
 Technology peripheralsAIGoogle Gemini 1.5 is launched quickly: MoE architecture, 1 million contexts
Technology peripheralsAIGoogle Gemini 1.5 is launched quickly: MoE architecture, 1 million contextsGoogle Gemini 1.5 is launched quickly: MoE architecture, 1 million contexts

Today, Google announced the launch of Gemini 1.5.
Gemini 1.5 is developed based on research and engineering innovations in Google's foundational models and infrastructure. This release introduces a new Mix of Experts (MoE) architecture to improve the efficiency of training and serving Gemini 1.5.
What Google has launched is the first version of Gemini 1.5 for early testing, namely Gemini 1.5 Pro. It is a medium-sized multimodal model that is scaled and optimized for a variety of tasks. Compared to Google's largest model, 1.0 Ultra, Gemini 1.5 Pro delivers similar performance levels and introduces groundbreaking experimental features to better understand long context.
The number of token context windows for Gemini 1.5 Pro is 128,000. However, starting today, Google is offering a private preview of AI Studio and Vertex AI to a limited number of developers and enterprise customers, allowing them to try it out in a contextual window of up to 1,000,000 tokens. In addition, Google has made several optimizations aimed at improving latency, reducing computing requirements, and improving user experience.
Google CEO Sundar Pichai and Google DeepMind CEO Demis Hassabis gave a special introduction to the new model.

Gemini 1.5 builds on Google’s leading research into Transformer and MoE architectures. The traditional Transformer acts as one large neural network, while the MoE model is divided into smaller "expert" neural networks.
Depending on the type of input given, the MoE model learns to selectively activate only the most relevant expert paths in its neural network. This specialization greatly increases the efficiency of the model. Google has been an early adopter and pioneer of deep learning MoE technology through research on sparse gated MoE, GShard-Transformer, Switch-Transformer, M4, and more.
Google’s latest innovations in model architecture enable Gemini 1.5 to learn complex tasks faster and maintain quality, while training and serving more efficiently. These efficiencies are helping Google teams iterate, train, and deliver more advanced versions of Gemini faster than ever before, and are working on further optimizations.
" of artificial intelligence models" "Context windows" are composed of tokens, which are the building blocks for processing information. A token can be an entire part or subpart of text, image, video, audio, or code. The larger the model's context window, the more information it can receive and process in a given prompt, making its output more consistent, relevant, and useful.
Through a series of machine learning innovations, Google has increased the context window capacity of 1.5 Pro well beyond the original 32,000 tokens of Gemini 1.0. The large model can now run in production with up to 1 million tokens.
This means the 1.5 Pro can handle large amounts of information at once, including 1 hour of video, 11 hours of audio, over 30,000 lines of code, or a code base of over 700,000 words . In Google's research, up to 10 million tokens were also successfully tested.
1.5 Pro Can perform within a given prompt Seamlessly analyze, categorize and summarize large amounts of content. For example, when given a 402-page transcript of the Apollo 11 moon landing mission, it could reason about dialogue, events, and details throughout the document.

1.5 Pro can perform highly complex understanding and reasoning tasks across different modalities, including video. For example, when given a 44-minute silent film by Buster Keaton, the model could accurately analyze various plot points and events, even reasoning about small details in the film that were easily overlooked.
1.5 Pro Can perform highly complex understanding and reasoning tasks on different modalities including video. For example, when given a 44-minute silent film by Buster Keaton, the model could accurately analyze various plot points and events, even reasoning about small details in the film that were easily overlooked.
1.5 Pro Can perform highly complex understanding and reasoning tasks on different modalities including video. For example, when given a 44-minute silent film by Buster Keaton, the model could accurately analyze various plot points and events, even reasoning about small details in the film that were easily overlooked.
 The Gemini 1.5 Pro could identify 44 minutes of scenes from Buster Keaton's silent films when given simple line drawings as reference material for real-life objects.
The Gemini 1.5 Pro could identify 44 minutes of scenes from Buster Keaton's silent films when given simple line drawings as reference material for real-life objects.
Gemini 1.5 Pro maintains a high level of performance even as the context window increases.
In the NIAH assessment, where a small piece of text containing a specific fact or statement was intentionally placed within a very long block of text, 1.5 Pro found the embedding 99% of the time The text of , there are only 1 million tokens in the data block.
Gemini 1.5 Pro also demonstrates impressive "in-context learning" skills, meaning it can learn from long prompts Learn new skills from information without the need for additional fine-tuning. Google tested this skill on the MTOB (Translation from One Book) benchmark, which shows the model's ability to learn from information it has never seen before. When given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model can learn to translate English into Kalamang at a level similar to a human learning the same content.
Since 1.5 Pro’s long context window is a first for a large model, Google is constantly developing new evaluations and benchmarks to test its novel features.
For more details, see the Gemini 1.5 Pro Technical Report.
Technical report address: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
Starting today, Google is making 1.5 Pro preview available to developers and enterprise customers through AI Studio and Vertex AI.
In the future, when the model goes to wider release, Google will launch 1.5 Pro with a standard 128,000 token context window. Soon, Google plans to introduce pricing tiers starting with the standard 128,000 context windows and scaling up to 1 million tokens as it improves the model.
Early testers can try 1 million token context windows for free during testing, and significant speed improvements are coming.
Developers interested in testing 1.5 Pro can register now in AI Studio, while enterprise customers can contact their Vertex AI account team.
The above is the detailed content of Google Gemini 1.5 is launched quickly: MoE architecture, 1 million contexts. For more information, please follow other related articles on the PHP Chinese website!

 10 Applications of LLM Agents for BusinessApr 13, 2025 am 09:34 AM
10 Applications of LLM Agents for BusinessApr 13, 2025 am 09:34 AMIntroduction Large language models or LLMs are a game-changer especially when it comes to working with content. From supporting summarization, translation, and generation, LLMs like GPT-4, Gemini, and Llama have made it simple
 How LLM Agents are Reshaping Workplace?Apr 13, 2025 am 09:33 AM
How LLM Agents are Reshaping Workplace?Apr 13, 2025 am 09:33 AMIntroduction Large language model (LLM) agents are the latest innovation boosting workplace business efficiency. They automate repetitive activities, boost collaboration, and provide useful insights across departments. Unlike
 Setup Mage AI with PostgresApr 13, 2025 am 09:31 AM
Setup Mage AI with PostgresApr 13, 2025 am 09:31 AMImagine yourself as a data professional tasked with creating an efficient data pipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lende
 Is Google's Imagen 3 the Future of AI Image Creation?Apr 13, 2025 am 09:29 AM
Is Google's Imagen 3 the Future of AI Image Creation?Apr 13, 2025 am 09:29 AMIntroduction Text-to-image synthesis and image-text contrastive learning are two of the most innovative multimodal learning applications recently gaining popularity. With their innovative applications for creative image creati
 Top 10 YouTube Channels to Learn Excel - Analytics VidhyaApr 13, 2025 am 09:27 AM
Top 10 YouTube Channels to Learn Excel - Analytics VidhyaApr 13, 2025 am 09:27 AMIntroduction Excel is indispensable for boosting productivity and efficiency across all the fields. The wide range of resources on YouTube can help learners of all levels find helpful tutorials specific to their needs. This ar
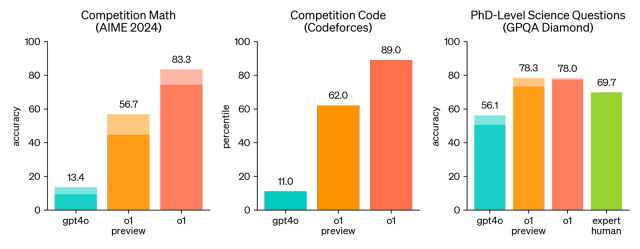 OpenAI o1: A New Model That 'Thinks' Before Answering ProblemsApr 13, 2025 am 09:26 AM
OpenAI o1: A New Model That 'Thinks' Before Answering ProblemsApr 13, 2025 am 09:26 AMHave you heard the big news? OpenAI just rolled out preview of a new series of AI models – OpenAI o1 (also known as Project Strawberry/Q*). These models are special because they spend more time “thinking” befor
 Claude vs Gemini: The Comprehensive Comparison - Analytics VidhyaApr 13, 2025 am 09:20 AM
Claude vs Gemini: The Comprehensive Comparison - Analytics VidhyaApr 13, 2025 am 09:20 AMIntroduction Within the quickly changing field of artificial intelligence, two language models, Claude and Gemini, have become prominent competitors, each providing distinct advantages and skills. Although both models can mana
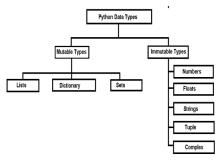 Mutable vs Immutable Objects in Python - Analytics VidhyaApr 13, 2025 am 09:15 AM
Mutable vs Immutable Objects in Python - Analytics VidhyaApr 13, 2025 am 09:15 AMIntroduction Python is an object-oriented programming language (or OOPs).In my previous article, we explored its versatile nature. Due to this, Python offers a wide variety of data types, which can be broadly classified into m


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Mac version
God-level code editing software (SublimeText3)

