
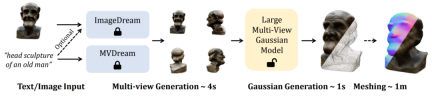
 Technology peripheralsAILarge multi-view Gaussian model LGM: produces high-quality 3D objects in 5 seconds, available for trial play
Technology peripheralsAILarge multi-view Gaussian model LGM: produces high-quality 3D objects in 5 seconds, available for trial playLarge multi-view Gaussian model LGM: produces high-quality 3D objects in 5 seconds, available for trial play

В ответ на продолжающийся рост спроса на инструменты 3D-творчества в Метавселенной в последнее время наблюдается большой интерес к созданию трехмерного контента (3D AIGC). В то же время создание 3D-контента также значительно продвинулось по качеству и скорости.
Хотя текущие генеративные модели с прямой связью могут генерировать 3D-объекты за секунды, их разрешение ограничено интенсивными вычислениями, необходимыми во время обучения, что приводит к низкому качеству генерации Контента. Возникает вопрос: можно ли создать высококачественный 3D-объект с высоким разрешением всего за 5 секунд?

В этой статье исследователи из Пекинского университета, Наньянского технологического университета S-Lab и Шанхайской лаборатории искусственного интеллекта предложили
новую структуру LGM , а именно Большая Гауссова Модель, позволяет создавать трехмерные объекты высокого разрешения и высокого качества из однопросмотровых изображений или ввода текста всего за 5 секунд.
В настоящее время код и веса модели находятся в открытом исходном коде. Исследователи также предоставляют онлайн-демонстрацию, которую каждый может попробовать. 
- ##Название статьи: LGM: Большая многоракурсная гауссова модель для создания 3D-контента высокого разрешения
- Домашняя страница проекта: https://me.kiui.moe/lgm/
- Код: https://github.com/3DTopia/LGM
- Документ: https://arxiv.org/abs/2402.05054
- Онлайн-демо: https://huggingface.co/spaces/ashawkey/LGM
Для достижения такой цели исследователи сталкиваются со следующими двумя проблемами:
При ограниченном объеме вычислений Эффективное трехмерное представление : Существующие работы по созданию 3D-изображений используют NeRF на основе трех плоскостей в качестве конвейера трехмерного представления и рендеринга, что значительно ограничивает плотное моделирование сцены и технологию объемного рендеринга с трассировкой лучей. Его разрешение обучения ( 128×128) делает текстуру окончательно сгенерированного контента размытой и некачественной.
3D-магистральная сеть генерации с высоким разрешением
#: Существующая работа по 3D-генерации использует плотные трансформаторы в качестве магистральной сети для обеспечения достаточной плотности Количество параметры используются для моделирования универсальных объектов, но это в определенной степени жертвует разрешением обучения, что приводит к низкому качеству конечного трехмерного объекта.
С этой целью в данной статье предлагается новый метод синтеза трехмерных представлений высокого разрешения из четырехракурсных изображений, а затем Перспективных изображений или одно- преобразование изображения в многоракурсные модели изображений для поддержки высококачественных задач преобразования текста в 3D и изображения в 3D.
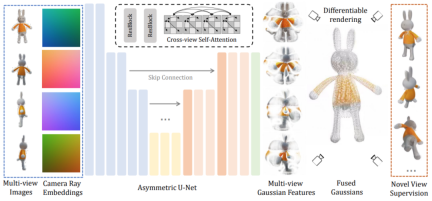
##########################Технически ###LGM основной модуль представляет собой большую многовидовую гауссову модель###. Вдохновленный гауссовским распылением, этот метод использует эффективную и легкую асимметричную сеть U-Net в качестве магистральной сети для прямого прогнозирования гауссовских примитивов высокого разрешения на основе четырехракурсных изображений и, наконец, рендеринга изображений под любым углом обзора. ############ В частности, магистральная сеть U-Net принимает изображения с четырех точек зрения и соответствующие координаты Плакера и выводит фиксированное количество гауссовских функций с нескольких точек зрения. Этот набор гауссовских функций напрямую объединяется с конечным гауссовским элементом, и изображения под разными углами обзора получаются посредством дифференцируемого рендеринга. ############В этом процессе используется механизм перекрестного просмотра для достижения корреляционного моделирования между различными представлениями на картах объектов с низким разрешением, сохраняя при этом меньшие вычислительные затраты. #####################Стоит отметить, что эффективно обучить такую модель в высоком разрешении непросто. Чтобы добиться надежного обучения, исследователи по-прежнему сталкиваются со следующими двумя проблемами. ######First, the three-dimensional consistent multi-view images rendered in the objaverse data set are used in the training phase, while in the inference phase, existing models are directly used to synthesize multi-perspective images from text or images. Since multi-view pictures synthesized based on the model always have the problem of multi-view inconsistency, in order to bridge the gap in this domain, this article proposes a data enhancement strategy based on grid distortion: in the image space, images from three views are Apply random distortion to simulate multi-view inconsistencies.
The second reason is that the multi-view images generated in the inference stage do not strictly guarantee the consistency of the three-dimensional geometry of the camera perspective, so this article also randomly perturbs the camera poses from the three perspectives To simulate this phenomenon, make the model more robust in the inference stage.
Finally, the generated Gaussian primitives are rendered into corresponding images through differentiable rendering, and learned directly end-to-end on the two-dimensional images through supervised learning.
After training is completed, LGM can achieve high-quality Text-to-3D and Image-to-3D through the existing image-to-multi-view or text-to-multi-view diffusion model. Task.

Given the same input text or image, this method can generate a variety of high-quality 3D models.

In order to further support downstream graphics tasks, the researchers also proposed an efficient method to convert the generated Gaussian representation into a smooth and banded representation. Texture Mesh:
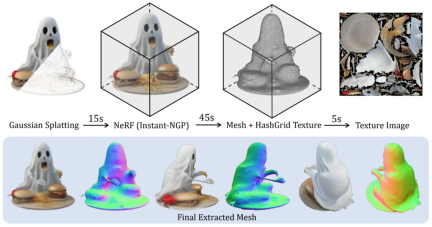
Please refer to the original paper for more details.
The above is the detailed content of Large multi-view Gaussian model LGM: produces high-quality 3D objects in 5 seconds, available for trial play. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

