

 Technology peripheralsAIWant to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration
Technology peripheralsAIWant to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration
Sora’s stunning performance in early 2024 has become a new benchmark, inspiring all those who study Wensheng videos to rush to catch up. Every researcher is eager to replicate Sora's results and works against time.
According to the technical report disclosed by OpenAI, an important innovation point of Sora is to convert visual data into a unified representation of patches, and combine it with the Transformer and diffusion model to demonstrate excellent performance. Scalability. With the release of the report, the paper "Scalable Diffusion Models with Transformers" co-authored by William Peebles, Sora's core developer, and Xie Saining, assistant professor of computer science at New York University, has attracted much attention from researchers. The research community hopes to explore feasible ways to reproduce Sora through the DiT architecture proposed in the paper.
Recently, a project called OpenDiT open sourced by the You Yang team of the National University of Singapore has opened up new ideas for training and deploying DiT models.
OpenDiT is a system designed to improve the training and inference efficiency of DiT applications. It is not only easy to operate, but also fast and memory efficient. The system covers functions such as text-to-video generation and text-to-image generation, aiming to provide users with an efficient and convenient experience.
Project address: https://github.com/NUS-HPC-AI-Lab/OpenDiT
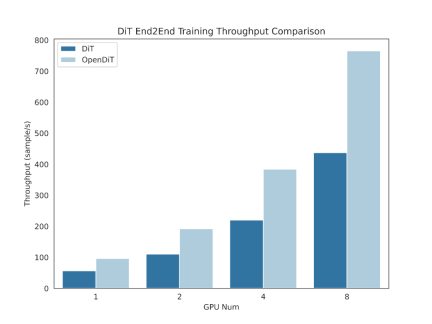
OpenDiT method introduction
OpenDiT provides a high-performance implementation of the Diffusion Transformer (DiT) powered by Colossal-AI. During training, video and condition information are input into the corresponding encoder respectively as input to the DiT model. Subsequently, training and parameter updating are performed through the diffusion method, and finally the updated parameters are synchronized to the EMA (Exponential Moving Average) model. In the inference stage, the EMA model is directly used, taking condition information as input to generate corresponding results.
Picture source: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT uses the ZeRO parallel strategy to distribute the DiT model parameters to multiple machines, initially reducing the memory pressure. In order to achieve a better balance between performance and accuracy, OpenDiT also adopts a mixed-precision training strategy. Specifically, model parameters and optimizers are stored using float32 to ensure accurate updates. During the model calculation process, the research team designed a mixed precision method of float16 and float32 for the DiT model to speed up the calculation process while maintaining model accuracy.
The EMA method used in the DiT model is a strategy for smoothing model parameter updates, which can effectively improve the stability and generalization ability of the model. However, an additional copy of the parameters will be generated, which increases the burden on the video memory. In order to further reduce this part of video memory, the research team fragmented the EMA model and stored it on different GPUs. During the training process, each GPU only needs to calculate and store its own part of the EMA model parameters, and wait for ZeRO to complete the update after each step for synchronous updates.
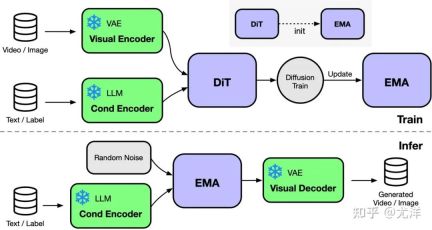
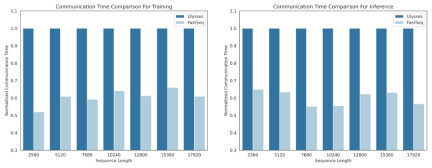
FastSeq
In the field of visual generative models such as DiT, sequence parallelism is critical for efficient long sequence training and low Delayed reasoning is essential.
However, existing methods such as DeepSpeed-Ulysses, Megatron-LM Sequence Parallelism face limitations when applied to such tasks - either introducing too much sequence communication, or Lack of efficiency when dealing with small-scale sequential parallelism.
To this end, the research team proposed FastSeq, a new sequence parallelism suitable for large sequences and small-scale parallelism. FastSeq minimizes sequence communication by using only two communication operators per transformer layer, leverages AllGather to improve communication efficiency, and strategically employs asynchronous rings to overlap AllGather communication with qkv calculations to further optimize performance.
##Operator optimization
The adaLN module is introduced into the DiT model to integrate conditional information into visual content. Although this operation is crucial to improving the performance of the model, it also brings a large number of element-by-element operations and is frequently used in the model. Calling reduces the overall computing efficiency. In order to solve this problem, the research team proposed an efficient Fused adaLN Kernel, which merges multiple operations into one, thereby increasing computing efficiency and reducing I/O consumption of visual information.
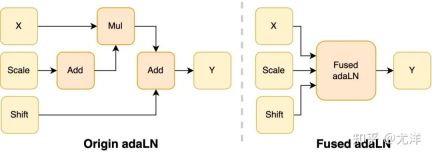
Picture source: https://www.zhihu.com/people/berkeley-you-yang
Simply put, OpenDiT has the following performance advantages:
#1. Acceleration up to 80% on GPU, 50% memory saving
- Designed efficient operators, including Fused AdaLN designed for DiT, as well as FlashAttention, Fused Layernorm and HybridAdam.
- Use a hybrid parallel approach including ZeRO, Gemini and DDP. Sharding the ema model also further reduces memory costs.
#2. FastSeq: a novel sequence parallel method
- is designed for similar DiT is designed for workloads where the sequences are usually longer but the parameters are smaller compared to LLM.
- Intra-node sequence parallelism can save up to 48% of traffic.
- Break the memory limitations of a single GPU and reduce overall training and inference time.
3. Easy to use
- Just need to modify a few lines of code. Get huge performance improvements.
- Users do not need to understand how distributed training is implemented.
4. Text to image and text to video generation complete pipeline
- Researcher and engineers can easily use the OpenDiT pipeline and apply it to real-world applications without modifying the parallel part.
- The research team verified the accuracy of OpenDiT by conducting text-to-image training on ImageNet and released a checkpoint.
Installation and use
To use OpenDiT, you must first install the prerequisites:
- Python >= 3.10
- PyTorch >= 1.13 (version 2.0 is recommended)
- CUDA > = 11.6
It is recommended to create a new environment using Anaconda (Python >= 3.10) to run the examples:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
Install ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
Install OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
(can Optional but recommended) Install libraries to speed up training and inference:
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
Image generation
You can train the DiT model by executing the following command:
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
All acceleration methods are disabled by default. Here are details on some of the key elements in the training process:
- #plugin: Supports the booster plugin used by ColossalAI, zero2 and ddp. The default is zero2, it is recommended to enable zero2.
- mixed_ precision: The data type of mixed precision training, the default is fp16.
- grad_checkpoint: Whether to enable gradient checkpoint. This saves the memory cost of the training process. The default value is False. It is recommended to disable it if there is enough memory.
- enable_modulate_kernel: Whether to enable modulate kernel optimization to speed up the training process. The default value is False and it is recommended to enable it on GPUs
- enable_layernorm_kernel: Whether to enable layernorm kernel optimization to speed up the training process. The default value is False and it is recommended to enable it.
- enable_flashattn: Whether to enable FlashAttention to speed up the training process. The default value is False and it is recommended to enable it.
- sequence_parallel_size: sequence parallelism size. Sequence parallelism is enabled when setting a value > 1. The default value is 1, it is recommended to disable it if there is enough memory.
If you want to use the DiT model for inference, you can run the following code. You need to replace the checkpoint path with your own trained model.
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
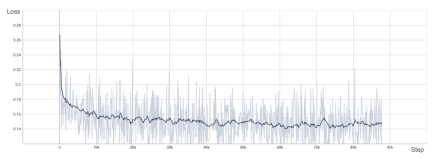
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
The above is the detailed content of Want to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration. For more information, please follow other related articles on the PHP Chinese website!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SublimeText3 English version
Recommended: Win version, supports code prompts!

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 Linux new version
SublimeText3 Linux latest version

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

