
 Technology peripheralsAIThe throughput is increased by 5 times. The LLM interface for jointly designing the back-end system and front-end language is here.
Technology peripheralsAIThe throughput is increased by 5 times. The LLM interface for jointly designing the back-end system and front-end language is here.The throughput is increased by 5 times. The LLM interface for jointly designing the back-end system and front-end language is here.

Large language models (LLMs) are widely used in complex tasks that require multiple chained generation calls, advanced hinting techniques, control flow, and interaction with the external environment. Despite this, current efficient systems for programming and executing these applications have significant shortcomings.
Researchers recently proposed a new Structured Generation Language (Structured Generation Language) called SGLang, which aims to improve interactivity with LLM. By integrating the design of the back-end runtime system and the front-end language, SGLang makes LLM more performant and easier to control. This research was also forwarded by Chen Tianqi, a well-known scholar in the field of machine learning and CMU assistant professor.
In general, SGLang’s contributions mainly include:
In the back end, the research team proposed RadixAttention, which is A KV cache (KV cache) reuse technology across multiple LLM generation calls, automatic and efficient.
In front-end development, the team developed a flexible domain-specific language that can be embedded in Python to control the generation process. This language can be executed in interpreter mode or compiler mode.
The back-end and front-end components work together to improve the execution and programming efficiency of complex LLM programs.
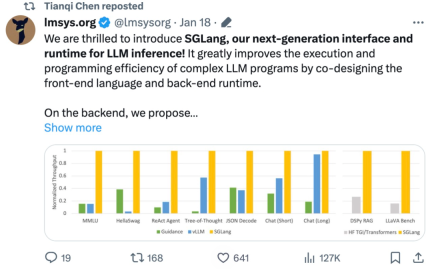
This study uses SGLang to implement common LLM workloads, including agent, inference, extraction, dialogue, and few-shot learning tasks, and adopts Llama-7B and Mixtral-8x7B models on NVIDIA A10G GPUs. As shown in Figure 1 and Figure 2 below, SGLang’s throughput is increased by 5 times compared to existing systems (i.e., Guidance and vLLM).
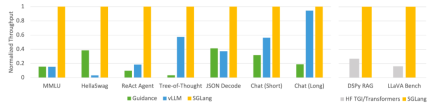
Figure 1: Throughput of different systems on LLM tasks (A10G, Llama-7B on FP16, tensor parallelism = 1)
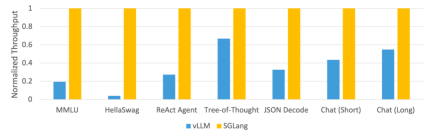
Figure 2: Throughput of different systems on LLM tasks (Mixtral-8x7B on A10G, FP16, Zhang Amount of parallelism = 8)
Backend: Use RadixAttention for automatic KV cache reuse
During the development process of SGLang runtime, the The study found that the key to optimizing complex LLM programs is KV cache reuse, which the current system does not handle well. KV cache reuse means that different prompts with the same prefix can share the intermediate KV cache, avoiding redundant memory and calculations. In complex programs involving multiple LLM calls, various modes of KV cache reuse may exist. Figure 3 below illustrates four such patterns commonly found in LLM workloads. While some systems are able to handle KV cache reuse in certain scenarios, manual configuration and ad hoc adjustments are often required. Furthermore, due to the diversity of possible reuse patterns, existing systems cannot automatically adapt to all scenarios even through manual configuration.
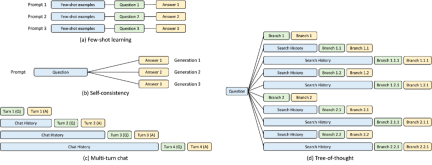
#Figure 3: KV cache sharing example. The blue box is the shareable prompt part, the green box is the non-shareable part, and the yellow box is the non-shareable model output. Shareable parts include small-shot learning examples, self-consistency questions, conversation history across multiple rounds of dialogue, and search history in tree-of-thought.
To systematically exploit these reuse opportunities, this research proposes a new method for automatic KV cache reuse at runtime - RadixAttention. Instead of discarding the KV cache after completing the build request, this method keeps the prompt and KV cache of the build result in a radix tree. This data structure enables efficient prefix searches, insertions, and evictions. This study implements a least recently used (LRU) eviction policy, supplemented by a cache-aware scheduling policy to improve the cache hit rate.
A radix tree can be used as a space-saving alternative to a trie (prefix tree). Unlike typical trees, the edges of radix trees can be marked not only with a single element, but also with sequences of elements of different lengths, which improves the efficiency of radix trees.
This research utilizes a radix tree to manage the mapping between token sequences acting as keys and corresponding KV cache tensors acting as values. These KV cache tensors are stored on the GPU in a paged layout, where each page is the size of a token.
Considering that the GPU memory capacity is limited and unlimited KV cache tensors cannot be retrained, an eviction strategy is required. This study adopts the LRU eviction strategy to evict leaf nodes recursively. Additionally, RadixAttention is compatible with existing technologies such as continuous batching and paged attention. For multi-modal models, RadixAttention can be easily extended to handle image tokens.
The diagram below illustrates how a radix tree is maintained when handling multiple incoming requests. The front end always sends the complete prompt to the runtime, and the runtime automatically performs prefix matching, reuse, and caching. The tree structure is stored on the CPU and has low maintenance overhead.
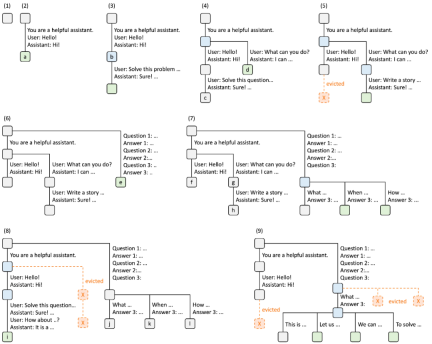
Figure 4. Example of RadixAttention operation using LRU eviction policy, illustrated in nine steps.
Figure 4 demonstrates the dynamic evolution of the radix tree in response to various requests. These requests include two chat sessions, a batch of few-shot learning queries, and self-consistent sampling. Each tree edge has a label representing a substring or sequence of tokens. Nodes are color-coded to reflect different states: green indicates newly added nodes, blue indicates cached nodes that were accessed at that point in time, and red indicates nodes that have been evicted.
Front End: LLM Programming Made Easy with SGLang
On the front end, the study proposes SGLang, a domain-specific language embedded in Python that allows expression Advanced prompt techniques, control flow, multimodality, decoding constraints and external interactions. SGLang functions can be run through various backends such as OpenAI, Anthropic, Gemini, and native models.
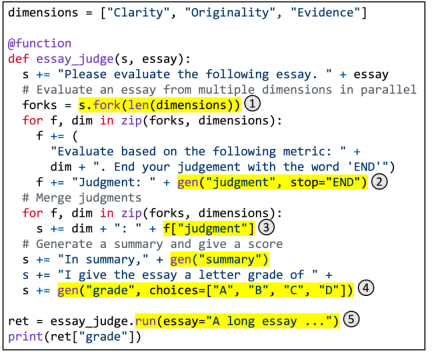
Figure 5. Using SGLang to implement multi-dimensional article scoring.
Figure 5 shows a specific example. It utilizes branch-resolve-merge prompt technology to achieve multi-dimensional article scoring. This function uses LLM to assess the quality of an article along multiple dimensions, combine judgments, generate a summary, and assign a final grade. The highlighted area illustrates the use of the SGLang API. (1) fork creates multiple parallel copies of prompt. (2) gen calls LLM generation and stores the results in variables. This call is non-blocking, so it allows multiple build calls to run simultaneously in the background. (3) [variable_name] retrieves the generated results. (4) Choose to impose constraints on the generation. (5) run executes the SGLang function using its parameters.
Given such an SGLang program, we can either execute it through the interpreter or trace it as a data flow graph and run it using a graph executor. The latter case opens up space for some potential compiler optimizations, such as code movement, instruction selection, and automatic tuning.
SGLang's syntax is heavily inspired by Guidance and introduces new primitives, also handling in-procedural parallelism and batch processing. All these new features contribute to SGLang's excellent performance.
Benchmarking
The research team tested its system on common LLM workloads and reported the achieved throughput.
Specifically, the study tested Llama-7B on 1 NVIDIA A10G GPU (24GB) and Mixtral-8x7B on 8 NVIDIA A10G GPUs with tensor parallelism using FP16 accuracy. And use vllm v0.2.5, guidance v0.1.8 and Hugging Face TGI v1.3.0 as baseline systems.
As shown in Figures 1 and 2, SGLang outperforms the baseline system in all benchmarks, achieving a 5x improvement in throughput. It also performs well in terms of latency, especially for first token latency, where prefix cache hits can bring significant benefits. These improvements are attributed to RadixAttention's automatic KV cache reuse, the in-program parallelism enabled by the interpreter, and the co-design of front-end and back-end systems. Additionally, ablation studies show that there is no significant overhead that results in RadixAttention always being enabled at runtime, even when there are no cache hits.
Reference link: https://lmsys.org/blog/2024-01-17-sglang/
The above is the detailed content of The throughput is increased by 5 times. The LLM interface for jointly designing the back-end system and front-end language is here.. For more information, please follow other related articles on the PHP Chinese website!

 What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AM
What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AMIntroduction In prompt engineering, “Graph of Thought” refers to a novel approach that uses graph theory to structure and guide AI’s reasoning process. Unlike traditional methods, which often involve linear s
 Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AM
Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AMIntroduction Congratulations! You run a successful business. Through your web pages, social media campaigns, webinars, conferences, free resources, and other sources, you collect 5000 email IDs daily. The next obvious step is
 Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AM
Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AMIntroduction In today’s fast-paced software development environment, ensuring optimal application performance is crucial. Monitoring real-time metrics such as response times, error rates, and resource utilization can help main
 ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM
ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM“How many users do you have?” he prodded. “I think the last time we said was 500 million weekly actives, and it is growing very rapidly,” replied Altman. “You told me that it like doubled in just a few weeks,” Anderson continued. “I said that priv
 Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AM
Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AMIntroduction Mistral has released its very first multimodal model, namely the Pixtral-12B-2409. This model is built upon Mistral’s 12 Billion parameter, Nemo 12B. What sets this model apart? It can now take both images and tex
 Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AM
Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AMImagine having an AI-powered assistant that not only responds to your queries but also autonomously gathers information, executes tasks, and even handles multiple types of data—text, images, and code. Sounds futuristic? In this a
 Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AM
Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AMIntroduction The finance industry is the cornerstone of any country’s development, as it drives economic growth by facilitating efficient transactions and credit availability. The ease with which transactions occur and credit
 Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AM
Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AMIntroduction Data is being generated at an unprecedented rate from sources such as social media, financial transactions, and e-commerce platforms. Handling this continuous stream of information is a challenge, but it offers an


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Zend Studio 13.0.1
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver CS6
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

