
 Technology peripheralsAIThe generation speed is twice as fast as SDXL, and it can also run on 9GB GPU. Stable Cascade is here to improve the price/performance ratio.
Technology peripheralsAIThe generation speed is twice as fast as SDXL, and it can also run on 9GB GPU. Stable Cascade is here to improve the price/performance ratio.
Hardware requirements are getting lower and lower, and the generation speed is getting faster and faster.
As a pioneer of text-to-image, Stability AI not only leads the trend, but also continues to make new breakthroughs in model quality. This time, it achieved a breakthrough in cost performance.
Just a few days ago, Stability AI made another new move: the research preview version of Stable Cascade was launched. This text-to-image model innovates by introducing a three-stage approach that sets new benchmarks for quality, flexibility, fine-tuning, and efficiency, with a focus on further removing hardware barriers. In addition, Stability AI releases training and inference code that allows further customization of the model and its output. The model is available for inference in the diffusers library. This model is released under a non-commercial license, allowing non-commercial use only.

- Original link: https://stability.ai/news/introducing-stable-cascade
- Code address: https://github.com/Stability-AI/StableCascade
- Experience address: https://huggingface.co/spaces/multimodalart/stable-cascade

## Source: https://twitter.com/multimodalart/status/1757391981074903446Stable Cascade is extremely fast to generate. X platform user @GozukaraFurkan posted that it only requires about 9GB of GPU memory, and the speed can still be maintained well.

Netizen During the generation process, it was found that the new model has significantly improved in composition and details, and text generation has made great progress: the accuracy of generating shorter words/phrases is relatively high, and long sentences can also be completed with a certain probability (English only). The integration of text and images is also very good.
 ## Picture source: https://twitter.com/ZHOZHO672070/status/1757779330443215065
## Picture source: https://twitter.com/ZHOZHO672070/status/1757779330443215065
## 
#User @AIWarper tried a few different Artist Style Test.
prompt: Nightmare on Elm Street. Artist style references are as follows: Makoto Shinkai top left, Tomer Hanuka bottom left, Raphael Kirchner top right, Takato Yamamoto bottom right.
However, when generating the character's face, you can find that the character's skin details are not very good, and it feels like "tenth-level skin grinding".
## Source: https://twitter.com/vitor_dlucca/status/1757511080287355093

Stable Cascade differs from the Stable Diffusion model family in that it is built on a pipeline consisting of three different models: Stages A, B, and C. This architecture can perform hierarchical compression of images and utilize a highly compressed latent space to achieve superior output. How do these parts fit together?
The latent image generator stage (stage C) converts user input into a compact 24x24 latent representation, which is then passed to the latent decoder stage (stages A and B) for compressing the image, similar to VAE in Stable Diffusion works, but enables higher compression.
By decoupling text condition generation (stage C) from decoding to high-resolution pixel space (stages A and B), we can complete additional training or fine-tuning on stage C, including ControlNets and LoRA , the cost can be reduced to one sixteenth of that of training a similarly sized Stable Diffusion model. Stages A and B can optionally be fine-tuned for additional control, but this will be similar to fine-tuning the VAE in the Stable Diffusion model. In most cases, the benefits of doing so are minimal. Therefore, for most purposes, Stability AI officially recommends training only Phase C and using the original state from Phases A and B.
Phases C and B will release two different models: 1B and 3.6B parameter models for Phase C, and 700M and 1.5B parameter models for Phase B. A model with 3.6B parameters is recommended for Stage C as this model has the highest quality output. However, for those who wish to have the minimum hardware requirements, a 1B parameter version is available. For Stage B, both releases achieve good results, but the 1.5B parameter version performs better in terms of reconstruction detail. Thanks to Stable Cascade's modular approach, the expected VRAM requirements for inference can be kept to about 20GB. This can be further reduced by using smaller variants, with the caveat that this may also reduce the final output quality.
Comparison
In the evaluation, Stable Cascade performed best in terms of prompt alignment and aesthetic quality compared to almost all models compared. The figure below shows the results of human evaluation using a mixture of parti-prompts and aesthetic prompts:

Stable Cascade (30 inference steps) vs. Playground v2 (50 inference steps), SDXL (50 inference steps), SDXL Turbo (1 inference step) and Würstchen v2 (30 inference steps) compared

# Stable Cascade, SDXL, Playground V2 and SDXL Turbo Difference and higher compression potential space are demonstrated. Even though the largest model has 1.4B more parameters than Stable Diffusion XL, it still has faster inference times.
Additional FeaturesIn addition to standard text-to-image generation, Stable Cascade can also generate image variations and image-to-image generation. Image variants extract image embeddings from a given image using CLIP and return them to the model. The image below is sample output. The image on the left shows the original image, while the four to its right are the generated variants.
#Image to image generates an image by simply adding noise to a given image and then using that as a starting point. Below is an example of adding noise to the image on the left and then generating it from there.
Code for training, fine-tuning, ControlNet and LoRA
With the release of Stable Cascade, Stability AI will be released for training ,fine-tuned all code for ControlNet and LoRA to reduce the ,requirements for further experimentation with this architecture. Here are some ControlNets that will be released with the model: Patch/Expand: Enter an image and add a mask to match the text prompt. The model will then fill in the masked portion of the image based on the provided text hints.
#Canny Edge: Generates a new image based on the edges of an existing image input to the model. According to Stability AI testing, it can also scale sketches.
 # This is the sketch of the input model, and the bottom is output results
# This is the sketch of the input model, and the bottom is output results
## 2x super-resolution: Upscaling the resolution of an image to 2x its side length, e.g. converting a 1024 x 1024 image to a 2048 x 2048 output, can also be used for the latent representation generated by stage C. Do you like this price/performance ratio? 
The above is the detailed content of The generation speed is twice as fast as SDXL, and it can also run on 9GB GPU. Stable Cascade is here to improve the price/performance ratio.. For more information, please follow other related articles on the PHP Chinese website!

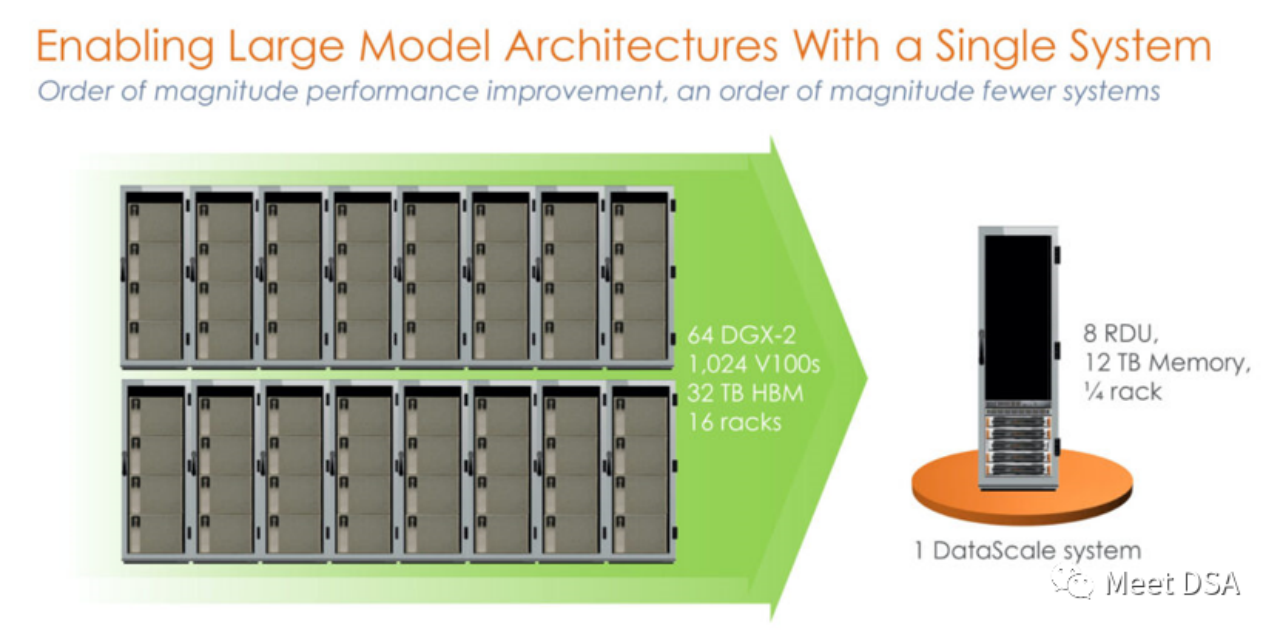 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
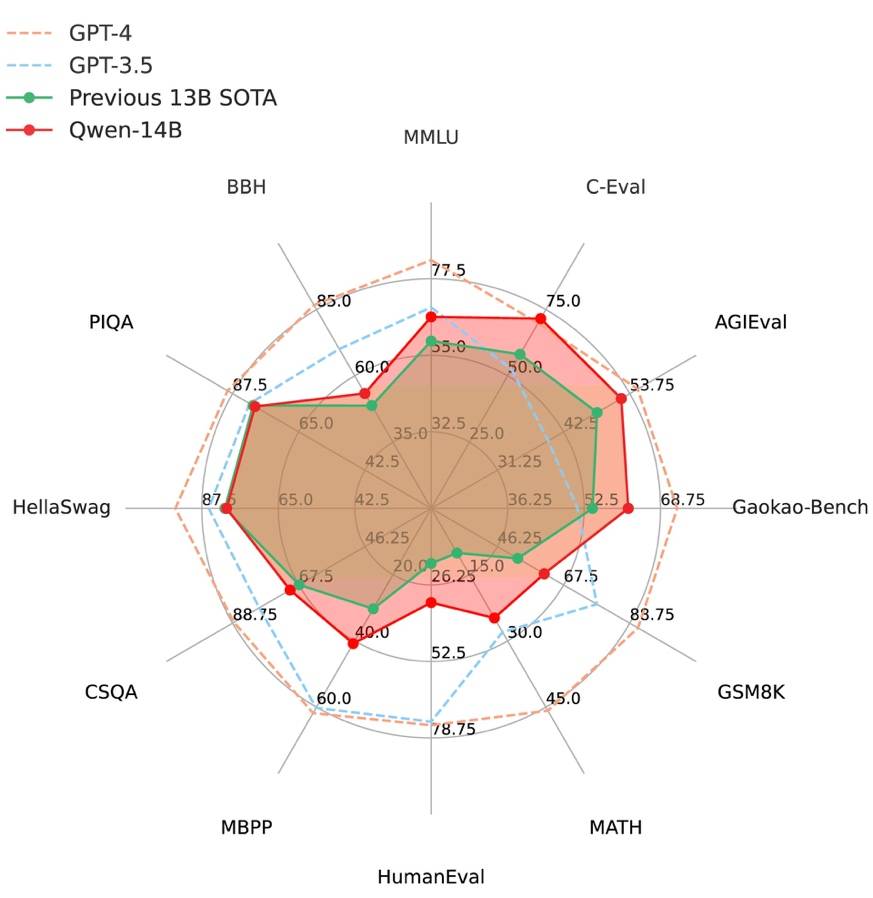 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
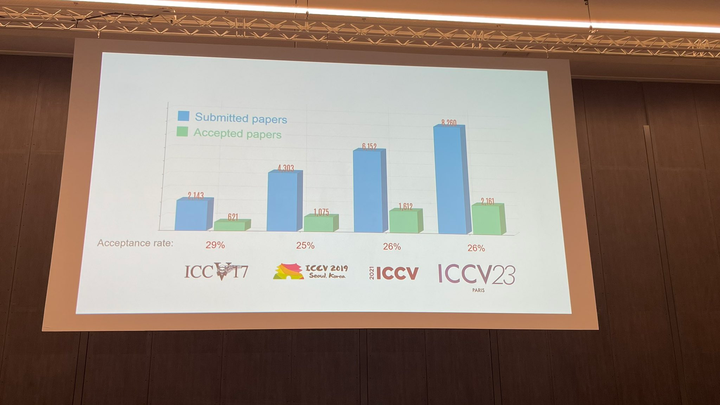 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
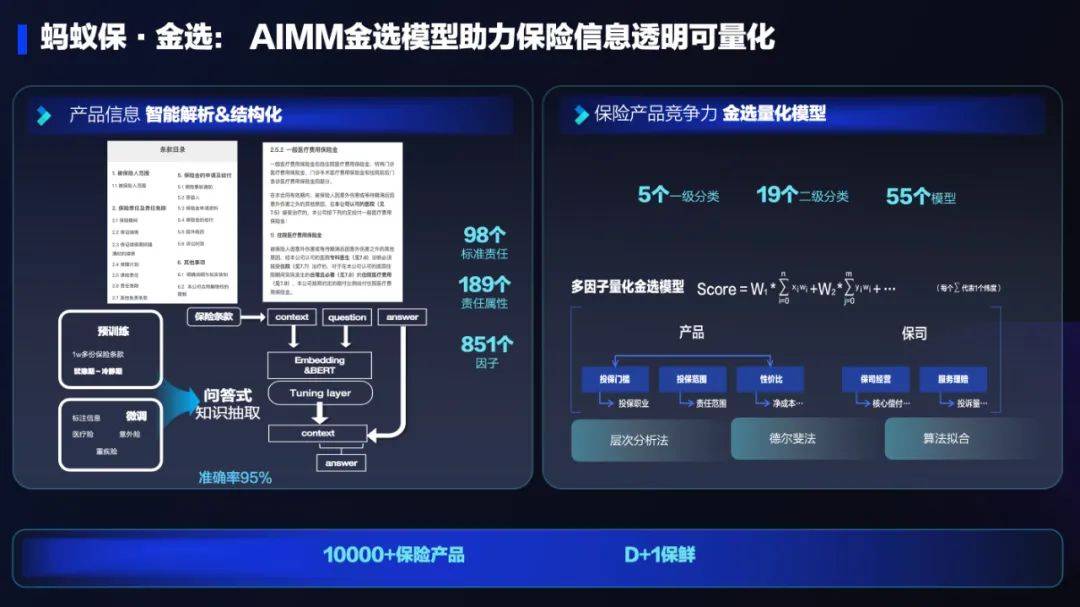 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

