

 Computer TutorialsComputer KnowledgeTrade-off analysis of modern distributed system architectures
Computer TutorialsComputer KnowledgeTrade-off analysis of modern distributed system architectures

Modern software systems, especially those following distributed architectures, are known for their complexity and variability. These systems are composed of many elements, each of which introduces potential trade-offs that can affect factors such as cost, performance, scalability, and reliability. Understanding these trade-offs is critical for IT architects, business analysts, data architects, software engineers, and data engineers navigating the world of software modernization and transformation. This article aims to shed light on the process and importance of conducting trade-off analysis in distributed architectures, providing insights into the methods, techniques, tools, and competing approaches associated with this complex but integral practice.
Software architecture has always been an area that requires trade-offs and decisions. In this precision- and innovation-driven field, every decision makes a difference. Recognizing the importance of these impacts is becoming increasingly critical because we are in an era of rapid technological advancement. In this era, every decision is an opportunity and a challenge.
In the dynamic picture of the technological landscape, there is an interesting evolution story: from the single behemoth of the past to the flexible distributed system of today. As we stand at the intersection of unprecedented flexibility and growing complexity, one thing has become abundantly clear—decisions matter. And what about making those decisions? Well, it's a blend of art, science, and a little bit of divination.
Understand the modern distributed systems landscape
- Evolutionary Leap: Gone are the days when entire applications resided on a single server or cluster. The rise of microservices, containerization (such as Docker), cloud computing giants such as AWS, Azure and GCP, and even the forefront of edge computing have fundamentally redefined software architecture. These innovations free applications and give them unparalleled scalability and resilience.
- Double-edged sword: Although distributed systems have many advantages, they also bring complex challenges. The autonomy of microservices, for example, also introduces potential synchronization, latency and communication barriers.
The need for modern trade-off analysis
- Historical Background: Just ten or twenty years ago, monolithic architecture was the standard. It was a simpler time and the challenges were straightforward. However, the digital revolution has introduced many new architectural patterns. From microservices to serverless computing, these patterns provide unprecedented flexibility and robustness, redefining the boundaries of what software can achieve.
- Complexity and Opportunities: As technology evolves, so does the complexity associated with it. Architects now must consider cloud-native approaches, container orchestration tools like Kubernetes, and the complexities of continuous integration and deployment. However, as these challenges arise, so do opportunities for innovation and optimization, making the architect's role more critical than ever.
Identifying trade-offs in modern software systems
Navigating the vast realm of modern software possibilities is akin to navigating an ocean of opportunities and pitfalls. As Spider-Man's Uncle Ben Parker wisely said, "With great power comes great responsibility." Distributed systems provide scalability, resilience, and flexibility. However, they also introduce challenges in data consistency, system orchestration, fault tolerance, etc. Decisions made in this area have far-reaching consequences.
- Microservices: They provide modularity, scalability, and the ability to deploy parts of an application independently. However, they also introduce challenges related to service discovery, inter-service communication, and data consistency.
- Serverless: Serverless architecture promises cost-effectiveness by removing the burden of infrastructure management and providing on-demand scalability. However, it may not be suitable for applications with specific performance requirements due to long startup times and potential vendor lock-in.
- Event-driven architecture: tends to asynchronous communication to enhance scalability, but requires a powerful mechanism to ensure data consistency.
- Cloud native: Designed to take full advantage of the benefits of cloud computing, cloud native architecture emphasizes scalability, resilience and flexibility. It typically uses containerization, microservices, and continuous delivery practices.
- Layered (or N-tier) architecture: Divide the system into different layers, such as presentation, business logic, and data access layers. Each layer has specific responsibilities and only interacts with its adjacent layers.
- Responsive Architecture: Build responsive, resilient, and message-driven systems. It is designed to handle the asynchronous nature of modern applications.
- Hexagons (or Ports and Adapters): Focus on separation of concerns by dividing the application into internal and external parts. This allows applications to be isolated from external technologies and tools.
2. Database type: Data is the lifeline of modern applications
- Relational database: Known for its structured schema and strong ACID guarantees, it performs well in situations where complex joins and transactions are required. However, their trade-offs may include potential scalability issues.
- NoSQL: Designed for flexibility, scalability, and high performance. However, consistency can sometimes be a challenge, especially in databases that prioritize availability over strict consistency.
- Vector database: Suitable for high-performance analysis, but may introduce data processing complexity.
- Graph database: Suitable for Internet data exploration, but may not be efficient enough for non-graph operations.
- Time Series Database: Optimized for processing timestamp data, especially suitable for monitoring, financial and IoT applications. Their trade-offs may include limited functionality for non-time series operations.
- In-Memory Database: Store data in your computer's main memory (RAM) for faster response times. They are used in applications where speed is critical.
- Object-oriented database: Stores data in the form of objects used in object-oriented programming.
- Distributed database: Distribute data across multiple servers and can scale in a single location or multiple locations.
- Hierarchical database: Organize data into a tree structure, where each record has a single parent node.
- Network database: Similar to hierarchical database, but allows each record to have multiple parent nodes.
- Multi-mode database: supports multiple data models and can store different types of data.
3.Integrated platform mode
As a system grows, effective communication between its components becomes critical.
- Point-to-point: Direct point-to-point integration can lead to tight coupling and hinder the scalability of the system. Message brokers decouple service communication, provide message queuing and load distribution, but introduce another layer of complexity that can become a single point of failure. An event-driven architecture using asynchronous processing offers the advantages of scalability and real-time response, but requires powerful mechanisms to ensure data consistency and order.
- API Gateway: API Gateway acts as a bridge between clients and services, providing a unified access point, centralized authentication, and more. Tradeoffs to consider include increased latency due to the extra network hops, potential bottlenecks that can arise if not scaled appropriately, and the complexity of managing another component. However, it simplifies client interaction, provides centralized logging and analysis, and can abstract the complexity of the underlying service.
- Message Broker: Decouple service communication, provide message queue and load distribution. However, they can introduce another layer of complexity and become a single point of failure.
- Publish/Subscribe (Pub/Sub): Allows services to publish events/messages, while other services subscribe to them. This decouples the service and provides scalability, but managing message order and ensuring delivery can be a challenge.
- Request/Reply: A synchronous mode in which a service sends a request and waits for a reply. This can introduce delays, especially if the response service takes time to process.
- Event sourcing: Capture state changes as events, allowing the system to reconstruct state by replaying events. Very useful for systems that require an audit trail.
- Data Integration (ETL): The process used to move data between systems, usually from an operating system to a data warehouse.
- Batch Integration: Data is passed between systems in batches rather than individually. Efficient for large amounts of data, but may introduce delays waiting for the next batch.
- Orchestration: A central service (orchestrator) is responsible for managing the interactions between services and ensuring that they are executed in a specific order.
- Streaming processing: A continuous stream of data, processed by record or step by step over a sliding time window.
4. Observability:
- Metrics: Quantitative data about a process, often used for system health checks.
- Tracking: Track the process of requests propagating between components.
- Log: Detailed records generated by software components, crucial for debugging.
- Event: A significant occurrence within the system that is worth noting. Events can be anything from user actions to system alerts.
- User Experience Monitoring: Observe and understand how end users interact with the system, focusing on performance and usability.
- Network Performance Monitoring: Monitor and analyze network traffic and metrics to assess the performance and health of your network.
- Synthetic Monitoring: Simulate user interaction with the system to test performance and usability.
- Real-time User Monitoring (RUM): Capture and analyze real-time user interactions to understand the actual user experience.
- Container and Orchestration Monitoring: Monitor the health and performance of containerized applications and orchestration platforms like Kubernetes.
5.DevSecOps:
- Automated security: Use tools to automate security checks and scans. Including static application security testing (SAST), dynamic application security testing (DAST) and dependency scanning.
- Continuous Monitoring: Ensure applications are monitored in real-time to detect and respond to threats. This includes monitoring system logs, user activity, and network traffic for any suspicious activity.
- CI/CD Automation: Continuous Integration and Continuous Deployment (CI/CD) pipelines ensure that code changes are automatically tested, built, and deployed before deployment. Integrating security checks into these pipelines ensures vulnerabilities are detected and addressed before deployment.
- Infrastructure as Code (IaC):
Manage and configure infrastructure using code and automation. Tools like Terraform and Ansible can be used for this, ensuring security best practices are followed in these scripts. - Container Security: As containerization becomes more common, ensuring the security of container images and runtimes is critical. This includes scanning container images for vulnerabilities and ensuring runtime security.
- Secret Management: Ensure sensitive data like API keys, passwords, and certificates are stored and managed securely. Tools like HashiCorp Vault can help manage and access secrets securely.
- Threat Modeling: Regularly assess and model potential threats to applications. This proactive approach helps understand potential attack vectors and mitigate them.
- Quality Assurance (QA) Integration: Embed quality checks and testing throughout the entire development cycle, not just in the post-development phase.
- Collaboration and Communication: Promote effective communication and collaboration between development, operations and security teams.
- Configuration Management: Manage and maintain consistency in product performance by controlling changes to software.
- Continuous Improvement: Implement mechanisms to collect feedback from all stakeholders and continuously improve processes and tools.
- Vulnerability Management: Not just scanning, but also systematically managing, prioritizing and remediating discovered vulnerabilities.
6. Communication protocol:
- HTTP/REST: A widely adopted protocol known for its simplicity and statelessness, commonly used for web services and APIs.
- gRPC: A high-performance, open source RPC framework that uses Protocol Buffers and supports features such as bidirectional streaming, making it very efficient for microservice communication.
- GraphQL: A query language for APIs that allows clients to request exactly what they need, reducing the over-fetching and under-fetching problems common in REST.
- WebSocket: A protocol that provides a full-duplex communication channel, ideal for real-time web applications.
- SOAP(Simple Object Access Protocol):
A protocol for exchanging structured information in web services, using XML, known for its robustness and scalability. - MQTT (Message Queuing Telemetry Transport): A lightweight messaging protocol designed for use in low-bandwidth, high-latency or unreliable networks, often used in IoT scenarios.
- AMQP (Advanced Message Queuing Protocol): A message-oriented middleware protocol that focuses on message queuing, routing and reliability, and is suitable for enterprise-level messaging.
- Thrift (Apache Thrift): A software framework for scalable cross-language service development that combines a software stack with a code generation engine for efficient multi-language service deployment.
- CoAP (Constrained Application Protocol): Web transmission protocol for constrained nodes and networks in the Internet of Things, similar to HTTP but more suitable for low-power devices.
- ZeroMQ: A high-performance asynchronous messaging library that provides message queues without the need for a dedicated message broker, for distributed or concurrent applications.
- SignalR: A library for ASP.NET that simplifies the process of adding real-time web functionality to applications, ideal for real-time communications in web applications.
7. Security:
- Authentication: Confirm the identity of a user or system.
- Authorization: Ensure that a user or system can only access resources that it has permission to access.
- Encryption: Protects the confidentiality of data by using algorithms to convert data into an unreadable format.
- Vulnerability Management: Continuously monitor, identify and resolve vulnerabilities in the system to reduce the potential attack surface.
- Audit and Compliance: Recording activities in the system and ensuring that the system complies with relevant regulations and standards.
- Network security: Ensure network security, including firewalls, intrusion detection systems (IDS), etc.
- Endpoint Security: Protect endpoint devices from threats, including malware, viruses, and cyberattacks.
- Emergency Response: Develop plans to respond to security incidents, including rapid response to potential threats.
- Container security: Ensure the security of container images and runtimes, including scanning container images for vulnerabilities, restricting container permissions, etc.
- API security: Protect APIs from abuse and attacks, including using API keys, OAuth and other security measures.
- Developer Training: Provide security training to developers to ensure they understand and follow security best practices.
- Business Continuity and Disaster Recovery: Develop plans to ensure that business operations can be restored quickly and efficiently in the event of a security incident.
- Vulnerability disclosure and response: Provide vulnerability disclosure channels for external researchers, and establish a response mechanism and vulnerability repair process.
- Partner and supply chain security: Ensure interactions with partners and supply chain are secure, preventing attackers from entering the system through these channels.
Methods of trade-off analysis
1. Cost and performance:
- Select cloud service:
A key aspect of the trade-off between cost and performance is choosing a cloud service. Some providers may be more cost-effective in some areas and offer better performance in others. Conduct a comprehensive assessment based on workload needs to select the most suitable cloud service provider. - Elastic Scaling: Use elastic scaling to adjust resources to adapt to changing workloads. This reduces costs during off-peak periods while providing adequate performance during peak periods.
- Cost Optimization Tools: Leverage the cloud provider's cost optimization tools and services to analyze and optimize resource usage to ensure that costs are minimized while providing adequate performance.
2. Reliability and scalability:
- Multi-region deployment: Deploy applications in multiple regions to increase availability. This may add some complexity and cost, but can significantly improve system reliability.
- Load balancing: Use load balancing to distribute traffic to ensure that no single point becomes the bottleneck of the system. This helps improve scalability and availability.
- Automated operation and maintenance: Use automated operation and maintenance tools to ensure the self-healing ability of the system. Automation can reduce the impact of system failures and improve reliability.
3. Consistency and performance:
- Distributed transactions: Use distributed transactions in scenarios that require consistency. This may have some impact on performance, but ensures data consistency.
- Sharding: Split data to improve performance. However, this may make it harder to maintain consistency across transactions across shards.
- Cache: Use caching to speed up read operations, but be aware that caching may cause consistency problems. Use appropriate caching strategies, such as cache invalidation or update-on-write cache, to maintain consistency.
4.Manage complexity:
- Microservice communication:
In a microservices architecture, communication between microservices can be a key source of complexity. Choose the appropriate communication mode, such as HTTP/REST, gRPC, etc., and use the appropriate tools to simplify communication. - Integration platform selection: Choose an appropriate integration platform model, such as API gateway, message broker, etc., to manage communication between services. This helps reduce communication complexity.
- Monitoring and Observation: Use appropriate monitoring and observation tools to understand the health of your system. This helps diagnose and resolve issues quickly, easing management complexity.
5. Security and flexibility:
- Zero Trust Security Model: Adopt a zero trust security model, which means not trusting any entity inside or outside the system. This helps improve the security of the system, but may add some management and configuration complexity.
- Role-Based Access Control (RBAC): Use RBAC to manage access to system resources. This helps improve security but requires flexible configuration and management.
6. Development speed and quality:
- Agile Development Practices: Adopt agile development practices such as Scrum or Kanban to increase development speed. However, make sure you develop quickly without sacrificing code quality.
- Automated testing: Use automated testing to ensure code quality. This helps speed up the development process, but requires some additional time to write and maintain the test suite.
- Code Review: Implement code review to ensure high quality code. This may increase development time, but improves code maintainability and quality.
7.User experience and performance:
- Front-end optimization: Improve user experience through front-end optimization measures, such as caching, resource merging, asynchronous loading, etc. However, this may add some development and maintenance complexity.
- Global Content Delivery Network (CDN): Use CDN to improve access performance for global users. This can significantly reduce load times, but requires managing CDN configuration and costs.
8. Flexibility and stability:
- Feature segmentation: Split the system into small functional units to improve flexibility. Be aware, however, that this may increase the complexity of the system as multiple functional units need to be managed.
- Feature switches: Use feature switches to enable or disable specific features at runtime. This facilitates feature switching without affecting the entire system, but requires additional configuration.
in conclusion
Trade-off analysis is critical when designing and managing complex systems. Teams need to carefully consider the trade-offs between different aspects in order to make informed decisions under various requirements and constraints. This may involve technology selection, architectural decisions, process design, etc. Throughout the development and operations cycles, continuous monitoring and feedback mechanisms are also critical to adapt to changes and continuously optimize the system. Ultimately, trade-offs are not just a one-time decision, but a constant iteration and adjustment as the system evolves.
The above is the detailed content of Trade-off analysis of modern distributed system architectures. For more information, please follow other related articles on the PHP Chinese website!

 深度学习架构的对比分析May 17, 2023 pm 04:34 PM
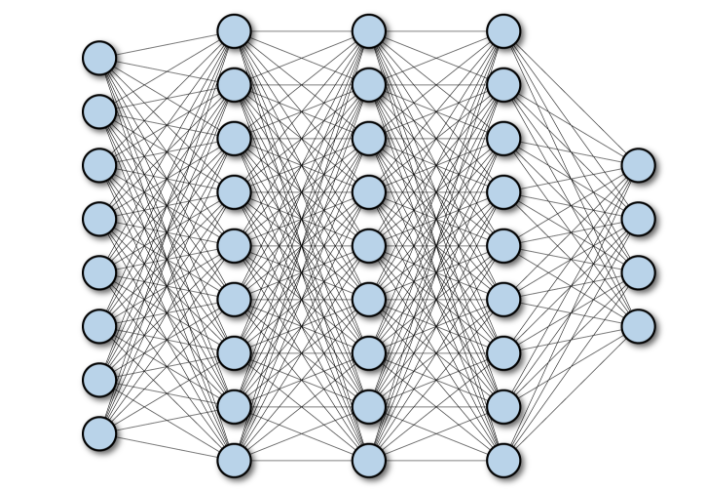
深度学习架构的对比分析May 17, 2023 pm 04:34 PM深度学习的概念源于人工神经网络的研究,含有多个隐藏层的多层感知器是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示,以表征数据的类别或特征。它能够发现数据的分布式特征表示。深度学习是机器学习的一种,而机器学习是实现人工智能的必经之路。那么,各种深度学习的系统架构之间有哪些差别呢?1.全连接网络(FCN)完全连接网络(FCN)由一系列完全连接的层组成,每个层中的每个神经元都连接到另一层中的每个神经元。其主要优点是“结构不可知”,即不需要对输入做出特殊的假设。虽然这种结构不可知使得完
 此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处Jun 14, 2023 pm 01:43 PM
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处Jun 14, 2023 pm 01:43 PM前段时间,一条指出谷歌大脑团队论文《AttentionIsAllYouNeed》中Transformer构架图与代码不一致的推文引发了大量的讨论。对于Sebastian的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到Transformer论文的流行程度,这个不一致问题早就应该被提及1000次。SebastianRaschka在回答网友评论时说,「最最原始」的代码确实与架构图一致,但2017年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
 多路径多领域通吃!谷歌AI发布多领域学习通用模型MDLMay 28, 2023 pm 02:12 PM
多路径多领域通吃!谷歌AI发布多领域学习通用模型MDLMay 28, 2023 pm 02:12 PM面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。此外,MDL模型也可以优于单
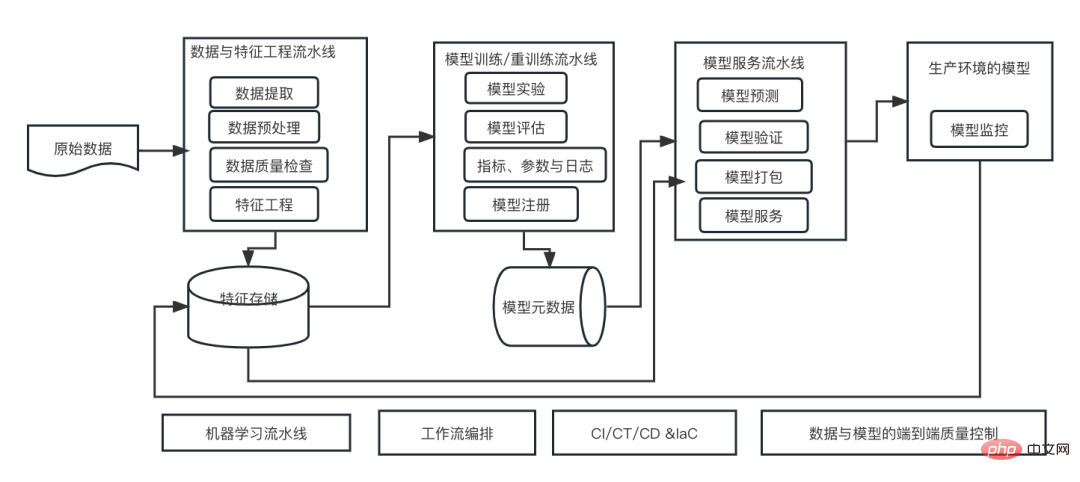 机器学习系统架构的十个要素Apr 13, 2023 pm 11:37 PM
机器学习系统架构的十个要素Apr 13, 2023 pm 11:37 PM这是一个AI赋能的时代,而机器学习则是实现AI的一种重要技术手段。那么,是否存在一个通用的通用的机器学习系统架构呢?在老码农的认知范围内,Anything is nothing,对系统架构而言尤其如此。但是,如果适用于大多数机器学习驱动的系统或用例,构建一个可扩展的、可靠的机器学习系统架构还是可能的。从机器学习生命周期的角度来看,这个所谓的通用架构涵盖了关键的机器学习阶段,从开发机器学习模型,到部署训练系统和服务系统到生产环境。我们可以尝试从10个要素的维度来描述这样的一个机器学习系统架构。1.
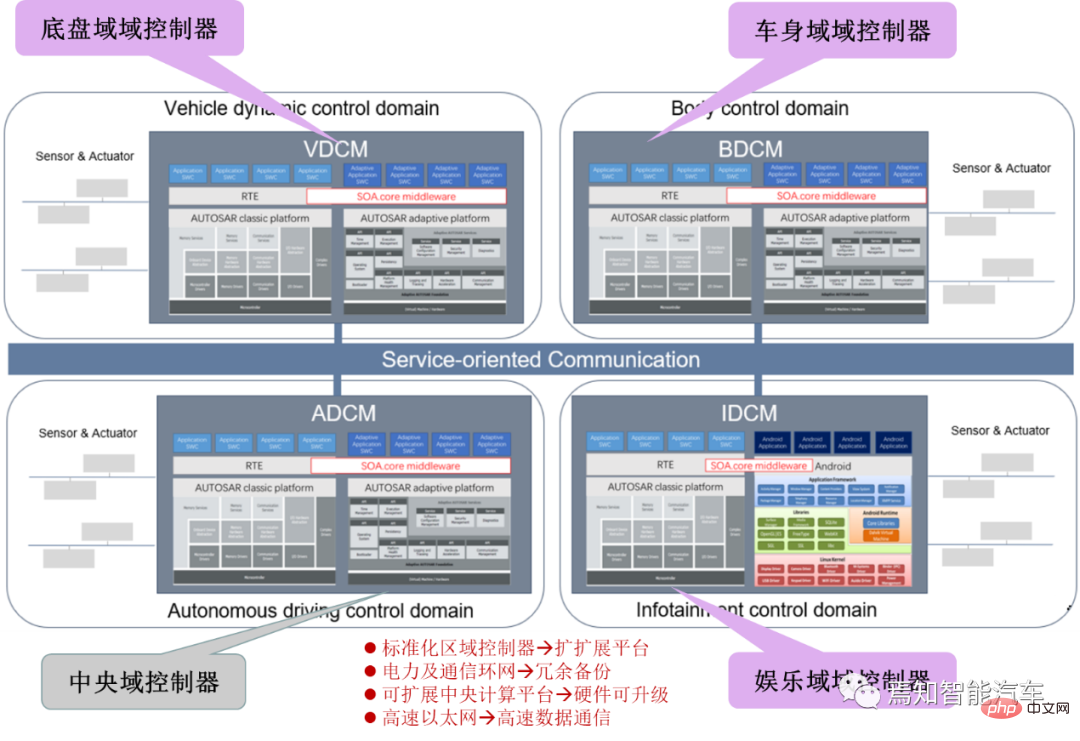 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
 2023年值得了解的几个前端格式化工具【总结】Sep 30, 2022 pm 02:17 PM
2023年值得了解的几个前端格式化工具【总结】Sep 30, 2022 pm 02:17 PMeslint 使用eslint的生态链来规范开发者对js/ts基本语法的规范。防止团队的成员乱写. 这里主要使用到的eslint的包有以下几个: 使用的以下语句来按照依赖: 接下来需要对eslint的
 AI基础设施:IT和数据科学团队协作的重要性May 18, 2023 pm 11:08 PM
AI基础设施:IT和数据科学团队协作的重要性May 18, 2023 pm 11:08 PM人工智能(AI)已经改变了许多行业的游戏规则,使企业能够提高效率、决策制定和客户体验。随着人工智能的不断发展和变得越来越复杂,企业投资于合适的基础设施来支持其开发和部署至关重要。该基础设施的一个关键方面是IT和数据科学团队之间的协作,因为两者在确保人工智能计划的成功方面都发挥着关键作用。人工智能的快速发展导致对计算能力、存储和网络能力的需求不断增加。这种需求给传统IT基础架构带来了压力,而传统IT基础架构并非旨在处理AI所需的复杂和资源密集型工作负载。因此,企业现在正在寻求构建能够支持AI工作负
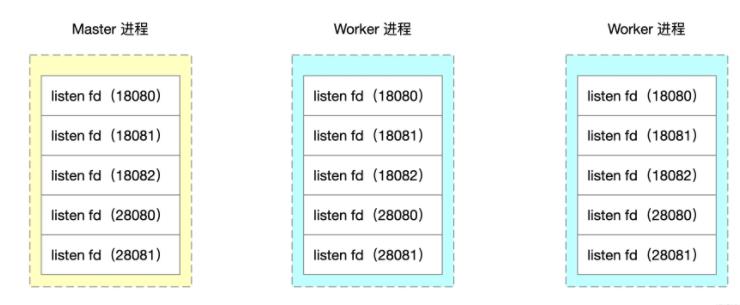 深析如何通过Nginx源码来实现worker进程隔离Nov 06, 2022 pm 04:41 PM
深析如何通过Nginx源码来实现worker进程隔离Nov 06, 2022 pm 04:41 PM本文给大家介绍如何通过修改Nginx源码实现基于端口号的 Nginx worker进程隔离方案。看看到底怎么修改Nginx源码,还有Nginx事件循环、Nginx 进程模型、fork资源共享相关的知识。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

