

 Technology peripheralsAIVPR 2024 perfect score paper! Meta proposes EfficientSAM: quickly split everything!
Technology peripheralsAIVPR 2024 perfect score paper! Meta proposes EfficientSAM: quickly split everything!VPR 2024 perfect score paper! Meta proposes EfficientSAM: quickly split everything!

EfficientSAM This work was included in CVPR 2024 with a perfect score of 5/5/5! The author shared the result on a social media, as shown in the picture below:

LeCun Turing Award winner also strongly recommended this work!

In recent research, Meta researchers have proposed a new improved method, which uses SAM masking. Code image pre-training (SAMI). This approach combines MAE pre-training techniques and SAM models to achieve high-quality pre-trained ViT encoders. Through SAMI, researchers try to improve the performance and efficiency of the model and provide better solutions for vision tasks. The proposal of this method brings new ideas and opportunities to further explore and develop the fields of computer vision and deep learning. By combining different pre-training techniques and model structures, researchers continue to

- Paper link: https://arxiv.org/pdf/2312.00863
- ##Code: github.com/yformer/ EfficientSAM
- Homepage: https://yformer.github.io/efficient-sam/
This approach reduces the complexity of SAM while maintaining good performance. Specifically, SAMI utilizes the SAM encoder ViT-H to generate feature embeddings and trains a mask image model with a lightweight encoder, thereby reconstructing features from SAM's ViT-H instead of image patches, and the resulting universal ViT backbone can be used downstream Tasks such as image classification, object detection and segmentation, etc. We then use the SAM decoder to fine-tune the pre-trained lightweight encoder to complete any segmentation task.
To verify the effectiveness of this approach, the researchers used a transfer learning setting pre-trained on masked images. Specifically, they first pre-trained the model with reconstruction loss on the ImageNet dataset with an image resolution of 224×224. They then fine-tune the model using supervised data from the target task. This transfer learning method can help the model learn quickly and improve performance on new tasks because the model has learned to extract features from the original data through the pre-training stage. This transfer learning strategy effectively utilizes the knowledge learned on large-scale data sets, making it easier for the model to adapt to different tasks. At the same time,
through SAMI pre-training, it can be used on ImageNet- Train models such as ViT-Tiny/-Small/-Base on 1K and improve generalization performance. For the ViT-Small model, after 100 times of fine-tuning on ImageNet-1K, the researchers achieved a Top-1 accuracy of 82.7%, which is better than other state-of-the-art image pre-training baselines.
The researchers fine-tuned the pre-trained model on target detection, instance segmentation and semantic segmentation. In all these tasks, our method achieves better results than other pre-trained baselines, and more importantly, achieves significant gains on small models.
Yunyang Xiong, the author of the paper, said: The EfficientSAM parameters proposed in this article are reduced by 20 times, but the running time is 20 times faster. The difference with the original SAM model is only within 2 percentage points, which is greatly Better than MobileSAM/FastSAM.

In the demo demonstration, click on the animal in the picture, and EfficientSAM can quickly segment the object:
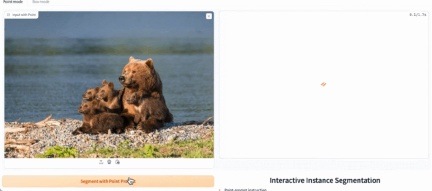
EfficientSAM can also accurately identify the person in the picture:
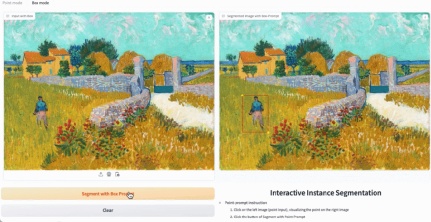
Trial address: https: //ab348ea7942fe2af48.gradio.live/
Method
EfficientSAM contains two stages: 1) Pre-training SAMI on ImageNet ( Top); 2) Fine-tuning SAM on SA-1B (bottom).

EfficientSAM mainly contains the following components:
Cross-attention decoder: Under the supervision of SAM features, this paper observes that only The mask token needs to be reconstructed by the decoder, and the output of the encoder can act as anchors during the reconstruction process. In the cross-attention decoder, the query comes from the masked tokens, and the keys and values are derived from the unmasked features and masked features from the encoder. This paper merges the output features from the masked tokens of the cross-attention decoder and the output features of the unmasked tokens from the encoder for MAE output embedding. These combined features will then be reordered to the original positions of the input image tokens in the final MAE output.
Linear projection head. We then fed the image outputs obtained through the encoder and cross-attention decoder into a small project head to align the features in the SAM image encoder. For simplicity, this paper only uses a linear projection head to solve the feature dimension mismatch between the SAM image encoder and MAE output.
Reconstruction loss. In each training iteration, SAMI includes forward feature extraction from the SAM image encoder and forward and backpropagation processes of the MAE. The outputs from the SAM image encoder and the MAE linear projection head are compared to calculate the reconstruction loss.

After pre-training, the encoder can extract feature representations for various visual tasks, and the decoder will also be discarded. In particular, in order to build an efficient SAM model for any segmentation task, this paper adopts SAMI pre-trained lightweight encoders (such as ViT-Tiny and ViT-Small) as the image encoder of EfficientSAM and the default mask decoder of SAM. , as shown in Figure 2 (bottom). This paper fine-tunes the EfficientSAM model on the SA-1B dataset to achieve segmentation of any task.
Experiment
Image classification. In order to evaluate the effectiveness of this method on image classification tasks, the researchers applied SAMI ideas to the ViT model and compared their performance on ImageNet-1K.
As shown in Table 1, SAMI is compared with pre-training methods such as MAE, iBOT, CAE and BEiT, and distillation methods such as DeiT and SSTA.

SAMI-B’s top1 accuracy reaches 84.8%, which is higher than the pre-trained baseline, MAE, DMAE, iBOT, CAE and BEiT. SAMI also shows large improvements compared to distillation methods such as DeiT and SSTA. For lightweight models such as ViT-Tiny and ViT-Small, SAMI results show significant gains compared to DeiT, SSTA, DMAE, and MAE.
Object detection and instance segmentation. This paper also extends the SAMI-pretrained ViT backbone to downstream object detection and instance segmentation tasks and compares it with a baseline pre-trained on the COCO dataset. As shown in Table 2, SAMI consistently outperforms the performance of other baselines.
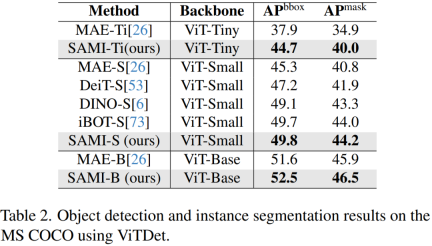
These experimental results show that the pre-trained detector backbone provided by SAMI is very effective in object detection and instance segmentation tasks. efficient.
Semantic segmentation. This paper further extends the pre-trained backbone to semantic segmentation tasks to evaluate its effectiveness. The results are shown in Table 3. Mask2former using SAMI pre-trained backbone achieves better mIoU on ImageNet-1K than using MAE pre-trained backbone. These experimental results verify that the technology proposed in this paper can generalize well to various downstream tasks.
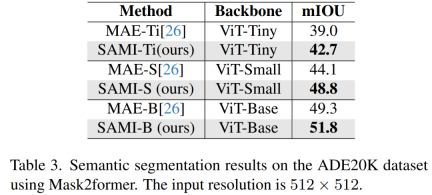
Table 4 compares EfficientSAMs with SAM, MobileSAM, and SAM-MAE-Ti. On COCO, EfficientSAM-Ti outperforms MobileSAM. EfficientSAM-Ti has SAMI pre-trained weights and also performs better than MAE pre-trained weights.
In addition, EfficientSAM-S is only 1.5 mIoU lower than SAM on the COCO box and 3.5 mIoU lower than SAM on the LVIS box, with 20 times fewer parameters. This paper also found that EfficientSAM also showed good performance in multiple clicks compared with MobileSAM and SAM-MAE-Ti.

Table 5 shows the AP, APS, APM and APL for zero-shot instance segmentation. The researchers compared EfficientSAM with MobileSAM and FastSAM, and it can be seen that compared to FastSAM, EfficientSAM-S gained more than 6.5 APs on COCO and 7.8 APs on LVIS. In the case of EffidientSAM-Ti, it is still significantly better than FastSAM, with 4.1 APs on COCO and 5.3 APs on LVIS, while MobileSAM has 3.6 APs on COCO and 5.5 APs on LVIS.
Moreover, EfficientSAM is much lighter than FastSAM. The parameters of efficientSAM-Ti are 9.8M, while the parameters of FastSAM are 68M.

Figures 3, 4, and 5 provide some qualitative results so that readers can have a complementary understanding of the instance segmentation capabilities of EfficientSAMs.



#For more research details, please refer to the original paper.
The above is the detailed content of VPR 2024 perfect score paper! Meta proposes EfficientSAM: quickly split everything!. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

