

 Backend DevelopmentPHP TutorialComprehensive analysis of the underlying implementation logic of PHP arrays
Backend DevelopmentPHP TutorialComprehensive analysis of the underlying implementation logic of PHP arrays
Preface
php editor Banana comprehensively analyzes the underlying implementation logic of PHP arrays. The array in PHP is a flexible and powerful data structure, but the implementation logic behind it is quite complex. In this article, we will delve into the underlying principles of PHP arrays, including the internal structure of the array, the relationship between indexes and hash tables, and how to implement the add, delete, modify, and query operations of the array. By understanding the underlying implementation logic of PHP arrays, developers can better understand and utilize arrays, an important data structure.
Structure of Array
What does an array look like in the PHP kernel? We can see the structure from PHP's source code as follows: The difference between
<code>// 定义结构体别名为 HashTable
typedef struct _zend_array HashTable;
struct _zend_array {
// <strong class="keylink">GC</strong> 保存引用计数,内存管理相关;本文不涉及
zend_refcounted_h gc;
// u 储存辅助信息;本文不涉及
u<strong class="keylink">NIO</strong>n {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
// 用于散列函数
uint32_t nTableMask;
// arData 指向储存元素的数组第一个 Bucket,Bucket 为统一的数组元素类型
Bucket *arData;
// 已使用 Bucket 数
uint32_t nNumUsed;
// 数组内有效元素个数
uint32_t nNumOfElements;
// 数组总容量
uint32_t nTableSize;
// 内部指针,用于遍历
uint32_t nInternalPointer;
// 下一个可用数字<strong class="keylink">索引</strong>
zend_long nNextFreeElement;
// 析构函数
dtor_func_t pDestructor;
};</code>
##nNumUsed
andnNumOfElements:nNumUsedrefers to theBucketnumber that has been used in thearDataarray, because the array only replaces theBucketcorresponding value of the element after deleting the element. The type is set toIS_UNDEF(because it would be a waste of time to move and re-index the array every time an element is deleted), andnNumOfElementscorresponds to the actual number of elements in the array.nTableSize
The capacity of the array, this value is the power of 2. PHP's arrays are of variable length, but C language arrays are of fixed length. In order to realize the function of PHP's variable-length arrays, the "expansion" mechanism is adopted, which is to determine whethernTableSizeis determined every time an element is inserted. Enough to store. If it is insufficient, re-apply for a new array 2 times the size ofnTableSize, and copy the original array (this is the time to clear the elements of typeIS_UNDEFin the original array) and re-index. .nNextFreeElement
Saves the next available numeric index, for example in PHP$a[] = 1;This usage will insert an index is the element ofnNextFreeElement, and thennNextFreeElementis incremented by 1.
_zend_array This structure will be discussed here first. The functions of some structure members will be explained below, so don’t be nervous O(∩_∩)O haha~. Let’s take a look at the Bucket structure as an array member:
<code>typedef struct _Bucket {
// 数组元素的值
zval val;
// key 通过 Time 33 <strong class="keylink">算法</strong>计算得到的哈希值或数字索引
zend_ulong h;
// 字符键名,数字索引则为 NULL
zend_string *key;
} Bucket;</code>Array accessWe know that PHP arrays are implemented based on hash tables, and unlike general hash tables The difference is that PHP's array also implements the ordering of elements, that is, the inserted elements are continuous from the perspective of memory and not out of order. In order to achieve this ordering, PHP uses "mapping table" technology. Below is an illustration to illustrate how we access the elements of the PHP array :-D.

Note: Because the key name to the mapping table subscript has been hashed twice, in order to distinguish it, this article uses hash to refer to the first hash. The hash is the second hash.
As can be seen from the figure, the mapping table and array elements are in the same continuous memory. The mapping table is an integer array with the same length as the storage elements. Its default value is -1 and the valid value isBucket The subscript of the array. And HashTable->arData points to the first element of the Bucket array in this memory.
$a['key'] Access the member whose key is key in the array$a. The process is introduced: first pass Time 33 algorithm calculates the hash value of key, and then uses the hash algorithm to calculate the mapping table subscript corresponding to the hash value, because the value saved in the mapping table is Bucket The subscript value in the array, so the corresponding element in the Bucket array can be obtained.
<code>nIndex = h | ht->nTableMask;</code>OR the hash value with
nTableMask to get the subscript of the mapping table, where the value of nTableMask is # Negative number of ##nTableSize. And since the value of nTableSize is a power of 2, the value range of h | ht->nTableMask is in [-nTableSize, -1] between, exactly within the subscript range of the mapping table. As for why not use a simple "remainder" operation but go to all the trouble of using a "bitwise OR" operation? Because the "bitwise OR" operation is much faster than the "remainder" operation, I think that for this frequently used operation, the time optimization brought about by a more complex implementation is worth it. Hash conflict
The "mapping table" subscripts obtained by hash calculation of hash values of different key names may be the same, and a hash conflict occurs. For this situation, PHP uses the "chain address method" to solve it. The following figure shows the situation of accessing an element where a hash conflict occurs:
这看似与第一张图差不多,但我们同样访问 $a['key'] 的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 val.u2.next 保存的值正是下一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 next 的值遍历直到找到键名相同的元素或查找失败。
插入元素
插入元素的函数 _zend_hash_add_or_update_i ,基于 PHP 7.2.9 的代码如下:
<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code>
扩容
前面将数组结构的时候我们有提到扩容,而在插入元素的代码里有这样一个宏 ZEND_HASH_IF_FULL_DO_RESIZE,这个宏其实就是调用了 zend_hash_do_resize 函数,对数组进行扩容并重新索引。注意:并非每次 Bucket 数组满了都需要扩容,如果 Bucket 数组中 IS_UNDEF 元素的数量占较大比例,就直接将 IS_UNDEF 元素删除并重新索引,以此节省内存。下面我们看看 zend_hash_do_resize 函数:
重新索引的逻辑在 zend_hash_rehash 函数中,代码如下:
总结
嗯哼,本文就到此结束了,因为自身水平原因不能解释的十分详尽清楚。这算是我写过最难写的内容了,写完之后似乎觉得这篇文章就我自己能看明白/(ㄒoㄒ)/~~因为文笔太辣鸡。想起一句话「如果你不能简单地解释一样东西,说明你没真正理解它。」PHP 的源码里有很多细节和实现我都不算熟悉,这篇文章只是一个我的 PHP 底层学习的开篇,希望以后能够写出真正深入浅出的好文章。
The above is the detailed content of Comprehensive analysis of the underlying implementation logic of PHP arrays. For more information, please follow other related articles on the PHP Chinese website!

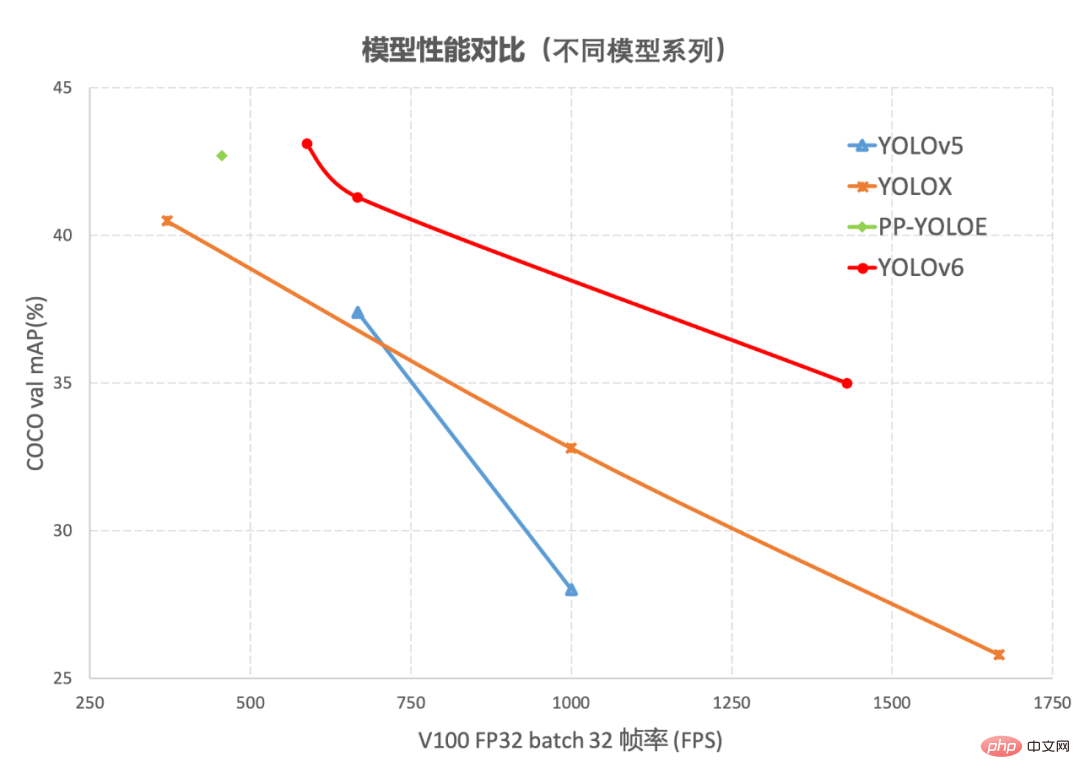 YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM
YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM作者:楚怡、凯衡等近日,美团视觉智能部研发了一款致力于工业应用的目标检测框架YOLOv6,能够同时专注于检测的精度和推理效率。在研发过程中,视觉智能部不断进行了探索和优化,同时吸取借鉴了学术界和工业界的一些前沿进展和科研成果。在目标检测权威数据集COCO上的实验结果显示,YOLOv6在检测精度和速度方面均超越其他同体量的算法,同时支持多种不同平台的部署,极大简化工程部署时的适配工作。特此开源,希望能帮助到更多的同学。1.概述YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用。
 MLC LLM:开源AI聊天机器人,支持离线运行,适用于集成显卡电脑和iPhone。May 06, 2023 pm 03:46 PM
MLC LLM:开源AI聊天机器人,支持离线运行,适用于集成显卡电脑和iPhone。May 06, 2023 pm 03:46 PM5月2日消息,目前大多数AI聊天机器人都需要连接到云端进行处理,即使可以本地运行的也配置要求极高。那么是否有轻量化的、无需联网的聊天机器人呢?一个名为MLCLLM的全新开源项目已在GitHub上线,完全本地运行无需联网,甚至集显老电脑、苹果iPhone手机都能运行。MLCLLM项目介绍称:“MLCLLM是一种通用解决方案,它允许将任何语言模型本地部署在一组不同的硬件后端和本地应用程序上,此外还有一个高效的框架,供每个人进一步优化自己用例的模型性能。一切都在本地运行,无需服务器支持,并通过手机和笔
 基于开源的 ChatGPT Web UI 项目,快速构建属于自己的 ChatGPT 站点Apr 15, 2023 pm 07:43 PM
基于开源的 ChatGPT Web UI 项目,快速构建属于自己的 ChatGPT 站点Apr 15, 2023 pm 07:43 PM作为一个技术博主,了不起比较喜欢各种折腾,之前给大家介绍过ChatGPT接入微信,钉钉和知识星球(如果没看过的可以翻翻前面的文章),最近再看开源项目的时候,发现了一个ChatGPTWebUI项目。想着刚好之前没有将ChatGPT接入过WebUI,有了这个开源项目可以拿来使用,真是不错,下面是实操的安装步骤,分享给大家。安装官方在Github的项目文档上提供了很多中的安装方式,包括手动安装,docker部署,以及远程部署等方法,了不起在选择部署方式的时候,一开始为了简单想着
 仅需1% Embedding参数,硬件成本降低十倍,开源方案单GPU训练超大推荐模型Apr 12, 2023 pm 03:46 PM
仅需1% Embedding参数,硬件成本降低十倍,开源方案单GPU训练超大推荐模型Apr 12, 2023 pm 03:46 PM深度推荐模型(DLRMs)已经成为深度学习在互联网公司应用的最重要技术场景,如视频推荐、购物搜索、广告推送等流量变现业务,极大改善了用户体验和业务商业价值。但海量的用户和业务数据,频繁地迭代更新需求,以及高昂的训练成本,都对 DLRM 训练提出了严峻挑战。在 DLRM 中,需要先在嵌入表(EmbeddingBags)中进行查表(lookup),再完成下游计算。嵌入表常常贡献 DLRM 中 99% 以上的内存需求,却只贡献 1% 的计算量。借助于 GPU 片上高速内存(High Bandwidth
 Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!Apr 23, 2023 am 10:16 AM
Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!Apr 23, 2023 am 10:16 AM自从Midjourney发布v5之后,在生成图像的人物真实程度、手指细节等方面都有了显著改善,并且在prompt理解的准确性、审美多样性和语言理解方面也都取得了进步。相比之下,StableDiffusion虽然免费、开源,但每次都要写一大长串的prompt,想生成高质量的图像全靠多次抽卡。最近StabilityAI的官宣,正在研发的StableDiffusionXL开始面向公众测试,目前可以在Clipdrop平台免费试用。试用链接:https://clipdrop.co/stable-diff
 用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统May 11, 2023 pm 07:25 PM
用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统May 11, 2023 pm 07:25 PM在人类的感官中,一张图片可以将很多体验融合到一起,比如一张海滩图片可以让我们想起海浪的声音、沙子的质地、拂面而来的微风,甚至可以激发创作一首诗的灵感。图像的这种「绑定」(binding)属性通过与自身相关的任何感官体验对齐,为学习视觉特征提供了大量监督来源。理想情况下,对于单个联合嵌入空间,视觉特征应该通过对齐所有感官来学习。然而这需要通过同一组图像来获取所有感官类型和组合的配对数据,显然不可行。最近,很多方法学习与文本、音频等对齐的图像特征。这些方法使用单对模态或者最多几种视觉模态。最终嵌入仅
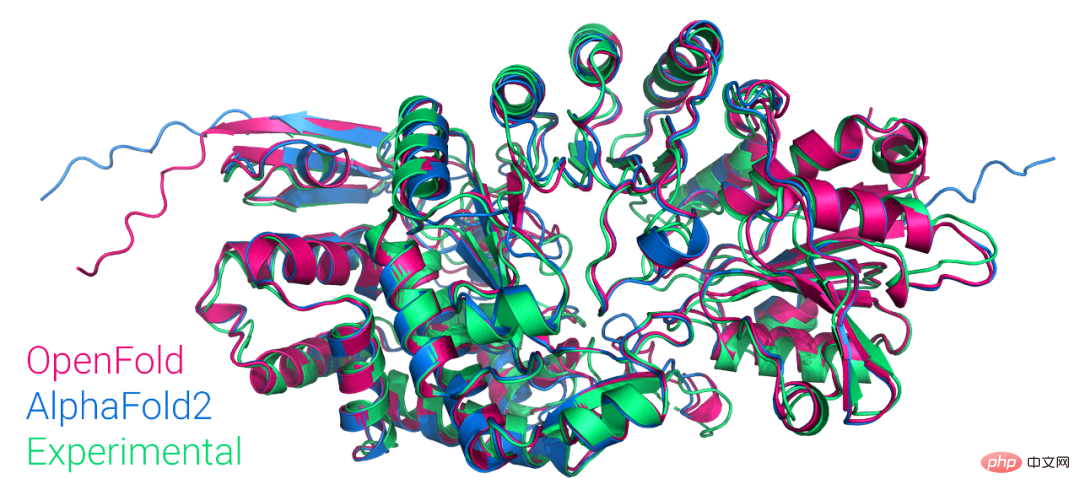 首个大众可用PyTorch版AlphaFold2复现,哥大开源,star量破千Apr 13, 2023 am 09:58 AM
首个大众可用PyTorch版AlphaFold2复现,哥大开源,star量破千Apr 13, 2023 am 09:58 AM刚刚,哥伦比亚大学系统生物学助理教授 Mohammed AlQuraishi 在推特上宣布,他们从头训练了一个名为 OpenFold 的模型,该模型是 AlphaFold2 的可训练 PyTorch 复现版本。Mohammed AlQuraishi 还表示,这是第一个大众可用的 AlphaFold2 复现。AlphaFold2 可以周期性地以原子精度预测蛋白质结构,在技术上利用多序列对齐和深度学习算法设计,并结合关于蛋白质结构的物理和生物学知识提升了预测效果。它实现了 2/3 蛋白质结构预测的卓
 基于PyTorch、易上手,细粒度图像识别深度学习工具库Hawkeye开源Apr 12, 2023 pm 08:43 PM
基于PyTorch、易上手,细粒度图像识别深度学习工具库Hawkeye开源Apr 12, 2023 pm 08:43 PM细粒度图像识别 [1] 是视觉感知学习的重要研究课题,在智能新经济和工业互联网等方面具有巨大应用价值,且在诸多现实场景已有广泛应用…… 鉴于当前领域内尚缺乏该方面的深度学习开源工具库,南京理工大学魏秀参教授团队用时近一年时间,开发、打磨、完成了 Hawkeye——细粒度图像识别深度学习开源工具库,供相关领域研究人员和工程师参考使用。本文是对 Hawkeye 的详细介绍。1.什么是 Hawkeye 库Hawkeye 是一个基于 PyTorch 的细粒度图像识别深度学习工具库,专为相关领域研究人员和


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

