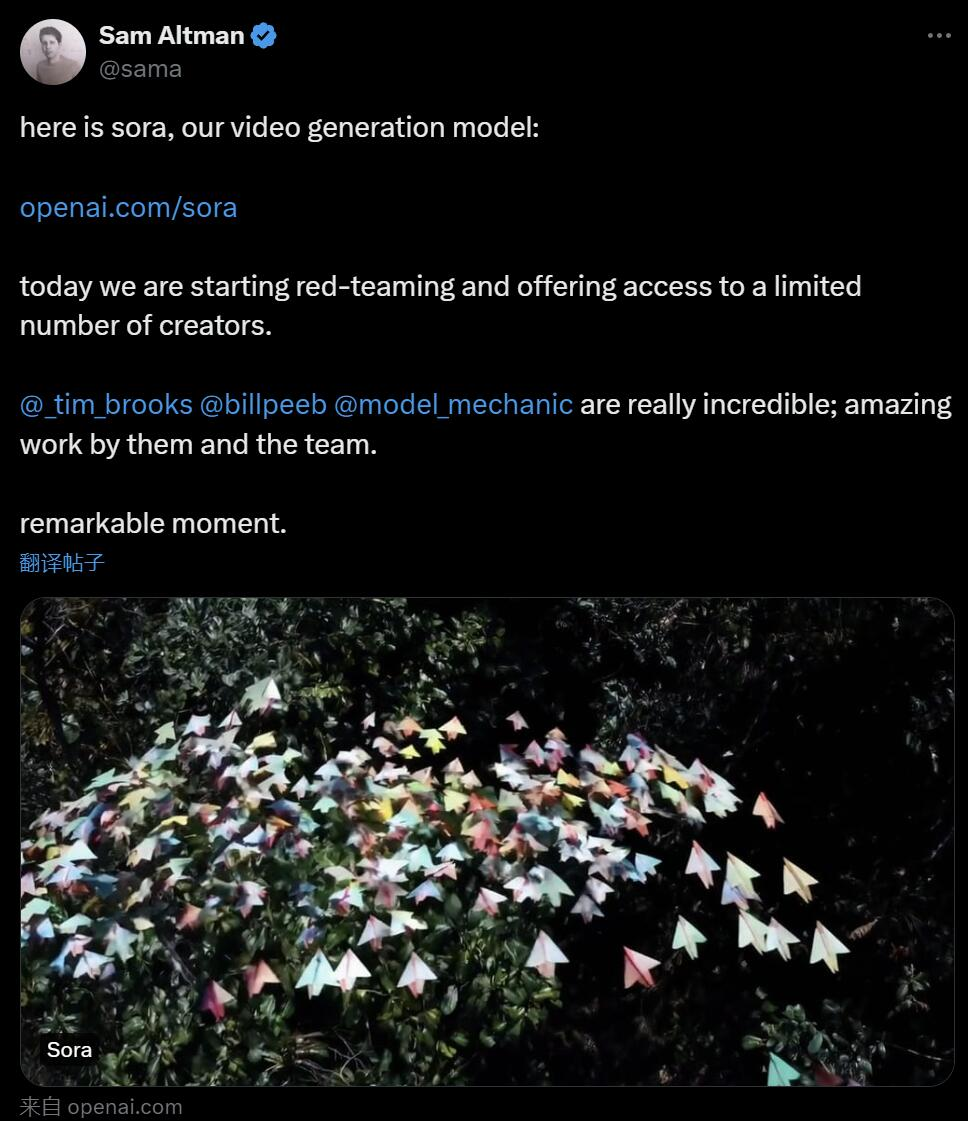
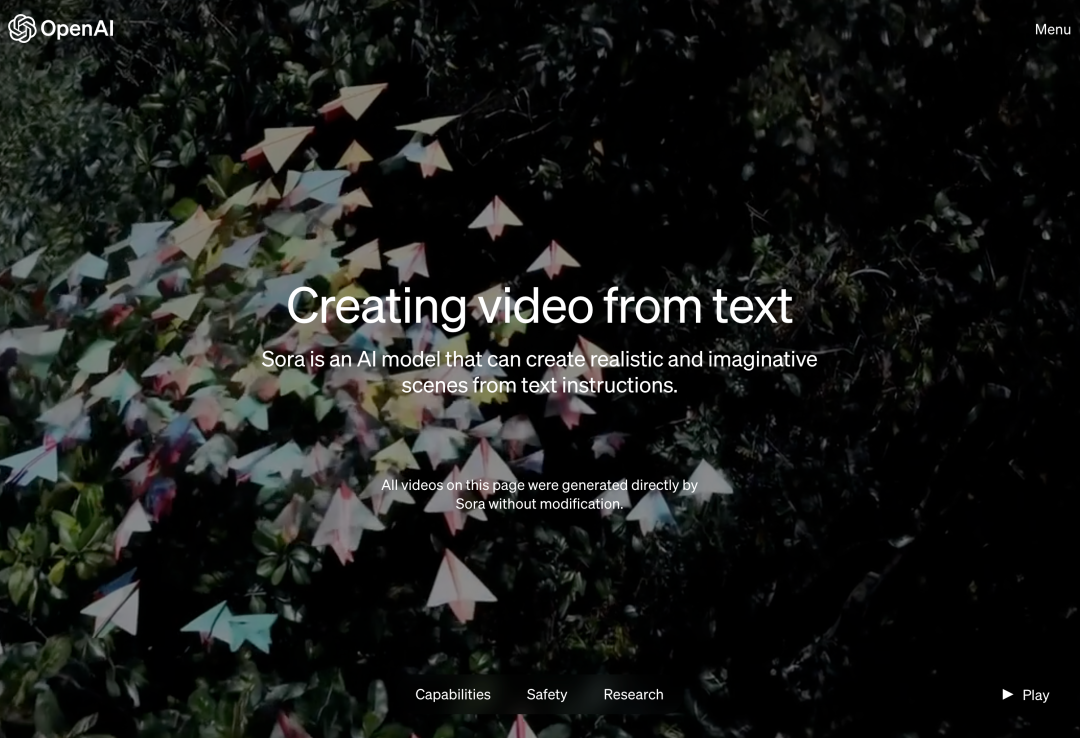
Early this morning Beijing time, OpenAI officially released the text-to-video generation model Sora. Following Runway, Pika, Google and Meta, OpenAI finally joined the war in the field of video generation. After the news about Sam Altman was released, people saw the AI-generated video effects demonstrated by OpenAI engineers for the first time. People lamented: Is the era of Hollywood over? OpenAI claims that given a short or detailed description or a still image, Sora can generate a movie-like 1080p scene with multiple characters, different Type of action and background details. #What is so special about Sora? It has a deep understanding of language, able to accurately interpret prompts and generate engaging characters that express vibrant emotions. At the same time, Sora can not only understand the user's request in the prompt, but also get the way it exists in the physical world. In the official blog, OpenAI provides many video examples generated by Sora, demonstrating impressive effects, at least comparable to text generation video technology that has appeared before. Than this. For starters, Sora can generate videos in various styles (e.g., photorealistic, animated, black and white), up to one minute long - than big Most text-to-video models are much longer. The videos maintain a reasonable consistency, and they don't always succumb to so-called "AI weirdness," such as objects moving in physically impossible directions. . First let Sora generate a video of the Chinese Dragon Dance in the Year of the Dragon.
For example, enter prompt: historical footage of the California Gold Rush.
#Enter prompt: Close-up view of a glass ball with a zen garden inside. Inside the sphere is a dwarf creating patterns in the sand.
Enter prompt: Extreme close-up of a 24-year-old woman blinking, standing in Marrakech during the Magic Hour, film shot in 70mm, depth of field, vibrant colors, cinema .
Input prompt: The reflection in the train window passing through the suburbs of Tokyo.
Enter promot: The life story of a robot in a cyberpunk setting.
The picture is too real and too weird at the same timeBut OpenAI admits that the current model also has weaknesses. It may have difficulty accurately simulating physical phenomena in complex scenes, and it may fail to understand specific cause-and-effect relationships. The model can also confuse the spatial details of cues, such as left and right, and can have difficulty accurately describing events over time, such as following a specific camera trajectory. For example, they found that animals and people appeared spontaneously during the generation process, especially in scenes containing many entities. In the following example, Prompt was originally "Five gray wolf pups playing and chasing each other on a remote gravel road surrounded by grass. The pups were running and jumping. , chasing, biting, and playing with each other." But the "copy and paste" picture generated is very reminiscent of some mysterious ghost legends:
There is also the following example. Before and after blowing out the candle, the flame did not change at all, which revealed a strangeness:
We know very little about the details of the model behind Sora. According to the OpenAI blog, more information will be released in subsequent technical papers. Some basic information was revealed in the blog: Sora is a diffusion model that generates videos that initially look like static noise, and then removes the noise through multiple steps, Convert videos step by step. Midjourney and Stable Diffusion's image and video generators are also based on diffusion models. But we can see that the quality of the videos generated by OpenAI Sora is much better. Sora feels like it's creating a real video, whereas previous models from these competitors felt like stop-motion animations of AI-generated images. #Sora can generate the entire video in one go or extend the generated video to make it longer. By having the model foresee multiple frames at a time, OpenAI solves the challenging problem of ensuring that a subject remains intact even if it temporarily leaves the line of sight. Similar to the GPT model, Sora also uses a transformer architecture to achieve excellent scaling performance. #OpenAI represents videos and images as a collection of smaller data units called patches, each patch is similar to a token in GPT. By unifying data representation, OpenAI can train diffusion transformers on a wider range of visual data than ever before, including different durations, resolutions, and aspect ratios. Sora builds on past research on the DALL・E and GPT models. It uses the recapitulation technology from DALL・E 3 to generate highly descriptive subtitles for visual training data. As a result, the model is able to more faithfully follow the user's textual cues in the generated videos. In addition to being able to generate videos based solely on text descriptions, the model can generate videos based on existing static images and accurately and meticulously animate the image content. The model can also extract existing videos and expand them or fill in missing frames. Reference link: https://openai.com/soraThe above is the detailed content of Spring Festival gift package! OpenAI releases its first video generation model, a 60-second high-definition masterpiece that has netizens impressed. For more information, please follow other related articles on the PHP Chinese website!