
 Technology peripheralsAITo make up for the shortcomings of Transformer planning, Tian Yuandong team's Searchformer became popular
Technology peripheralsAITo make up for the shortcomings of Transformer planning, Tian Yuandong team's Searchformer became popularTo make up for the shortcomings of Transformer planning, Tian Yuandong team's Searchformer became popular

Transformer’s powerful generalization ability has been proven again!
In recent years, Transformer-based structures have shown excellent performance in various tasks and attracted global attention. Using this structure and combining it with large amounts of data, the resulting models such as large language models (LLM) can be well adapted to practical application scenarios.
Despite their success in some areas, Transformer-based structures and LLMs still face challenges, especially in handling planning and inference tasks. Previous research has shown that LLM has difficulties in dealing with multi-step planning tasks or higher-order reasoning tasks.
In order to improve the reasoning and planning performance of Transformer, the research community has also proposed some methods in recent years. One of the most common and effective methods is to simulate the human thinking process: first generate an intermediate "thought" and then output a response. For example, the Chain of Thought (CoT) prompting method encourages the model to predict intermediate steps and perform step-by-step "thinking." The thinking tree (ToT) uses branching strategies and evaluation methods to allow the model to generate multiple different thinking paths, and then select the best path from them. Although these techniques are often effective, research has shown that in many cases these methods degrade model performance due to reasons including self-enforcing.
Techniques that perform well on one dataset may not perform well on other datasets. This may be due to a change in the type of reasoning required, such as a shift from spatial to mathematical or commonsense reasoning.
In contrast, traditional symbolic planning and search techniques demonstrate excellent reasoning capabilities. Furthermore, the solutions computed by these traditional methods often possess formal guarantees, since symbolic planning algorithms usually follow a well-defined rule-based search process.
In order to equip Transformer with complex reasoning capabilities, Meta FAIR Tian Yuandong team recently proposed Searchformer.

Paper title: Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
Paper address : https://arxiv.org/pdf/2402.14083.pdf
Searchformer is a Transformer model, but for multi-step planning tasks such as maze navigation and box pushing, it can calculate The optimal plan can be obtained and the number of search steps used can be far less than that of symbolic planning algorithms such as A* search.
To do this, the team proposed a new method: search dynamics bootstrapping. This method first trains a Transformer model to imitate the search process of A* (as shown in Figure 1), and then fine-tunes it so that it can find the optimal plan with fewer search steps.

In more detail, the first step is to train a Transformer model that imitates A* search. Here, the team’s approach is to run A* search against randomly generated planning task instances. After executing A* When , the team will record the executed calculations and optimal planning and organize them into word sequences, that is, tokens. In this way, the resulting training data set contains the execution trajectory of A* and encodes information about A* itself. Search dynamic information. Then, train a Transformer model so that it can generate these token sequences along the optimal planning for any planning task.
The second step is to use the expert iteration method to further improve the use of the above Searchformer trained on search-enhanced sequences (containing the execution traces of A*). Expert iteration methods allow the Transformer to generate optimal solutions with fewer search steps. This process results in a neural programming algorithm that is implicitly encoded in Among the network weights of the Transformer, and it has a high probability of finding the optimal plan with fewer search steps than A* search. For example, when performing the box pushing task, the new model can answer 93.7% of the test tasks, The number of simultaneous search steps is 26.8% less than A* search on average.
The team stated: This paves the way for Transformer to surpass the traditional symbolic planning algorithm.
Experiment
In order to better understand the impact of the amount of training data and model parameters on the performance of the resulting model, they conducted some ablation studies.
They used two types of data sets to train the model: one type of token The sequence contains only solution (solution-only, which contains only task description and final plan); the other is search-augmented (which contains task description, search tree dynamics and final plan).
In the experiment, the team used a deterministic and non-deterministic variant of the A* search to generate each sequence data set.
Maze Navigation
In the first experiment, the team trained a set of encoder-decoder Transformer models to predict the optimal path in a 30×30 maze.
Figure 4 shows that by predicting intermediate computational steps, more robust performance can be achieved when the amount of data is small.
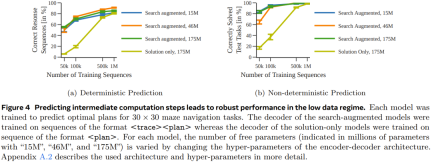
Figure 5 shows the performance of the model trained using only the solutions.

# Figure 6 shows the impact of task difficulty on the performance of each model.

Overall, although the model trained using only the solution can predict the optimal plan when the training data set used is large enough and diverse enough, when the data The search-augmented model performs significantly better when the amount of data is small, and also scales better to more difficult tasks.
Sokoban

In order to test whether it can be obtained on different and more complex tasks (with different tokenization modes) With similar results, the team also generated a Sokoban planning data set for testing.
Figure 7 shows the probability of each model generating the correct plan for each test task.

It can be seen that, like the previous experiment, by training with execution traces, the search-enhanced model outperforms the model trained with only solutions.
Searchformer: Improving search dynamics through bootstrapping
As a final experiment, the team investigated how search-enhanced models can be iteratively improved to rely on fewer search steps. Calculate the optimal plan numerically. The goal here is to shorten the length of the search trajectory while still obtaining the optimal solution.

Figure 8 shows that the newly proposed search dynamic guidance method can iteratively shorten the length of the sequences generated by the Searchformer model.
The above is the detailed content of To make up for the shortcomings of Transformer planning, Tian Yuandong team's Searchformer became popular. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

