

 Technology peripheralsAIGoogle AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Technology peripheralsAIGoogle AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance featuresGoogle AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features

After the AI video model Sora became popular, major companies such as Meta and Google have stepped aside to do research and catch up with OpenAI.
Recently, researchers from the Google team proposed a universal video encoder-VideoPrism.
It can handle various video understanding tasks through a single frozen model.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2402.13217.pdf
For example, VideoPrism can convert the following The people blowing candles in the video are classified and located.
 Picture
Picture
Video-text retrieval, according to the text content, the corresponding content in the video can be retrieved.
 Picture
Picture
For another example, describe the video below - a little girl is playing with building blocks.
You can also conduct QA questions and answers.
- What color are the blocks she placed above the green blocks?
- Purple.
 Picture
Picture
The researchers pre-trained VideoPrism on a heterogeneous corpus containing 36 million high-quality video subtitle pairs and 582 million video clips. , and with noisy parallel text (such as ASR transcribed text).
It is worth mentioning that VideoPrism refreshed 30 SOTA in 33 video understanding benchmark tests.
 Picture
Picture
Universal Visual Encoder VideoPrism
Currently, the Video Fundamental Model (ViFM) has great potential to be used in huge Unlock new abilities within the corpus.
Although previous research has made great progress in general video understanding, building a true "basic video model" is still an elusive goal.
In response, Google launched VideoPrism, a general-purpose visual encoder designed to solve a wide range of video understanding tasks, including classification, localization, retrieval, subtitles, and question answering (QA).
VideoPrism is extensively evaluated on CV datasets, as well as CV tasks in scientific fields such as neuroscience and ecology.
Achieve state-of-the-art performance with minimal fitness by using a single frozen model.
In addition, Google researchers say that this frozen encoder setting follows previous research and takes into account its practical practicality, as well as the high cost of computation and fine-tuning the video model.
 Picture
Picture
Design architecture, two-stage training method
The design concept behind VideoPrism is as follows.
Pre-training data is the basis of the basic model (FM). The ideal pre-training data for ViFM is a representative sample of all videos in the world.
In this sample, most videos do not have parallel text describing the content.
However, if trained on such text, it can provide invaluable semantic clues about the video space.
Therefore, Google’s pre-training strategy should focus primarily on the video mode while fully utilizing any available video-text pairs.
On the data side, Google researchers approximated this by assembling 36 million high-quality video subtitle pairs and 582 million video clips with noisy parallel text (such as ASR transcriptions, generated subtitles, and retrieved text). Required pre-training corpus.
 picture
picture
 Picture
Picture
In terms of modeling, the authors first comparatively learn semantic video embeddings from all video-text pairs of different qualities.
The masked video modeling described below is then improved by global and label refinement of the semantic embeddings using a wide range of pure video data.
Despite the success in natural language, masked data modeling remains challenging for CV due to the lack of semantics in the original visual signal.
Existing research addresses this challenge by borrowing indirect semantics (such as using CLIP to guide models or tokenizers, or implicit semantics) or implicitly generalizing them (such as labeling visual patches), which converts high masking rates into Combined with lightweight decoders.
Based on the above ideas, the Google team adopted a two-stage approach based on pre-training data.
 Picture
Picture
In the first stage, contrastive learning is performed to align the video encoder with the text encoder using all video-text pairs.
Based on previous research, the Google team minimized the similarity scores of all video-text pairs in the batch, performing symmetric cross-entropy loss minimization.
And use CoCa's image model to initialize the spatial coding module, and incorporate WebLI into pre-training.
Before calculating the loss, the video encoder features are aggregated through multi-head attention pooling (MAP).
This stage allows the video encoder to learn rich visual semantics from linguistic supervision, and the resulting model provides semantic video embeddings for the second stage training.
 Picture
Picture
In the second stage, the encoder continues to be trained and two improvements are made:
-The model needs to be based on the unmasked The input video patches of the code are used to predict the video-level global embedding and token embedding in the first stage
- The output token of the encoder is randomly shuffled before being passed to the decoder to avoid learning shortcuts.
Notably, the researchers’ pre-training leveraged two supervision signals: the textual description of the video, and contextual self-supervision, allowing VideoPrism to perform well on appearance- and action-centric tasks.
In fact, previous research shows that video captions mainly reveal appearance cues, while contextual supervision helps learn actions.
 Picture
Picture
Experimental Results
Next, the researchers evaluated VideoPrism on a wide range of video-centric comprehension tasks, showing Its capabilities and versatility.
Mainly divided into the following four categories:
(1) Generally only video understanding, including classification and spatio-temporal positioning
(2) Zero-sample video text retrieval
(3) Zero-sample video subtitles and quality checking
(4) CV tasks in science
Classification and spatiotemporal localization
Table 2 shows freezing on VideoGLUE Backbone results.
VideoPrism significantly outperforms the baseline on all datasets. Furthermore, increasing VideoPrism’s underlying model size from ViT-B to ViT-g significantly improves performance.
It is worth noting that no baseline method achieves the second best result across all benchmarks, suggesting that previous methods may have been developed to target certain aspects of video understanding.
And VideoPrism continues to improve on this broad task.
This result shows that VideoPrism integrates various video signals into one encoder: semantics at multiple granularities, appearance and motion cues, spatiotemporal information, and the ability to interpret different video sources (such as online videos and scripted performances) of robustness.
 Picture
Picture
Zero-shot video text retrieval and classification
Tables 3 and 4 summarize the results of video text retrieval and video classification respectively.
VideoPrism’s performance refreshes multiple benchmarks, and on challenging data sets, VideoPrism has achieved very significant improvements compared with previous technologies.
 Picture
Picture
Most results for the base model VideoPrism-B actually outperform existing larger-scale models.
Furthermore, VideoPrism is comparable to or even better than the models in Table 4 pretrained using in-domain data and additional modalities (e.g., audio). These improvements in zero-shot retrieval and classification tasks reflect VideoPrism’s powerful generalization capabilities.
 Picture
Picture
Zero-sample video subtitles and quality check
Table 5 and Table 6 show, respectively, zero-sample video subtitles and QA the result of.
Despite the simple model architecture and the small number of adapter parameters, the latest models are still competitive and, with the exception of VATEX, rank among the top methods for freezing visual and language models.
The results show that the VideoPrism encoder can generalize well to video-to-language generation tasks.
 Pictures
Pictures
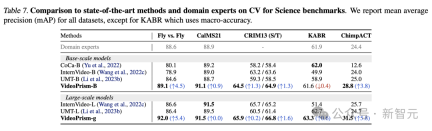
CV tasks in science
Generic ViFM uses a shared frozen encoder in all evaluations and its performance is comparable to that of specialized Comparable to domain-specific models for a single task.
In particular, VideoPrism often performs best and outperforms domain expert models with base scale models.
Scaling to large-scale models can further improve performance on all datasets. These results demonstrate that ViFM has the potential to significantly accelerate video analysis in different fields.
Ablation Study
Figure 4 shows the ablation results. Notably, VideoPrism’s continued improvements on SSv2 demonstrate the effectiveness of data management and model design efforts in promoting motion understanding in video.
Although the comparative baselines already achieved competitive results on K400, the proposed global distillation and token shuffling further improve the accuracy.
 Picture
Picture
Reference:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder.html
The above is the detailed content of Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features. For more information, please follow other related articles on the PHP Chinese website!

 AI Game Development Enters Its Agentic Era With Upheaval's Dreamer PortalMay 02, 2025 am 11:17 AM
AI Game Development Enters Its Agentic Era With Upheaval's Dreamer PortalMay 02, 2025 am 11:17 AMUpheaval Games: Revolutionizing Game Development with AI Agents Upheaval, a game development studio comprised of veterans from industry giants like Blizzard and Obsidian, is poised to revolutionize game creation with its innovative AI-powered platfor
 Uber Wants To Be Your Robotaxi Shop, Will Providers Let Them?May 02, 2025 am 11:16 AM
Uber Wants To Be Your Robotaxi Shop, Will Providers Let Them?May 02, 2025 am 11:16 AMUber's RoboTaxi Strategy: A Ride-Hail Ecosystem for Autonomous Vehicles At the recent Curbivore conference, Uber's Richard Willder unveiled their strategy to become the ride-hail platform for robotaxi providers. Leveraging their dominant position in
 AI Agents Playing Video Games Will Transform Future RobotsMay 02, 2025 am 11:15 AM
AI Agents Playing Video Games Will Transform Future RobotsMay 02, 2025 am 11:15 AMVideo games are proving to be invaluable testing grounds for cutting-edge AI research, particularly in the development of autonomous agents and real-world robots, even potentially contributing to the quest for Artificial General Intelligence (AGI). A
 The Startup Industrial Complex, VC 3.0, And James Currier's ManifestoMay 02, 2025 am 11:14 AM
The Startup Industrial Complex, VC 3.0, And James Currier's ManifestoMay 02, 2025 am 11:14 AMThe impact of the evolving venture capital landscape is evident in the media, financial reports, and everyday conversations. However, the specific consequences for investors, startups, and funds are often overlooked. Venture Capital 3.0: A Paradigm
 Adobe Updates Creative Cloud And Firefly At Adobe MAX London 2025May 02, 2025 am 11:13 AM
Adobe Updates Creative Cloud And Firefly At Adobe MAX London 2025May 02, 2025 am 11:13 AMAdobe MAX London 2025 delivered significant updates to Creative Cloud and Firefly, reflecting a strategic shift towards accessibility and generative AI. This analysis incorporates insights from pre-event briefings with Adobe leadership. (Note: Adob
 Everything Meta Announced At LlamaConMay 02, 2025 am 11:12 AM
Everything Meta Announced At LlamaConMay 02, 2025 am 11:12 AMMeta's LlamaCon announcements showcase a comprehensive AI strategy designed to compete directly with closed AI systems like OpenAI's, while simultaneously creating new revenue streams for its open-source models. This multifaceted approach targets bo
 The Brewing Controversy Over The Proposition That AI Is Nothing More Than Just Normal TechnologyMay 02, 2025 am 11:10 AM
The Brewing Controversy Over The Proposition That AI Is Nothing More Than Just Normal TechnologyMay 02, 2025 am 11:10 AMThere are serious differences in the field of artificial intelligence on this conclusion. Some insist that it is time to expose the "emperor's new clothes", while others strongly oppose the idea that artificial intelligence is just ordinary technology. Let's discuss it. An analysis of this innovative AI breakthrough is part of my ongoing Forbes column that covers the latest advancements in the field of AI, including identifying and explaining a variety of influential AI complexities (click here to view the link). Artificial intelligence as a common technology First, some basic knowledge is needed to lay the foundation for this important discussion. There is currently a large amount of research dedicated to further developing artificial intelligence. The overall goal is to achieve artificial general intelligence (AGI) and even possible artificial super intelligence (AS)
 Model Citizens, Why AI Value Is The Next Business YardstickMay 02, 2025 am 11:09 AM
Model Citizens, Why AI Value Is The Next Business YardstickMay 02, 2025 am 11:09 AMThe effectiveness of a company's AI model is now a key performance indicator. Since the AI boom, generative AI has been used for everything from composing birthday invitations to writing software code. This has led to a proliferation of language mod


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

