

 Technology peripheralsAIBreak into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it
Technology peripheralsAIBreak into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes itBreak into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it

The diffusion model has ushered in a major new application -
Just like Sora generates videos, it generates parameters for the neural network and directly penetrates into the bottom layer of AI!
This is the latest open source research result of Professor You Yang’s team at the National University of Singapore, together with UCB, Meta AI Laboratory and other institutions.

Specifically, the research team proposed a diffusion model p(arameter)-diff for generating neural network parameters.
Use it to generate network parameters, the speed is up to 44 times faster than direct training, and the performance is not inferior.
After the model was released, it quickly aroused heated discussions in the AI community. Experts in the circle expressed the same amazing attitude towards it as ordinary people did when they saw Sora.
Some people even directly exclaimed that this is basically equivalent to AI creating new AI.

Even AI giant LeCun praised the result after seeing it, saying it was really a cute idea.

In fact, p-diff does have the same significance as Sora. Dr. Fuzhao Xue (Xue Fuzhao) from the same laboratory explained in detail:
Sora generates high-dimensional data, i.e. videos, which makes Sora a world simulator (close to AGI from one dimension).
And this work, neural network diffusion, can generate parameters in the model, has the potential to become a meta-world-class learner/optimizer, moving towards AGI from another new important dimension.

Getting back to the subject, how does p-diff generate neural network parameters?
Combining the autoencoder with the diffusion model
To clarify this problem, we must first understand the working characteristics of the diffusion model and the neural network.
The diffusion generation process is a transformation from a random distribution to a highly specific distribution. Through the addition of compound noise, the visual information is reduced to a simple noise distribution.
Neural network training also follows this transformation process and can also be degraded by adding noise. Inspired by this feature, researchers proposed the p-diff method.
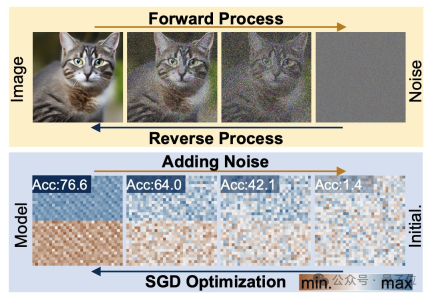
From a structural point of view, p-diff is designed by the research team based on the standard latent diffusion model and combined with the autoencoder.
The researcher first selects a part of the network parameters that have been trained and performed well, and expands them into a one-dimensional vector form.
An autoencoder is then used to extract latent representations from the one-dimensional vector as training data for the diffusion model, which can capture the key features of the original parameters.
During the training process, the researchers let p-diff learn the distribution of parameters through forward and reverse processes. After completion, the diffusion model synthesizes these potential representations from random noise like the process of generating visual information. .
Finally, the newly generated latent representation is restored to network parameters by the decoder corresponding to the encoder and used to build a new model.

The following figure is the parameter distribution of the ResNet-18 model trained from scratch using 3 random seeds through p-diff, showing the differences between different layers and the same layer. distribution pattern among parameters.

To evaluate the quality of the parameters generated by p-diff, the researchers used 3 types of neural networks of two sizes each on 8 data sets. taking the test.
In the table below, the three numbers in each group represent the evaluation results of the original model, the integrated model and the model generated with p-diff.
As can be seen from the results, the performance of the model generated by p-diff is basically close to or even better than the original model trained manually.

In terms of efficiency, without losing accuracy, p-diff generates ResNet-18 network 15 times faster than traditional training, and generates Vit-Base 44 times faster.

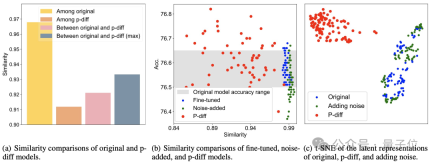
Additional test results demonstrate that the model generated by p-diff is significantly different from the training data.
As can be seen from the figure (a) below, the similarity between the models generated by p-diff is lower than the similarity between the original models, as well as the similarity between p-diff and the original model.
It can be seen from (b) and (c) that compared with fine-tuning and noise addition methods, the similarity of p-diff is also lower.
These results show that p-diff actually generates a new model, rather than just memorizing training samples. It also shows that it has good generalization ability and can generate new models that are different from the training data.
Currently, the code of p-diff has been open sourced. If you are interested, you can check it out on GitHub.
Paper address: https://arxiv.org/abs/2402.13144
GitHub: https ://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
The above is the detailed content of Break into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

