
 Technology peripheralsAITsinghua University and Ideal proposed DriveVLM, a visual large language model to improve autonomous driving capabilities
Technology peripheralsAITsinghua University and Ideal proposed DriveVLM, a visual large language model to improve autonomous driving capabilitiesTsinghua University and Ideal proposed DriveVLM, a visual large language model to improve autonomous driving capabilities

In the field of autonomous driving, researchers are also exploring the direction of large models such as GPT/Sora.
Compared with generative AI, autonomous driving is also one of the most active research and development areas in recent AI. A major challenge in building a fully autonomous driving system is AI's scene understanding, which involves complex, unpredictable scenarios such as severe weather, complex road layouts, and unpredictable human behavior.
The current autonomous driving system usually consists of three parts: 3D perception, motion prediction and planning. Specifically, 3D perception is mainly used to detect and track familiar objects, but its ability to identify rare objects and their attributes is limited; while motion prediction and planning mainly focus on the trajectory actions of objects, but usually ignore the relationship between objects and vehicles. decision-level interactions between These limitations may affect the accuracy and safety of autonomous driving systems when handling complex traffic scenarios. Therefore, future autonomous driving technology needs to be further improved to better identify and predict various types of objects, and to plan the vehicle's driving path more effectively to improve the intelligence and reliability of the system
implementation The key to autonomous driving is to transform a data-driven approach into a knowledge-driven approach, which requires training large models with logical reasoning capabilities. Only in this way can the autonomous driving system truly solve the long tail problem and move towards L4 capabilities. Currently, as large models like GPT4 and Sora continue to emerge, the scale effect has also demonstrated powerful few-shot/zero-shot capabilities, which has led people to consider a new development direction.
The latest research paper comes from the Cross Information Institute of Tsinghua University and Li Auto, in which they introduce a new model called DriveVLM. This model is inspired by the visual language model (VLM) emerging in the field of generative artificial intelligence. DriveVLM has demonstrated excellent capabilities in visual understanding and reasoning.
This work is the first in the industry to propose an autonomous driving speed control system. Its method fully combines the mainstream autonomous driving process with a large-scale model process with logical thinking capabilities, and is the first time to successfully deploy a large-scale model to Terminal for testing (based on Orin platform).
DriveVLM covers a Chain-of-Though (CoT) process, including three main modules: scenario description, scenario analysis and hierarchical planning. In the scene description module, language is used to describe the driving environment and identify key objects in the scene; the scene analysis module deeply studies the characteristics of these key objects and their impact on autonomous vehicles; while the hierarchical planning module gradually formulates plans from the elements Actions and decisions are described to waypoints.
These modules correspond to the perception, prediction, and planning steps of traditional autonomous driving systems, but the difference is that they handle object perception, intent-level prediction, and task-level planning, which have been very challenging in the past.
Although VLMs perform well in visual understanding, they have limitations in spatial basis and reasoning, and their computing power requirements pose challenges to the speed of end-side reasoning. Therefore, the authors further propose DriveVLMDual, a hybrid system that combines the advantages of DriveVLM and traditional systems. DriveVLM-Dual optionally integrates DriveVLM with traditional 3D perception and planning modules such as 3D object detectors, occupancy networks, and motion planners, enabling the system to achieve 3D grounding and high-frequency planning capabilities. This dual-system design is similar to the slow and fast thinking processes of the human brain and can effectively adapt to different complexities in driving scenarios.
The new research also further clarifies the definition of scene understanding and planning (SUP) tasks and proposes some new evaluation metrics to evaluate the capabilities of DriveVLM and DriveVLM-Dual in scene analysis and meta-action planning. In addition, the authors performed extensive data mining and annotation work to build an in-house SUP-AD dataset for the SUP task.
After extensive experiments on the nuScenes dataset and our own dataset, the superiority of DriveVLM was demonstrated, especially with a small number of shots. Furthermore, DriveVLM-Dual surpasses state-of-the-art end-to-end motion planning methods.
Paper "DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models"

- Encode continuous frame visual images and interact with LMM through the feature alignment module;
- Start from the scene description to guide the thinking of the VLM model, first guide the time, scene, Static scenes such as lane environments are used to guide key obstacles that affect driving decisions;
- analyzes key obstacles and matches them through traditional 3D detection and VLM-understood obstacles to further improve Confirm the effectiveness of obstacles and eliminate illusions, describe the characteristics of key obstacles in this scenario and their impact on our driving;
Gives key "meta-decisions", such as deceleration, parking, turning left and right, etc., and then gives a description of the driving strategy based on the meta-decisions, and finally gives the future driving trajectory of the host vehicle.
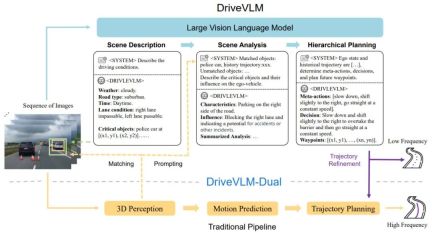
Figure 1. DriveVLM and DriveVLM-Dual model pipeline. A sequence of images is processed by a large visual language model (VLM) to perform special chain-of-thought (CoT) reasoning to derive driving planning results. Large VLM involves a visual transformer encoder and a large language model (LLM). A visual encoder produces image tags; an attention-based extractor then aligns these tags with an LLM; and finally, the LLM performs CoT inference. The CoT process can be divided into three modules: scenario description, scenario analysis, and hierarchical planning.
DriveVLM-Dual is a hybrid system that improves the decision-making and planning capabilities of traditional autonomous driving pipelines by leveraging DriveVLM’s comprehensive understanding of the environment and recommendations for decision trajectories. It incorporates 3D perception results into verbal cues to enhance 3D scene understanding and further refines trajectory waypoints with a real-time motion planner.
Although VLMs are good at identifying long-tail objects and understanding complex scenes, they often struggle to accurately understand the spatial location and detailed motion status of objects, a shortcoming that poses a significant challenge. To make matters worse, the huge model size of VLM results in high latency, hindering the real-time response capability of autonomous driving. To address these challenges, the author proposes DriveVLM-Dual, which allows DriveVLM and traditional autonomous driving systems to cooperate. This new approach involves two key strategies: key object analysis combined with 3D perception to give high-dimensional driving decision information, and high-frequency trajectory refinement.
In addition, to fully realize the potential of DriveVLM and DriveVLMDual in handling complex and long-tail driving scenarios, the researchers formally defined a task called scene understanding planning, as well as a set of evaluation metrics. Furthermore, the authors propose a data mining and annotation protocol to manage scene understanding and planning datasets.
In order to fully train the model, the author has newly developed a set of Drive LLM annotation tools and annotation solutions, which are combined with multiple methods such as automated mining, perceptual algorithm pre-brushing, GPT-4 large model summary and manual annotation. , forming the current set of efficient annotation solutions. Each Clip data contains dozens of annotation contents.

## 图 2 2. Annotation sample of the SUP-AD dataset.
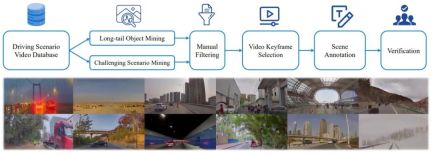
Figure 3. Data mining and annotation pipeline for building scenario understanding and planning datasets (above). Examples of scenarios randomly sampled from the dataset (below) demonstrate the diversity and complexity of the dataset.
SUP-AD is divided into training, validation and testing parts with a ratio of 7.5:1:1.5. The authors train the model on the training split and use newly proposed scene description and meta-action metrics to evaluate the model performance on the validation/test split.
nuScenes dataset is a large-scale urban scene driving dataset with 1000 scenes, each lasting about 20 seconds. Keyframes are annotated uniformly at 2Hz across the entire dataset. Here, the authors adopt displacement error (DE) and collision rate (CR) as indicators to evaluate the model's performance on verification segmentation.
###The authors demonstrate the performance of DriveVLM with several large-scale visual language models and compare them with GPT-4V, as shown in Table 1. DriveVLM utilizes Qwen-VL as its backbone, which achieves the best performance compared to other open source VLMs and is characterized by responsiveness and flexible interaction. The first two large models have been open sourced and used the same data for fine-tuning training. GPT-4V uses complex prompts for prompt engineering. ###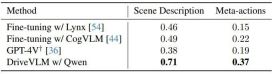
Table 1. Test set results on the SUP-AD data set. The official API of GPT-4V is used here, and for Lynx and CogVLM, training splits are used for fine-tuning.
As shown in Table 2, DriveVLM-Dual achieves state-of-the-art performance on nuScenes planning tasks when paired with VAD. This shows that the new method, although tailored for understanding complex scenes, also performs well in ordinary scenes. Note that DriveVLM-Dual improves significantly over UniAD: the average planning displacement error is reduced by 0.64 meters and the collision rate is reduced by 51%.
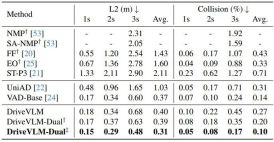
Table 2. Planning results for nuScenes validation dataset. DriveVLM-Dual achieves optimal performance. †Represents perception and occupancy prediction results using Uni-AD. ‡ Indicates working with VAD, where all models take ego states as input. Figure 4. Qualitative results of DriveVLM. The orange curve represents the model's planned future trajectory over the next 3 seconds. 
## 图 7: Various driving scenarios in SUP-AD data concentration.

# 图 9. Sup-AD data concentration cow cluster and herds. A herd of cattle is moving slowly in front of the car, requiring the policy to reason that the car is moving slowly and keeping a safe distance from the cattle. Figure 16. Visualization of DriveVLM output. DriveVLM can accurately detect fallen trees and their locations, then plan an appropriate detour.

The above is the detailed content of Tsinghua University and Ideal proposed DriveVLM, a visual large language model to improve autonomous driving capabilities. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Notepad++7.3.1
Easy-to-use and free code editor

