен в помещении) и Cambridge Landmarks (8 сцен на открытом воздухе) Наборы данных Производительность на Задача абсолютной оценки позы, индикаторами являются ошибка перевода и ошибка вращения (чем меньше значение, тем лучше) .
Автор заявил, что по сравнению с другими существующими методами сопоставления функций и сквозными методами производительность DUSt3R замечательна.
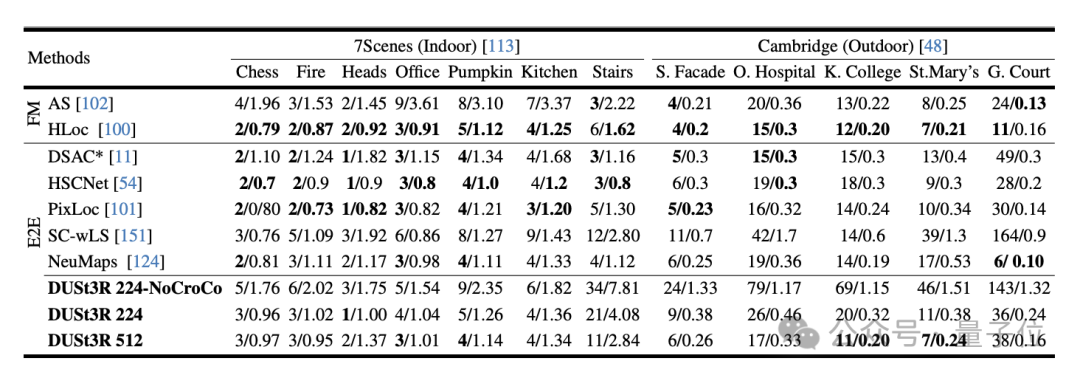
Потому что он никогда не проходил никакого обучения визуальному позиционированию, и, во-вторых, он не сталкивался с изображениями запросов и изображениями базы данных в процессе обучения.
Во-вторых, это задача регрессии позы с несколькими изображениями, выполняемая на 10 случайных кадрах. Результаты. DUST3R добился лучших результатов на обоих наборах данных.
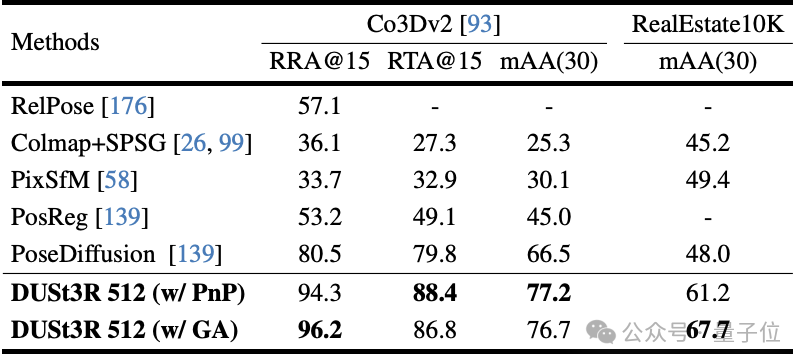
В задаче монокулярной оценки глубины DUSt3R также может хорошо обрабатывать сцены в помещении и на открытом воздухе, с производительностью лучше, чем у базовых линий с самоконтролем, и отличается от самых продвинутых базовых линий с контролируемым контролем. . Вверх и вниз.
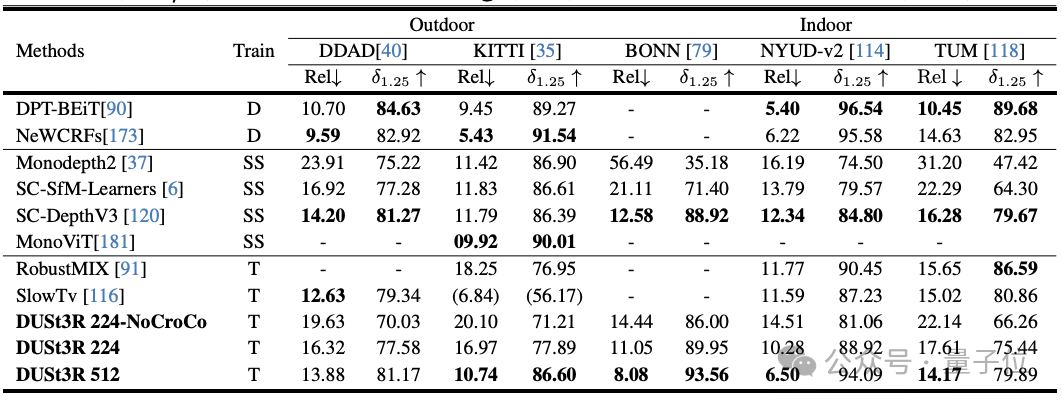
С точки зрения оценки глубины в нескольких ракурсах производительность DUSt3R также выдающаяся.
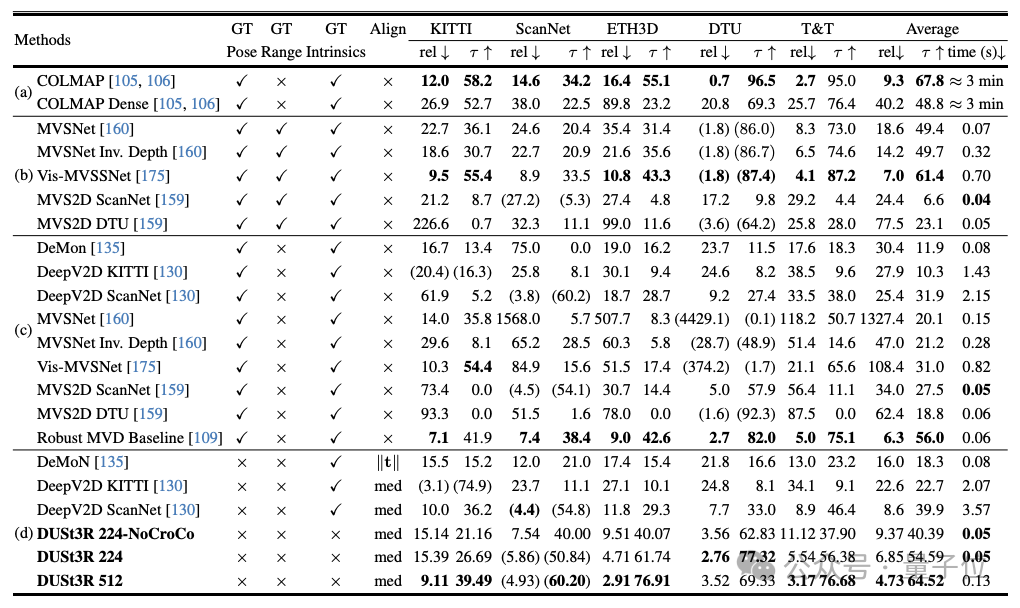
Ниже приведены эффекты 3D-реконструкции, предоставленные двумя группами чиновников. Чтобы вы почувствовали, они ввели только два изображения:
(1 )

(2)

Реальные измерения пользователей сети: ничего страшного, если два изображения не перекрываются
Да Пользователь сети предоставил DUST3R два изображения без перекрывающегося содержимого, а также за несколько секунд выдал точное 3D-изображение:



##В ответ некоторые пользователи сети сказали, что это означает, что метода нет. Делайте «объективные измерения» и вместо этого ведите себя как ИИ.
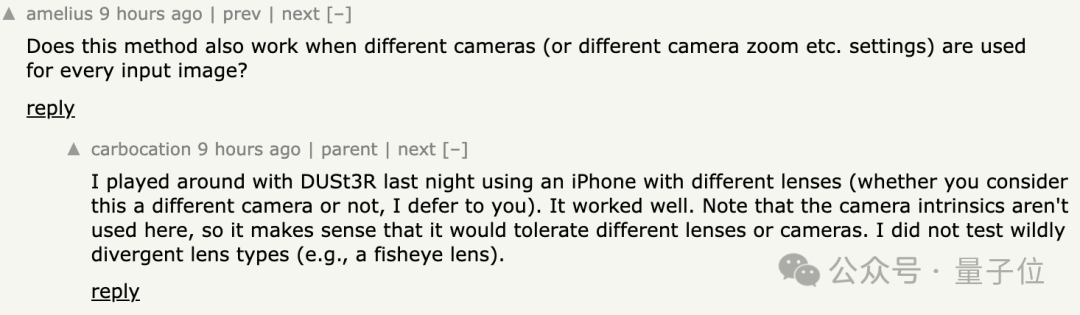 Кроме того, некоторым людям интересно
Кроме того, некоторым людям интересно
? Некоторые пользователи сети действительно попробовали это, и ответ
да!
## Портал:
The above is the detailed content of 3D reconstruction of two pictures in 2 seconds! This AI tool is popular on GitHub, netizens: Forget about Sora. For more information, please follow other related articles on the PHP Chinese website!