

 Technology peripheralsAIThe Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Technology peripheralsAIThe Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?

The paper for Stable Diffusion 3 is finally here!
This model was released two weeks ago and uses the same DiT (Diffusion Transformer) architecture as Sora. It caused quite a stir upon release.
Compared with the previous version, the quality of images generated by Stable Diffusion 3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. Condition.
Stability AI pointed out that Stable Diffusion 3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly lowering the threshold for using large AI models.
In a newly released paper, Stability AI said that in human preference-based evaluations, Stable Diffusion 3 outperformed current state-of-the-art text-to-image generation systems such as DALL・E 3. Midjourney v6 and Ideogram v1. Soon, they will make the experimental data, code, and model weights of the study publicly available.

In the paper, Stability AI revealed more details about Stable Diffusion 3.

- ##Paper title: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- Paper link: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf
Architectural details
For text-to-image generation, the Stable Diffusion 3 model must consider both text and image modes. Therefore, the authors of the paper call this new architecture MMDiT, referring to its ability to handle multiple modalities. As with previous versions of Stable Diffusion, the authors use pre-trained models to derive suitable text and image representations. Specifically, they used three different text embedding models—two CLIP models and T5—to encode text representations, and an improved autoencoding model to encode image tokens.
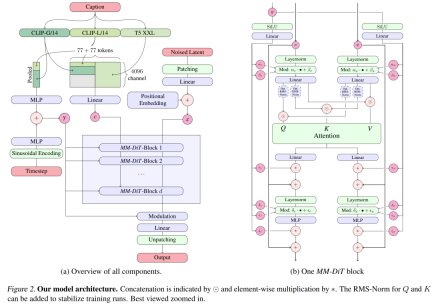
Stable Diffusion 3 model architecture.
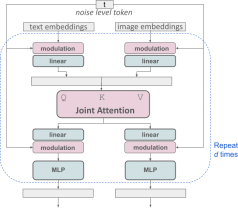
Improved multimodal diffusion transformer: MMDiT block.
The SD3 architecture is based on DiT proposed by Sora core R&D member William Peebles and Xie Saining, assistant professor of computer science at New York University. Since text embedding and image embedding are conceptually very different, the authors of SD3 use two different sets of weights for the two modalities. As shown in the figure above, this is equivalent to setting up two independent transformers for each modality, but combining the sequences of the two modalities for attention operations, so that both representations can work in their own space, Another representation is also taken into account.
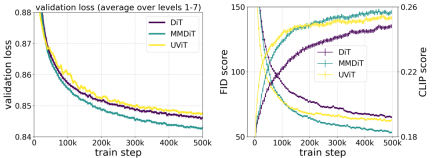
The author's proposed MMDiT architecture outperforms mature textual frameworks such as UViT and DiT when measuring visual fidelity and text alignment during training. to the image backbone.
In this way, information can flow between image and text tokens, thereby improving the overall understanding of the model and improving the typography of the generated output. As discussed in the paper, this architecture is also easily extensible to multiple modalities such as video.

Thanks to Stable Diffusion 3’s improved prompt following capabilities, the new model has the ability to produce images that focus on a variety of different themes and qualities, At the same time, it can also handle the style of the image itself with a high degree of flexibility.

Improve Rectified Flow through re-weighting
Stable Diffusion 3 uses the Rectified Flow (RF) formula. During the training process, Data and noise are connected in a linear trajectory. This makes the inference path straighter, thus reducing sampling steps. In addition, the authors also introduce a new trajectory sampling scheme during the training process. They hypothesized that the middle part of the trajectory would pose a more challenging prediction task, so the scheme gave more weight to the middle part of the trajectory. They compared using multiple datasets, metrics and sampler settings and tested their proposed method against 60 other diffusion trajectories such as LDM, EDM and ADM. The results show that while the performance of previous RF formulations improves with few sampling steps, their relative performance decreases as the number of steps increases. In contrast, the reweighted RF variant proposed by the authors consistently improves performance.
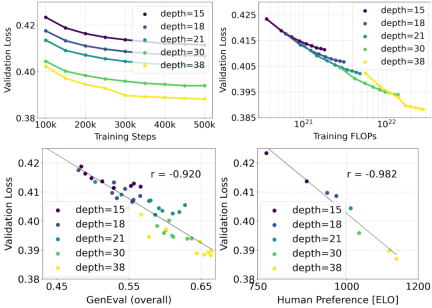
Extended Rectified Flow Transformer model
The author uses the reweighted Rectified Flow formula and MMDiT backbone pair Text-to-image synthesis is studied in scaling. They trained models ranging from 15 blocks with 450M parameters to 38 blocks with 8B parameters and observed that the validation loss decreased smoothly with increasing model size and training steps (first part of the figure above OK). To examine whether this translated into meaningful improvements in model output, the authors also evaluated the automatic image alignment metric (GenEval) and the human preference score (ELO) (second row above). The results show a strong correlation between these metrics and validation loss, suggesting that the latter is a good predictor of the overall performance of the model. Furthermore, the scaling trend shows no signs of saturation, making the authors optimistic about continuing to improve model performance in the future.
Flexible text encoder
By removing memory intensive 4.7B parameter T5 text encoder for inference, SD3 memory Demand can be significantly reduced with minimal performance loss. As shown, removing this text encoder has no impact on visual aesthetics (50% win rate without T5) and only slightly reduces text consistency (46% win rate). However, the authors recommend adding T5 when generating written text to fully utilize the performance of SD3, because they observed that without adding T5, the performance of generating typesetting dropped even more (win rate 38%), as shown in the following figure:

#Removing T5 for inference will only result in a significant decrease in performance when presenting very complex prompts involving many details or large amounts of written text. The image above shows three random samples of each example.
Model performance
The author compared the output image of Stable Diffusion 3 with various other open source models (including SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 and Pixart-α) as well as closed-source models such as DALL-E 3, Midjourney v6 and Ideogram v1 were compared to evaluate performance based on human feedback. In these tests, human evaluators are given examples of output from each model and judged on how well the model output follows the context of the prompt given (prompt following), how well the text is rendered according to the prompt (typography), and which image Images with higher visual aesthetics are selected for the best results.
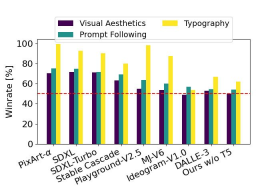
#Using SD3 as the benchmark, this chart outlines its win rate based on human evaluation of visual aesthetics, prompt following, and text layout.
From the test results, the author found that Stable Diffusion 3 is equivalent to or even better than the current state-of-the-art text-to-image generation systems in all the above aspects.
In early unoptimized inference testing on consumer hardware, the largest 8B parameter SD3 model fit the RTX 4090's 24GB VRAM, using 50 sampling steps to generate a resolution of 1024x1024 Image takes 34 seconds.

Additionally, at initial release, Stable Diffusion 3 will be available in multiple variants, ranging from 800m to 8B parametric models to further eliminate hardware barriers.


Please refer to the original paper for more details.
Reference link: https://stability.ai/news/stable-diffusion-3-research-paper
The above is the detailed content of The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

Notepad++7.3.1
Easy-to-use and free code editor

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

