

 Technology peripheralsAIYou can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.
Technology peripheralsAIYou can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.

When it comes to the future of AI assistants, people can easily think of Jarvis, the AI assistant in the "Iron Man" series. Jarvis shows dazzling functions in the movie. He is not only Tony Stark's right-hand man, but also his bridge to communicate with advanced technology. With the emergence of large-scale models, the way humans use tools is undergoing revolutionary changes, and perhaps we are one step closer to a science fiction scenario. Imagine a multi-modal agent that can directly control the computers around us through keyboard and mouse like humans. How exciting this breakthrough will be.

AI Assistant Jarvis
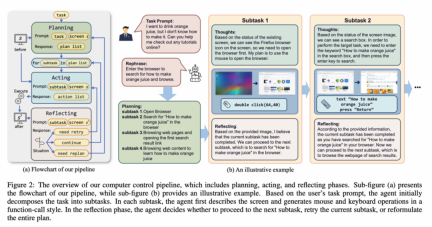
The latest research from the School of Artificial Intelligence of Jilin University "ScreenAgent: A Vision Language Model-driven Computer Control Agent" shows that the imagination of using a visual large language model to directly control the computer GUI has become a reality. This study proposed the ScreenAgent model, which for the first time explored the direct control of computer mouse and keyboard through VLM Agent without the need for additional label assistance, achieving the goal of direct computer operation of large-scale models. In addition, ScreenAgent uses an automated "plan-execute-reflect" process to achieve continuous control of the GUI interface for the first time. This work explores and innovates human-computer interaction methods, and also open-sources resources including data sets, controllers, and training codes with precise positioning information.

- ##Paper address: https://arxiv.org/abs/2402.07945
- Project address: https://github.com/niuzaisheng/ScreenAgent
ScreenAgent is the user Provide convenient online entertainment, shopping, travel and reading experiences. It can also be used as a personal butler to help manage personal computers and achieve quick work. It becomes a powerful office assistant without any effort. Through practical effects, users can understand its functionality.
Take you to surf the Internet and achieve entertainment freedom
##ScreenAgent searches for and plays specified videos online based on user text descriptions :

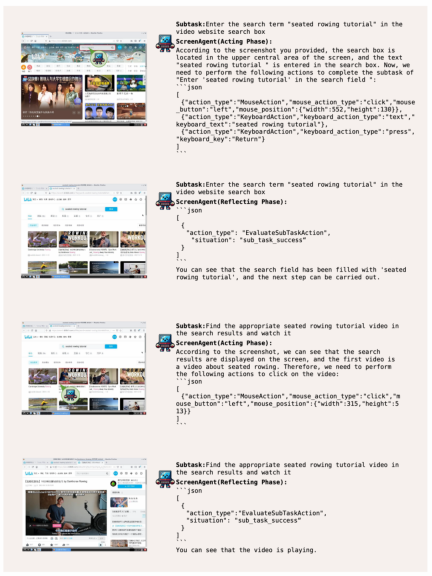
Let ScreenAgent open the Windows event viewer:

In addition, ScreenAgent can use office software. For example, according to the user text description, delete the PPT on the second page that is opened:
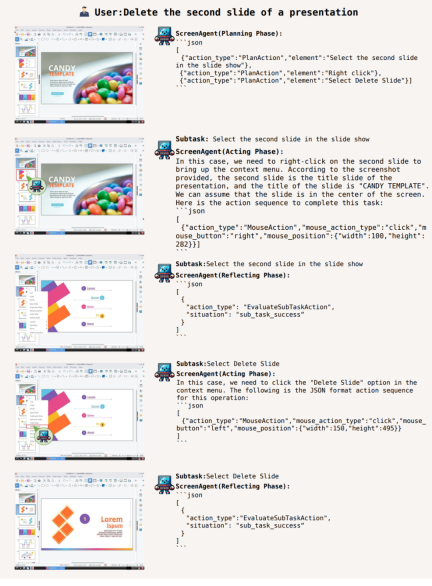
To complete a certain task, planning activities must be done before the task is executed. ScreenAgent can make plans based on the observed images and user needs before starting the task, for example:
Adjust the video playback speed to 1.5 times:
 Search the price of second-hand Magotan cars on the 58 city website:
Search the price of second-hand Magotan cars on the 58 city website:
 In the command line Install xeyes:
In the command line Install xeyes:

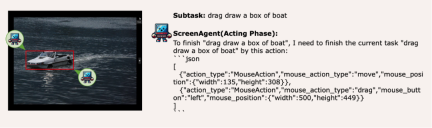
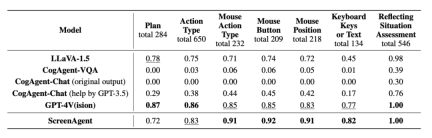
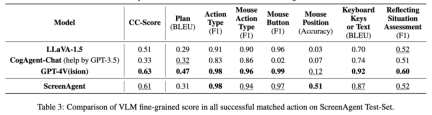
ScreenAgent also retains the ability to visually locate natural objects, and can draw a selection frame of an object by dragging the mouse: In fact, it is not a simple matter to teach the Agent to interact directly with the user graphical interface. It requires the Agent to have tasks at the same time Comprehensive abilities such as planning, image understanding, visual positioning, and tool use. There are certain compromises in existing models or interaction solutions. For example, models such as LLaVA-1.5 lack precise visual positioning capabilities on large-size images; GPT-4V has very strong mission planning, image understanding and OCR capabilities, but refuses to give Get precise coordinates. Existing solutions require manual annotation of additional digital labels on images, and allow the model to select UI elements that need to be clicked, such as Mobile-Agent, UFO and other projects; in addition, models such as CogAgent and Fuyu-8B can support high-resolution images It has input and precise visual positioning capabilities, but CogAgent lacks complete function calling capabilities, and Fuyu-8B lacks language capabilities. In order to solve the above problems, the article proposes to build a new environment for the visual language model agent (VLM Agent) to interact with the real computer screen. In this environment, the agent can observe screenshots and manipulate the graphical user interface by outputting mouse and keyboard actions. In order to guide the VLM Agent to continuously interact with the computer screen, the article constructs an operating process that includes "planning-execution-reflection". During the planning phase, the agent is asked to break down user tasks into subtasks. During the execution phase, the Agent will observe screenshots and give specific mouse and keyboard actions to perform the subtask. The controller will execute these actions and feedback the execution results to the Agent. During the reflection phase, the Agent observes the execution results, determines the current status, and chooses to continue execution, retry, or adjust the plan. This process continues until the task is completed. It is worth mentioning that ScreenAgent does not need to use any text recognition or icon recognition modules, and uses an end-to-end approach to train all the capabilities of the model. ScreenAgent environment refers to the VNC remote desktop connection protocol to design the Agent's action space, including the most basic mouse and keyboard operations, and mouse click operations. All require the Agent to give precise screen coordinates. Compared with calling specific APIs to complete tasks, this method is more general and can be applied to various desktop operating systems and applications such as Windows and Linux Desktop. In order to train the ScreenAgent model, the article is manually annotated with precise visual positioning information ScreenAgent data set. This data set covers a wide range of daily computer tasks, including file operations, web browsing, game entertainment and other scenarios in Windows and Linux Desktop environments. Each sample in the data set is a complete process for completing a task, including action descriptions, screenshots, and specific executed actions. For example, in the case of "adding the cheapest chocolate to the shopping cart" on the Amazon website, you need to first search for keywords in the search box, then use filters to sort prices, and finally add the cheapest items to the shopping cart. The entire dataset contains 273 complete task records. In the experimental analysis part, the author combined ScreenAgent with multiple existing VLM models Comparisons are made from various angles, mainly including two levels, instruction following ability and accuracy of fine-grained action prediction. The instruction following ability mainly tests whether the model can correctly output the action sequence and action type in JSON format. The accuracy of action attribute prediction compares whether the attribute value of each action is predicted correctly, such as the mouse click position, keyboard keys, etc. Instructions follow In terms of command following, the first task of the Agent is to output the correct tool function call according to the prompt word, that is, to output the correct JSON format. In this regard, both ScreenAgent and GPT-4V can follow the command very well. However, the original CogAgent lost the ability to output JSON due to the lack of data support in the form of API calls during visual fine-tuning training. The accuracy of action attribute prediction From the accuracy of action attributes In terms of performance, ScreenAgent has also reached a level comparable to GPT-4V. Notably, ScreenAgent far exceeds existing models in mouse click accuracy. This shows that visual fine-tuning effectively enhances the model's precise positioning ability. Furthermore, we also observe a clear gap between ScreenAgent and GPT-4V in mission planning, which highlights GPT-4V's common sense knowledge and mission planning capabilities. Proposed by the team of the School of Artificial Intelligence of Jilin University The ScreenAgent can control computers in the same way as humans, does not rely on other APIs or OCR models, and can be widely used in various software and operating systems. ScreenAgent can autonomously complete tasks given by the user under the control of the "plan-execution-reflection" process. In this way, users can see every step of task completion and better understand the Agent's behavioral thoughts. The article open sourced the control software, model training code, and data set. On this basis, you can explore more cutting-edge work towards general artificial intelligence, such as reinforcement learning under environmental feedback, Agent's active exploration of the open world, building world models, Agent skill libraries, etc. In addition, AI Agent-driven personal assistants have huge social value, such as helping people with limited limbs use computers, reducing human repetitive digital labor and popularizing computer education. In the future, maybe not everyone can become a superhero like Iron Man, but we may all have an exclusive Jarvis, an intelligent partner who can accompany, assist and guide us in our lives and work. Bringing more convenience and possibilities. 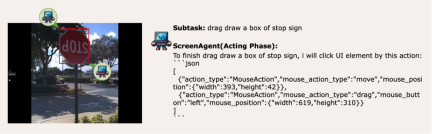
Method

ScreenAgent Dataset


Experimental results

Conclusion
The above is the detailed content of You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.. For more information, please follow other related articles on the PHP Chinese website!

 Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PMHarnessing the Power of Data Visualization with Microsoft Power BI Charts In today's data-driven world, effectively communicating complex information to non-technical audiences is crucial. Data visualization bridges this gap, transforming raw data i
 Expert Systems in AIApr 16, 2025 pm 12:00 PM
Expert Systems in AIApr 16, 2025 pm 12:00 PMExpert Systems: A Deep Dive into AI's Decision-Making Power Imagine having access to expert advice on anything, from medical diagnoses to financial planning. That's the power of expert systems in artificial intelligence. These systems mimic the pro
 Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AM
Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AMFirst of all, it’s apparent that this is happening quickly. Various companies are talking about the proportions of their code that are currently written by AI, and these are increasing at a rapid clip. There’s a lot of job displacement already around
 Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AMThe film industry, alongside all creative sectors, from digital marketing to social media, stands at a technological crossroad. As artificial intelligence begins to reshape every aspect of visual storytelling and change the landscape of entertainment
 How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AM
How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AMISRO's Free AI/ML Online Course: A Gateway to Geospatial Technology Innovation The Indian Space Research Organisation (ISRO), through its Indian Institute of Remote Sensing (IIRS), is offering a fantastic opportunity for students and professionals to
 Local Search Algorithms in AIApr 16, 2025 am 11:40 AM
Local Search Algorithms in AIApr 16, 2025 am 11:40 AMLocal Search Algorithms: A Comprehensive Guide Planning a large-scale event requires efficient workload distribution. When traditional approaches fail, local search algorithms offer a powerful solution. This article explores hill climbing and simul
 OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AM
OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AMThe release includes three distinct models, GPT-4.1, GPT-4.1 mini and GPT-4.1 nano, signaling a move toward task-specific optimizations within the large language model landscape. These models are not immediately replacing user-facing interfaces like
 The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AM
The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AMChip giant Nvidia said on Monday it will start manufacturing AI supercomputers— machines that can process copious amounts of data and run complex algorithms— entirely within the U.S. for the first time. The announcement comes after President Trump si


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Dreamweaver CS6
Visual web development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

