
 Technology peripheralsAIGoogle releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA
Technology peripheralsAIGoogle releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA
The big model that everyone wants is the kind that is truly intelligent...
The Google team will make it Developed a powerful "screen reading" AI.
The researchers call it ScreenAI, a new visual language model for understanding user interfaces and infographics.

Paper address: https://arxiv.org/pdf/2402.04615.pdf
ScreenAI At its core is a new screenshot text representation method that recognizes the type and position of UI elements.
The researchers used the Google language model PaLM 2-S to generate synthetic training data, which was used to train the model to answer questions related to screen information, screen navigation, and screen content summaries. question. It is worth mentioning that this method provides new ideas for improving the performance of the model when handling screen-related tasks.

For example, if you open a music APP page, you can ask "How many songs are less than 30 seconds long?"
ScreenAI gave a simple answer: 1.

Another example is to command ScreenAI to open the menu and you can select it.

Source of architectural inspiration - PaLI
Figure 1 shows the ScreenAI model architecture. The researchers were inspired by the architecture of the PaLI family of models, which consists of a multimodal encoder block.
The encoder block contains a ViT-like visual encoder and an mT5 language encoder consuming image and text input, followed by an autoregressive decoder.
The input image is converted by the visual encoder into a series of embeddings, which are combined with the input text embedding and fed into the mT5 language encoder.
The output of the encoder is passed to the decoder, which produces text output.
This generalized formulation can use the same model architecture to solve various visual and multi-modal tasks. These tasks can be reformulated as text-image (input) to text (output) problems.
Compared to text input, image embeddings form a significant part of the input length to multi-modal encoders.
In short, this model uses an image encoder and a language encoder to extract image and text features, fuse the two and then input them into the decoder to generate text.
This construction method can be widely applied to multi-modal tasks such as image understanding.
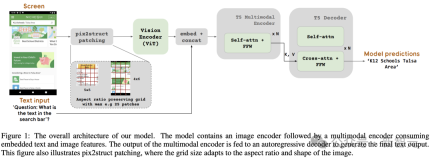
In addition, the researchers further extended PaLI’s encoder-decoder architecture to accept various image blocking modes.
The original PaLI architecture only accepts image patches in a fixed grid pattern to process input images. However, researchers in the screen-related field encounter data that spans a wide variety of resolutions and aspect ratios.
In order for a single model to adapt to all screen shapes, it is necessary to use a tiling strategy that works for images of various shapes.
To this end, the Google team borrowed a technology introduced in Pix2Struct, which allows the generation of arbitrary grid-shaped image blocks based on the input image shape and a predefined maximum number of blocks, such as As shown in Figure 1.
This is able to adapt to input images of various formats and aspect ratios without padding or stretching the image to fix its shape, making the model more versatile and able to handle movement simultaneously Image formats for device (i.e. portrait) and desktop (i.e. landscape).
Model configuration
The researchers trained 3 models of different sizes, containing 670M, 2B and 5B parameters.
For the 670M and 2B parameter models, the researchers started with pre-trained unimodal checkpoints for the visual encoder and encoder-decoder language model.
For the 5B parameter model, start from the multi-modal pre-training checkpoint of PaLI-3, where ViT is trained with a UL2-based encoder-decoder language model.
The parameter distribution between the visual and language models can be seen in Table 1.

Automatic data generation
Researchers say that pre-production of model development The training phase largely depends on access to large and diverse data sets.
However, manually labeling extensive data sets is impractical, so the Google team’s strategy is to automatically generate data.
This approach leverages specialized small models, each of which is good at generating and labeling data efficiently and with high accuracy.
Compared to manual annotation, this automated approach is not only efficient and scalable, but also ensures a certain level of data diversity and complexity.
The first step is to give the model a comprehensive understanding of text elements, various screen components, and their overall structure and hierarchy. This fundamental understanding is critical to the model's ability to accurately interpret and interact with a variety of user interfaces.
Here, researchers collected a large number of screenshots from a variety of devices, including desktops, mobile devices, and tablets, by crawling applications and web pages.
These screenshots are then annotated with detailed tags that describe the UI elements, their spatial relationships, and other descriptive information.
In addition, to inject greater diversity into the pre-training data, the researchers also leveraged the power of language models, specifically PaLM 2-S, to generate QA pairs in two stages.
Start by generating the screen mode described previously. The authors then design a prompt containing screen patterns to guide the language model to generate synthetic data.
After a few iterations, a tip can be identified that effectively generates the required tasks, as shown in Appendix C.

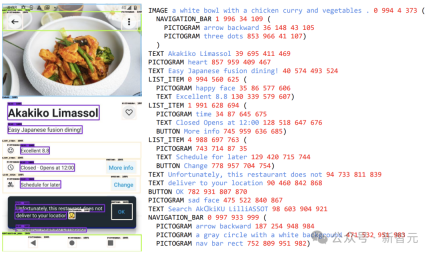
#To assess the quality of these generated responses, the researchers performed manual verification on a subset of the data , to ensure that the predetermined quality requirements are met.
This method is described in Figure 2, which greatly improves the depth and breadth of the pre-training data set.
By leveraging the natural language processing capabilities of these models, combined with structured screen patterns, various user interactions and scenarios can be simulated.

Two sets of different tasks
Next, the researchers defined two different sets of tasks for the model Tasks: an initial set of pre-training tasks and a subsequent set of fine-tuning tasks.
The difference between these two groups mainly lies in two aspects:
- Source of real data: For fine-tuning tasks, labels are evaluated by human evaluators Provide or verify. For pre-training tasks, labels are inferred using self-supervised learning methods or generated using other models.
- Size of the dataset: Usually pre-training tasks contain a large number of samples, therefore, these tasks are used to train the model through a more extended series of steps.
Table 2 shows a summary of all pre-training tasks.
In mixed data, the dataset is weighted proportionally to its size, with the maximum weight allowed for each task.

Incorporate multi-modal sources into multi-task training, from language processing to visual understanding and web page content analysis, enabling the model to effectively handle different scenarios and enhancing its overall Versatility and performance.

Researchers use various tasks and benchmarks to estimate the quality of the model during fine-tuning. Table 3 summarizes these benchmarks, including existing primary screen, infographic, and document comprehension benchmarks.

Experimental results
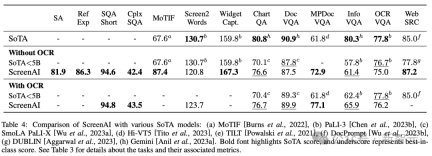
Figure 4 shows the performance of the ScreenAI model and compares it with various The latest SOT results on screen and infographic related tasks are compared.
You can see that ScreenAI has achieved leading performance on different tasks.
In Table 4, the researchers present the results of single-task fine-tuning using OCR data.
For QA tasks, adding OCR can improve performance (e.g. up to 4.5% on Complex ScreenQA, MPDocVQA and InfoVQA).
However, using OCR slightly increases the input length, resulting in slower overall training. It also requires obtaining OCR results at inference time.
Additionally, the researchers conducted single-task experiments using the following model sizes: 670 million parameters, 2 billion parameters, and 5 billion parameters.
It can be observed in Figure 4 that for all tasks, increasing the model size improves performance, and the improvement at the largest scale has not yet saturated.
For tasks requiring more complex visual text and arithmetic reasoning (such as InfoVQA, ChartQA, and Complex ScreenQA), the improvement between the 2 billion parameter model and the 5 billion parameter model is significantly greater than 6.7 100 million parameter model and 2 billion parameter model.

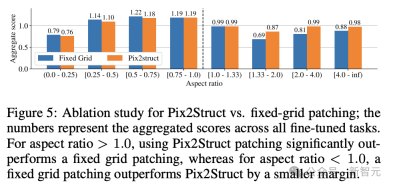
Finally, Figure 5 shows that for images with aspect ratio >1.0 (landscape mode images), the pix2struct segmentation strategy is significantly better than fixed Grid segmentation.
For portrait mode images, the trend is opposite, but fixed grid segmentation is only slightly better.
Given that the researchers wanted the ScreenAI model to work on images with different aspect ratios, they chose to use the pix2struct segmentation strategy.
Google researchers said the ScreenAI model also needs more research on some tasks to scale down to larger models such as GPT-4 and Gemini. model gap.
The above is the detailed content of Google releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

