


bitsCN.com
优化mysql嵌套查询和联表查询
嵌套查询糟糕的优化
在上面我提到过,不考虑特殊的情况,联表查询要比嵌套查询更有效。尽管两条查询表达的是同样的意思,尽管你的计划是告诉服务器要做什么,然后让它决定怎么做,但有时候你非得告诉它改怎么做。否则优化器可能会做傻事。我最近就碰到这样的情况。这几个表是三层分级关系:category, subcategory和item。有几千条记录在category表,几百条记录在subcategory表,以及几百万条在item表。你可以忽略category表了,我只是交代一下背景,以下查询语句都不涉及到它。这是创建表的语句:
[sql]
create table subcategory (
id int not null primary key,
category int not null,
index(category)
) engine=InnoDB;
create table item(
id int not null auto_increment primary key,
subcategory int not null,
index(subcategory)
) engine=InnoDB;
我又往表里面填入一些样本数据 www.bitsCN.com
[sql]
insert into subcategory(id, category)
select i, i/100 from number
where i
insert into item(subcategory)
select id
from (
select id, rand() * 20 as num_rows from subcategory
) as x
cross join number
where i
create temporary table t as
select subcategory from item
group by subcategory
having count(*) = 19
limit 100;
insert into item (subcategory)
select subcategory
from t
cross join number
where i
再次说明,这些语句运行完需要一点时间,不适合放在产品环境中运行。思路是往item里插入随机行数的数据,这样subcategory就有1到2018之间个item。这不是实际中的完整数据,但效果一样。
我想找出某个category中item数大于2000的全部subcategory。首先,我找到一个subcategory item数大于2000的,然后把它的category用在接下来的查询中。这是具体的查询语句:
[sql]
select c.id
from subcategory as c
inner join item as i on i.subcategory = c.id
group by c.id
having count(*) > 2000;
-- choose one of the results, then
select * from subcategory where id = ????
-- result: category = 14
我拿到一个合适的值14,在以下的查询中会用到它。这是用来查询category 14 中所有item数大于2000的subcategory的语句:
[sql]
select c.id
from subcategory as c
inner join item as i on i.subcategory = c.id
where c.category = 14
group by c.id
having count(*) > 2000;
在我的样例数据里,查询的结果有10行记录,而且只用10多秒就完成了。EXPLAIN显示出很好地使用了索引;从数据的规模来看,相当不错了。查询计划是在索引上遍历并计算出目标记录。目前为止,非常好。
这回假设我要从subcategory取出全部的字段。我可以把上面的查询当成嵌套,然后用JOIN,或者SELECT MAX之类(既然分组集对应的值都是唯一的),但也写成跟下面的一样的,有木有?
[sql]
select * from subcategory
where id in (
select c.id
from subcategory as c
inner join item as i on i.subcategory = c.id
where c.category = 14
group by c.id
having count(*) > 2000
);
跑完这条查询估计要从破晓到夕阳沉入大地。我不知道它要跑多久,因为我没打算让它无休止地跑下去。你可能认为,单从语句上理解,它会:a)计算出里面的查询,找出那10个值,b)继续找出那10条记录,并且在primary索引上去找会非常地快。错,这是实际上的查询计划:
[sql]
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: subcategory
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 300783
Extra: Using where
*************************** 2. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: c
type: ref
possible_keys: PRIMARY,category
key: category
key_len: 4
ref: const
rows: 100
Extra: Using where; Using index; Using temporary; Using filesort
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: i
type: ref
possible_keys: subcategory
key: subcategory
key_len: 4
ref: c.id
rows: 28
Extra: Using index
如何你不熟悉如何分析mysql的语句查询计划,请看大概意思:mysql计划从外到内执行查询,而不是从内到外。我会一个一个地介绍查询的每个部分。
外面的查询简单地变成了SELECT * FROM subcategory。虽然里面的查询对subcategory有个约束(WHERE category = 14),但出于某些原因mysql没有将它作用于外面的查询。我不知道是神马原因。我只知道它扫描了整张表(这就是 type:ALL 表示的意思),并且没有使用任何的索引。这是在10几万行记录的表上扫描。
在外面的查询,对每行都执行一次里面的查询,尽管没有值被里面的查询使用到,因为里面的查询被“优化”成引用外面的查询。照此分析,查询计划变成了嵌套循环。外面的查询的每一次循环,都执行一次里面的查询。下面就是优化器重写后的查询计划:
[sql]
select * from subcategory as s
where
s.id,
select c.id
from subcategory as c
join item as i
where ((i.subcategory = c.id) and (c.category = 14))
group by c.id
having ((count(0) > 2000)
and (
)
你可以通过在EXPLAIN EXTENDED 后面带上SHOW WARNINGS 得到优化后的查询。请留意在HAVING子句中指向的外部域。
我举这个例子并非有意抨击mysql的优化策略。众所皆知mysql在有些情况下还不能很好地优化嵌套查询,这个问题已经被广泛报告过。我想指出的是,开发者有必要检查查询语句确保它们不是被糟糕地优化。大多数情况下,安全起见若非是非必要,避免使用嵌套——尤其是WHERE...IN() 和 WHERE...NOT IN语句。
我自己的原则是“有疑问,EXPLAIN看看”。如果面对的是一个大数据表,我会自然而然地产生疑问。
如何强制里面的查询先执行
上一节中的语句撞板只因为mysql把它当成相关的语句从外到里地执行,而不是当成不相关语句从里到外执行。让mysql先执行里面的查询也是有办法的,当成临时表来实现,从而避免巨大的性能开销。
mysql从临时表来实现嵌套查询(某种程度上被讹传的衍生表)。这意味着mysql先执行里面的查询,并且把结果储存在临时表中,然后在其他的表里用到它。这就是我写这个查询时所期待的执行方式。查询语句修改如下: www.bitsCN.com
[sql]
select * from subcategory
where id in (
select id from (
select c.id
from subcategory as c
inner join item as i on i.subcategory = c.id
where c.category = 14
group by c.id
having count(*) > 2000
) as x
);
我所做的就是把嵌套包着原来的嵌套查询。mysql会认为最里面是一个独立的嵌套查询先执行,然后现在只剩下包着外面的嵌套,它已经被装进一个临时表里,只有少量记录,因此要快很多。依此分析,这是相当笨的优化办法;倒不如把它重写成join方式。再说,免得被别人看到,当成多余代码清理掉。
有些情况可以使用这种优化方法,比如mysql抛出错误,嵌套查询的表在其他地方被修改(译注:另一篇文章 MySQL SELECT同时UPDATE同一张表 )。不幸的是,对于临时表只能在查询语句中使用一次的情况,这种方法就无能为力了。
来源 http://blog.csdn.net/afeiqiang/article/details/8620038
bitsCN.com
 如何在 RHEL 9 上配置 DHCP 服务器Jun 08, 2023 pm 07:02 PM
如何在 RHEL 9 上配置 DHCP 服务器Jun 08, 2023 pm 07:02 PMDHCP是“动态主机配置协议DynamicHostConfigurationProtocol”的首字母缩写词,它是一种网络协议,可自动为计算机网络中的客户端系统分配IP地址。它从DHCP池或在其配置中指定的IP地址范围分配客户端。虽然你可以手动为客户端系统分配静态IP,但DHCP服务器简化了这一过程,并为网络上的客户端系统动态分配IP地址。在本文中,我们将演示如何在RHEL9/RockyLinux9上安装和配置DHCP服务器。先决条件预装RHEL9或RockyLinux9具有sudo管理权限的普
 在容器中怎么使用nginx搭建上传下载的文件服务器May 15, 2023 pm 11:49 PM
在容器中怎么使用nginx搭建上传下载的文件服务器May 15, 2023 pm 11:49 PM一、安装nginx容器为了让nginx支持文件上传,需要下载并运行带有nginx-upload-module模块的容器:sudopodmanpulldocker.io/dimka2014/nginx-upload-with-progress-modules:latestsudopodman-d--namenginx-p83:80docker.io/dimka2014/nginx-upload-with-progress-modules该容器同时带有nginx-upload-module模块和ng
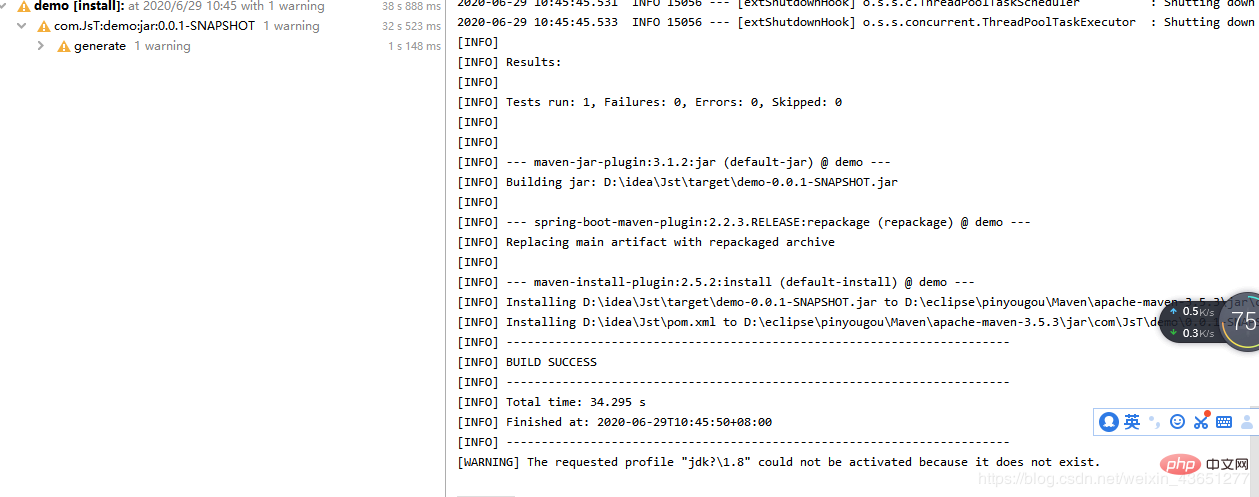 服务器怎么使用Nginx部署Springboot项目May 14, 2023 pm 01:55 PM
服务器怎么使用Nginx部署Springboot项目May 14, 2023 pm 01:55 PM1,将java项目打成jar包这里我用到的是maven工具这里有两个项目,打包完成后一个为demo.jar,另一个为jst.jar2.准备工具1.服务器2.域名(注:经过备案)3.xshell用于连接服务器4.winscp(注:视图工具,用于传输jar)3.将jar包传入服务器直接拖动即可3.使用xshell运行jar包注:(服务器的java环境以及maven环境,各位请自行配置,这里不做描述。)cd到jar包路径下执行:nohupjava-jardemo.jar>temp.txt&
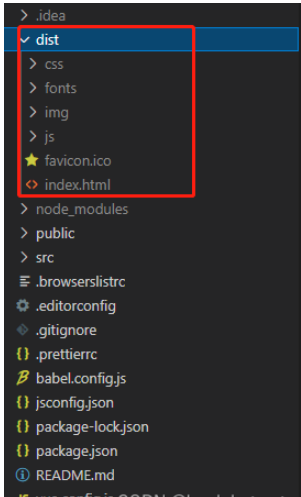 vue3项目打包发布到服务器后访问页面显示空白怎么解决May 17, 2023 am 08:19 AM
vue3项目打包发布到服务器后访问页面显示空白怎么解决May 17, 2023 am 08:19 AMvue3项目打包发布到服务器后访问页面显示空白1、处理vue.config.js文件中的publicPath处理如下:const{defineConfig}=require('@vue/cli-service')module.exports=defineConfig({publicPath:process.env.NODE_ENV==='production'?'./':'/&
 python中怎么使用TCP实现对话客户端和服务器May 17, 2023 pm 03:40 PM
python中怎么使用TCP实现对话客户端和服务器May 17, 2023 pm 03:40 PMTCP客户端一个使用TCP协议实现可连续对话的客户端示例代码:importsocket#客户端配置HOST='localhost'PORT=12345#创建TCP套接字并连接服务器client_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)client_socket.connect((HOST,PORT))whileTrue:#获取用户输入message=input("请输入要发送的消息:&
 Linux怎么在两个服务器直接传文件May 14, 2023 am 09:46 AM
Linux怎么在两个服务器直接传文件May 14, 2023 am 09:46 AMscp是securecopy的简写,是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。scp是加密的,rcp是不加密的,scp是rcp的加强版。因为scp传输是加密的,可能会稍微影响一下速度。另外,scp还非常不占资源,不会提高多少系统负荷,在这一点上,rsync就远远不及它了。虽然rsync比scp会快一点,但当小文件众多的情况下,rsync会导致硬盘I/O非常高,而scp基本不影响系统正常使用。场景:假设我现在有两台服务器(这里的公网ip和内网ip相互传都可以,当然用内网ip相互传
 如何使用psutil模块获取服务器的CPU、内存和磁盘使用率?May 07, 2023 pm 10:28 PM
如何使用psutil模块获取服务器的CPU、内存和磁盘使用率?May 07, 2023 pm 10:28 PMpsutil是一个跨平台的Python库,它允许你获取有关系统进程和系统资源使用情况的信息。它支持Windows、Linux、OSX、FreeBSD、OpenBSD和NetBSD等操作系统,并提供了一些非常有用的功能,如:获取系统CPU使用率、内存使用率、磁盘使用率等信息。获取进程列表、进程状态、进程CPU使用率、进程内存使用率、进程IO信息等。杀死进程、发送信号给进程、挂起进程、恢复进程等操作。使用psutil,可以很方便地监控系统的运行状况,诊断问题和优化性能。以下是一个简单的示例,演示如何
 怎么在同一台服务器上安装多个MySQLMay 29, 2023 pm 12:10 PM
怎么在同一台服务器上安装多个MySQLMay 29, 2023 pm 12:10 PM一、安装前的准备工作在进行MySQL多实例的安装前,需要进行以下准备工作:准备多个MySQL的安装包,可以从MySQL官网下载适合自己环境的版本进行下载:https://dev.mysql.com/downloads/准备多个MySQL数据目录,可以通过创建不同的目录来支持不同的MySQL实例,例如:/data/mysql1、/data/mysql2等。针对每个MySQL实例,配置一个独立的MySQL用户,该用户拥有对应的MySQL安装路径和数据目录的权限。二、基于二进制包安装多个MySQL实例


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Mac version
God-level code editing software (SublimeText3)

