
Home >Technology peripherals >AI >Fudan University and others released AnyGPT: any modal input and output, including images, music, text, and voice.
Fudan University and others released AnyGPT: any modal input and output, including images, music, text, and voice.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-03-05 09:19:171074browse
Recently, OpenAI’s video generation model Sora has become popular, and the multi-modal capabilities of generative AI models have once again attracted widespread attention.
The real world is inherently multimodal, with organisms sensing and exchanging information through different channels, including vision, language, sound, and touch. One promising direction for developing multimodal systems is to enhance the multimodal perception capabilities of LLM, which mainly involves the integration of multimodal encoders with language models, thereby enabling them to process information across various modalities and leverage LLM's text processing ability to produce a coherent response.
However, this strategy only applies to text generation and does not cover multi-modal output. Some pioneering research has achieved significant progress in achieving multi-modal understanding and generation in language models, but these models are limited to a single non-text modality, such as image or audio.
In order to solve the above problems, Qiu Xipeng’s team at Fudan University, together with researchers from Multimodal Art Projection (MAP) and Shanghai Artificial Intelligence Laboratory, proposed a multi-modal language model called AnyGPT. , this model can understand and reason about the content of various modalities in any combination of modalities. Specifically, AnyGPT can understand instructions intertwined with multiple modalities such as text, voice, images, music, etc., and can skillfully select appropriate multi-modal combinations to respond.
For example, given a voice prompt, AnyGPT can generate a comprehensive response in the form of voice, image, and music:
Given a prompt in the form of a text image, AnyGPT can generate music according to the prompt requirements:

- Paper address: https://arxiv.org/pdf/2402.12226.pdf
- Project homepage: https://junzhan2000.github.io/AnyGPT.github.io/
Method introduction
AnyGPT leverages discrete representations to uniformly process various modalities, including speech, text, images, and music.
In order to complete the generation task from any modality to any modality, this research proposes a comprehensive framework that can be trained uniformly. As shown in Figure 1 below, the framework consists of three main components, including:
- Multimodal tokenizer
- as the backbone Multimodal language model of the network
- Multimodal de-tokenizer
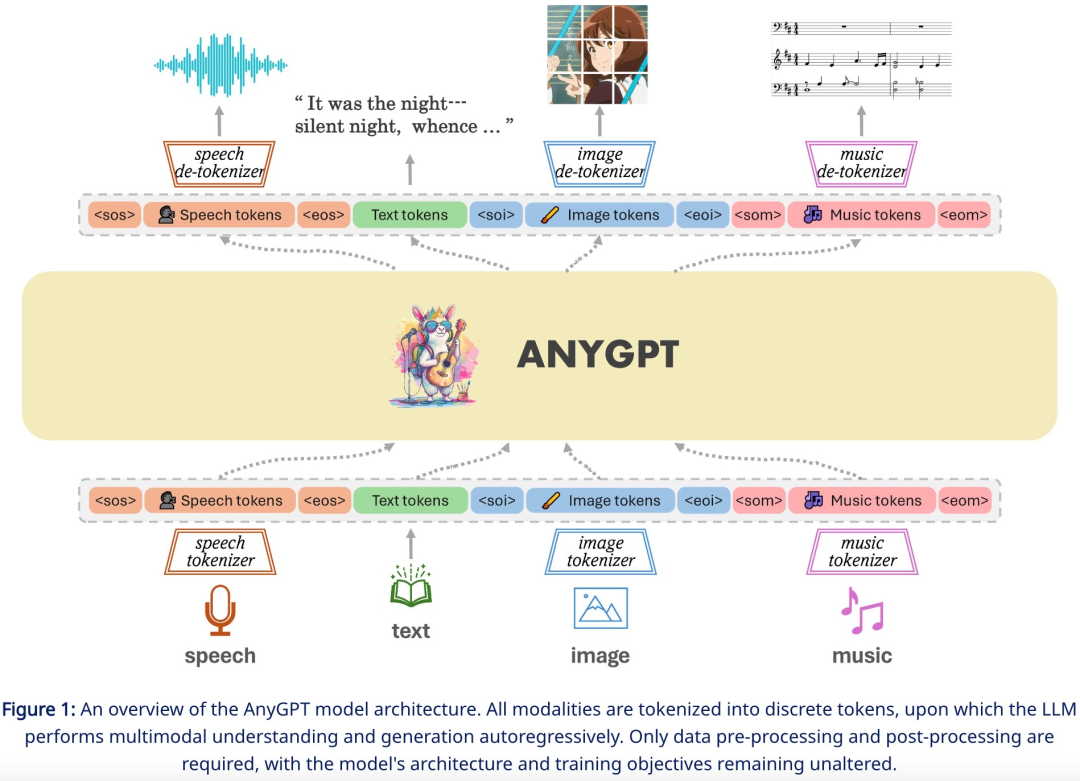
Among them , the tokenizer converts continuous non-text modalities into discrete tokens, which are subsequently arranged into multi-modal interleaved sequences. The language model is then trained using the next token prediction training target. During inference, multimodal tokens are decoded back to their original representations by associated de-tokenizers. To enrich the quality of the generation, multi-modal enhancement modules can be deployed to post-process the generated results, including applications such as speech cloning or image super-resolution.
AnyGPT can be trained stably without any changes to the current large language model (LLM) architecture or training paradigm. Instead, it relies entirely on data-level preprocessing, allowing new modalities to be seamlessly integrated into LLM, similar to adding a new language.
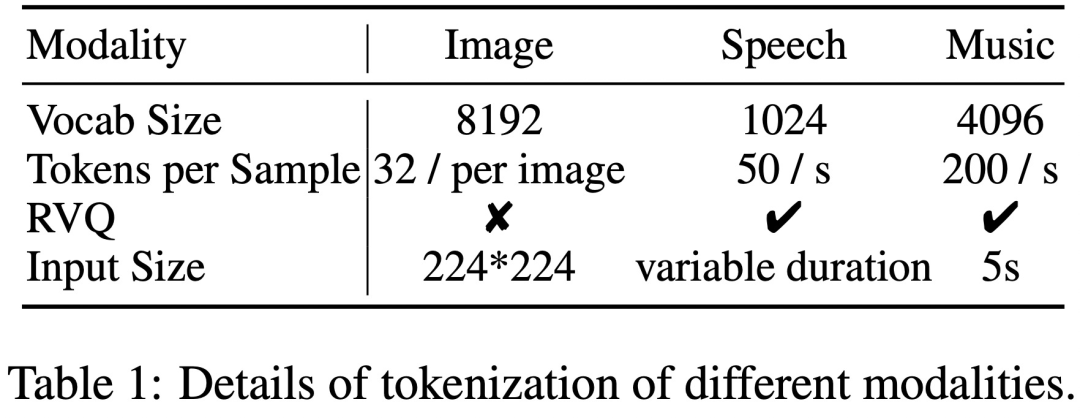
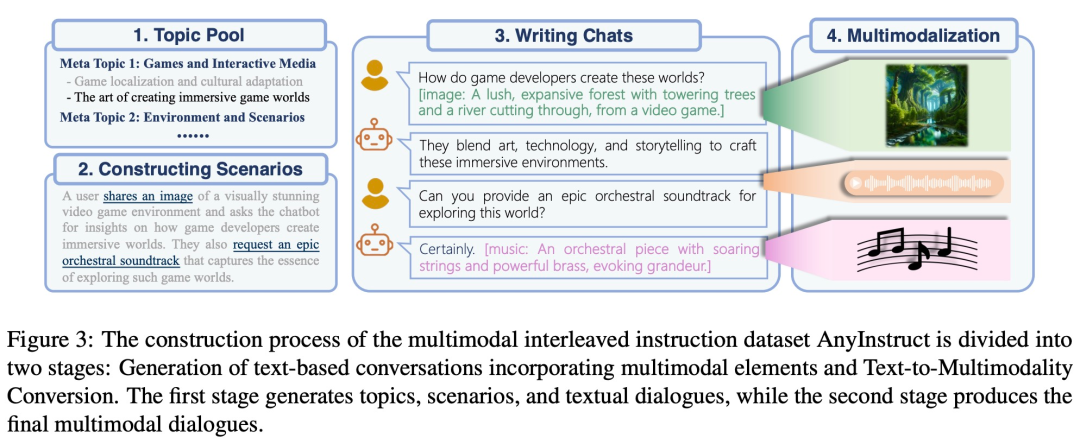
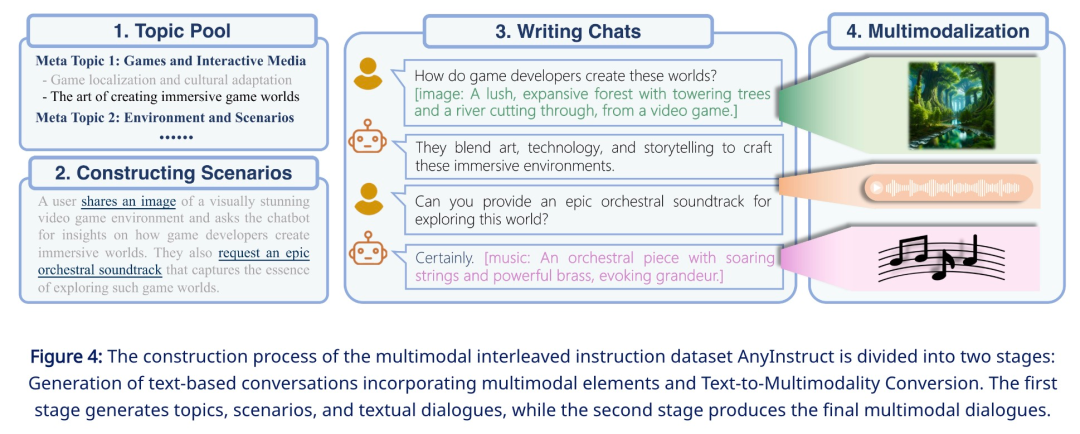
A key challenge in this research is the lack of multimodal interleaved instruction tracking data. In order to complete multi-modal alignment pre-training, the research team used a generative model to synthesize the first large-scale "any-to-any" multi-modal instruction data set - AnyInstruct-108k. It consists of 108k multi-turn dialogue samples that are intricately intertwined with various modalities, allowing the model to handle any combination of multi-modal inputs and outputs.

These data usually require a large number of bits to accurately represent, resulting in long sequences, which are particularly demanding on language models because the computational complexity increases exponentially with the sequence length. level increased. To solve this problem, this study adopts a two-stage high-fidelity generation framework, including semantic information modeling and perceptual information modeling. First, the language model is tasked with generating content that is fused and aligned at the semantic level. Then, the non-autoregressive model converts multi-modal semantic tokens into high-fidelity multi-modal content at the perceptual level, striking a balance between performance and efficiency.
##Experiment
Experiment The results show that AnyGPT is able to complete any-modality-to-any-modality dialogue tasks while achieving performance comparable to dedicated models in all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities in language models.
This study evaluates the basic capabilities of pre-trained base AnyGPT covering multi-modal understanding and generation tasks across all modalities. This evaluation aims to test the consistency between different modalities during the pre-training process. Specifically, the text-to-X and X-to-text tasks of each modality are tested, where X are images, music and voice.
In order to simulate real scenarios, all evaluations are conducted in zero-sample mode. This means that AnyGPT does not fine-tune or pre-train downstream training samples during the evaluation process. This challenging evaluation setting requires the model to generalize to an unknown test distribution.
The evaluation results show that AnyGPT, as a general multi-modal language model, achieves commendable performance on various multi-modal understanding and generation tasks.
Image
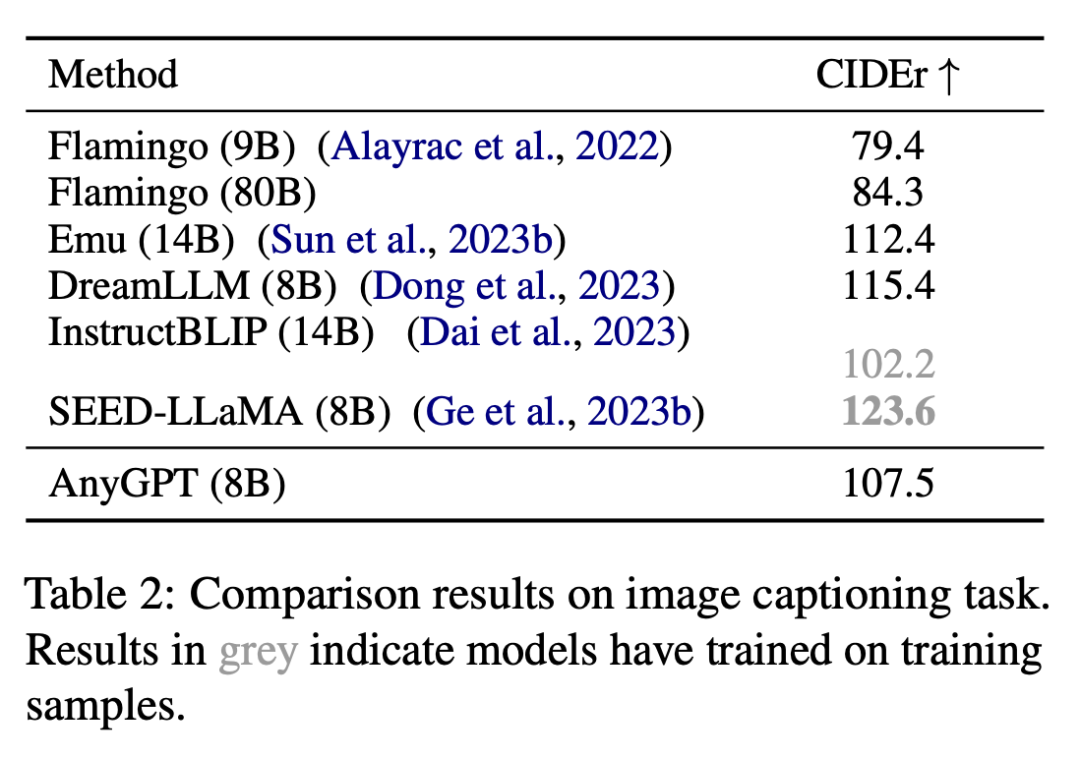
This study evaluated the image understanding ability of AnyGPT on the image description task. The results are shown in Table 2 shown.
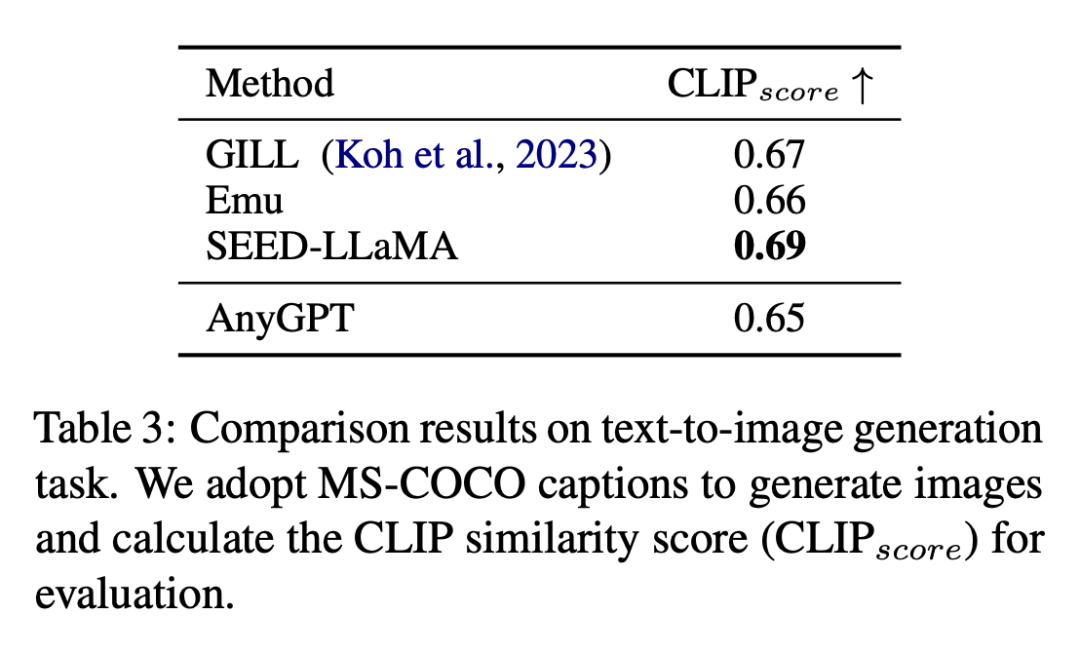
The results of the text-to-image generation task are shown in Table 3.
 Speech
Speech
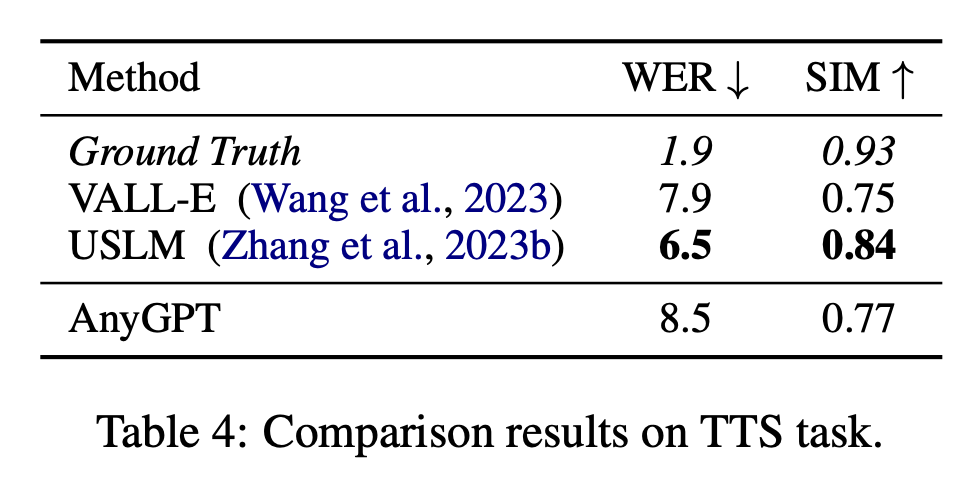
This study calculated the word error rate on the test subset of the LibriSpeech data set (WER) to evaluate the performance of AnyGPT on automatic speech recognition (ASR) tasks, and use Wav2vec 2.0 and Whisper Large V2 as baselines. The evaluation results are shown in Table 5.

music
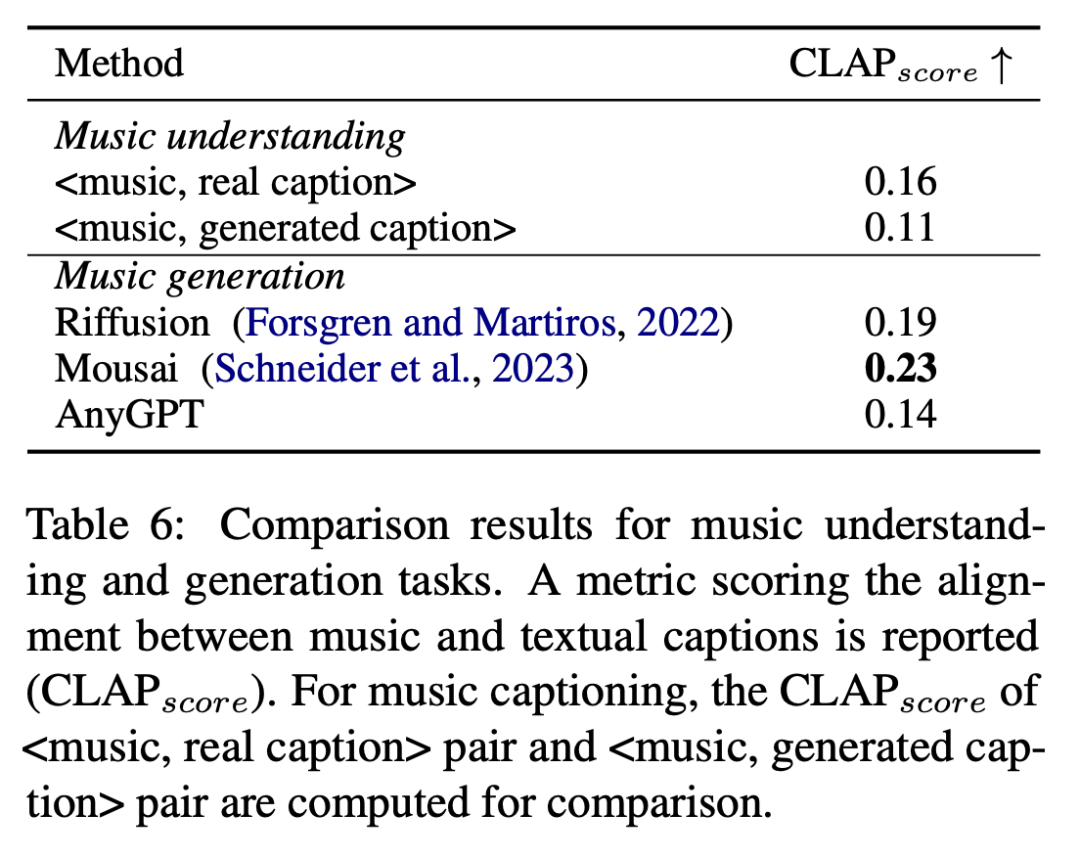
This study evaluated the performance of AnyGPT in music understanding and generation tasks on the MusicCaps benchmark, using CLAP_score score as an objective indicator to measure the similarity between the generated music and text descriptions. The evaluation results are shown in Table 6 Show.
Interested readers can read the original text of the paper to learn more about the research content.
The above is the detailed content of Fudan University and others released AnyGPT: any modal input and output, including images, music, text, and voice.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- JS full permutation and combination algorithm implementation method
- What are the two ways to write bubble sort? Use bubble sort to arrange 10 numbers.
- What is the main contribution of the Turing machine computational model?
- What settings can be used to arrange the desktop icons in Windows?
- How to arrange text horizontally in css