
Home >System Tutorial >LINUX >Linux kernel's CPU load balancing mechanism: principles, processes and optimizations
Linux kernel's CPU load balancing mechanism: principles, processes and optimizations

- 王林forward
- 2024-02-09 13:50:111409browse
CPU load balancing refers to allocating running processes or tasks to different CPUs in a multi-core or multi-processor system so that the load of each CPU is balanced as much as possible, thereby improving system performance and efficiency. . CPU load balancing is an important function of the Linux kernel. It allows the Linux system to take full advantage of multi-core or multi-processor to adapt to different application scenarios and needs. But, do you really understand the CPU load balancing mechanism of the Linux kernel? Do you know its working principle, process and optimization method? This article will introduce you to the relevant knowledge of the CPU load balancing mechanism of the Linux kernel in detail, allowing you to better use and understand this powerful kernel function under Linux.
It is still caused by a magical process scheduling problem. Please refer to the analysis of the Linux process group scheduling mechanism. The group scheduling mechanism is clearly seen. It is found that during the restart process, many kernel call stacks are blocked on the double_rq_lock function, and double_rq_lock is load_balance. It was triggered. It was suspected that there was a problem with inter-core scheduling at that time, and multi-core interlocking occurred in a certain responsible scenario. Later, I looked at the code implementation under CPU load balancing and wrote a summary.
Kernel code version: kernel-3.0.13-0.27.
The kernel code function starts from the load_balance function. From the load_balance function, you can find the schedule function here by looking at the functions that reference it. From here, look down. There is the following sentence in __schedule.
if (unlikely(!rq->nr_running)) idle_balance(cpu, rq);
It can be seen from the above when the kernel will try to perform CPU load balancing: that is, when the current CPU run queue is NULL.
There are two methods of CPU load balancing: pull and push, that is, the idle CPU pulls a process from other busy CPU queues to the current CPU queue; or the busy CPU queue pushes a process to the idle CPU queue. What idle_balance does is pull. The specific push will be mentioned below.
In idle_balance, there is a proc valve to control whether the current CPU is pull:
if (this_rq->avg_idle return;
The proc control file corresponding to sysctl_sched_migration_cost is /proc/sys/kernel/sched_migration_cost. The switch means that if the CPU queue is idle for more than 500us (sysctl_sched_migration_cost default value), pull will be performed, otherwise it will be returned.
for_each_domain(this_cpu, sd) traverses the scheduling domain where the current CPU is located. It can be intuitively understood as a CPU group, similar to task_group. Inter-core balance refers to the balance within the group. There is a contradiction in load balancing: the frequency of load balancing and the hit rate of the CPU cache are contradictory. The CPU scheduling domain divides each CPU into groups with different levels. The balance achieved at the low level will never be upgraded to the high level for processing, which avoids Affects cache hit rate.
Illustrations are as follows;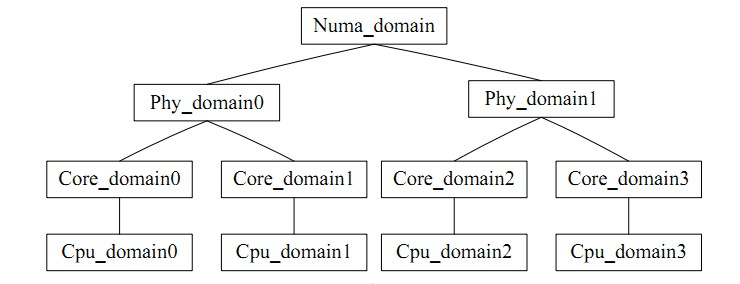
Finally get to the point through load_balance.
First obtain the busiest scheduling group in the current scheduling domain through find_busiest_group. First, update_sd_lb_stats updates the status of sd, that is, traverses the corresponding sd and fills the structure data in sds, as follows:
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *this; /* Local group in this sd */
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_pwr; /* Total power of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
/** Statistics of this group */
unsigned long this_load; //当前调度组的负载
unsigned long this_load_per_task; //当前调度组的平均负载
unsigned long this_nr_running; //当前调度组内运行队列中进程的总数
unsigned long this_has_capacity;
unsigned int this_idle_cpus;
/* Statistics of the busiest group */
unsigned int busiest_idle_cpus;
unsigned long max_load; //最忙的组的负载量
unsigned long busiest_load_per_task; //最忙的组中平均每个任务的负载量
unsigned long busiest_nr_running; //最忙的组中所有运行队列中进程的个数
unsigned long busiest_group_capacity;
unsigned long busiest_has_capacity;
unsigned int busiest_group_weight;
do
{
local_group = cpumask_test_cpu(this_cpu, sched_group_cpus(sg));
if (local_group) {
//如果是当前CPU上的group,则进行赋值
sds->this_load = sgs.avg_load;
sds->this = sg;
sds->this_nr_running = sgs.sum_nr_running;
sds->this_load_per_task = sgs.sum_weighted_load;
sds->this_has_capacity = sgs.group_has_capacity;
sds->this_idle_cpus = sgs.idle_cpus;
} else if (update_sd_pick_busiest(sd, sds, sg, &sgs, this_cpu)) {
//在update_sd_pick_busiest判断当前sgs的是否超过了之前的最大值,如果是
//则将sgs值赋给sds
sds->max_load = sgs.avg_load;
sds->busiest = sg;
sds->busiest_nr_running = sgs.sum_nr_running;
sds->busiest_idle_cpus = sgs.idle_cpus;
sds->busiest_group_capacity = sgs.group_capacity;
sds->busiest_load_per_task = sgs.sum_weighted_load;
sds->busiest_has_capacity = sgs.group_has_capacity;
sds->busiest_group_weight = sgs.group_weight;
sds->group_imb = sgs.group_imb;
}
sg = sg->next;
} while (sg != sd->groups);
The reference criterion for deciding to select the busiest group in the scheduling domain is the sum of the loads on all CPUs in the group. The reference criterion for finding the busy run queue in the group is the length of the CPU run queue, that is, the load. , and the larger the load value, the busier it is. During the balancing process, by comparing the load status of the current queue with the previously recorded busiest, these variables are updated in a timely manner so that the busiest always points to the busiest group in the domain for easy search.
Average load calculation of scheduling domain
sds.avg_load = (SCHED_POWER_SCALE * sds.total_load) / sds.total_pwr; if (sds.this_load >= sds.avg_load) goto out_balanced;
In the process of comparing the load size, when it is found that the busiest group in which the currently running CPU is located is empty, or the currently running CPU queue is the busiest, or the load of the current CPU queue is not less than that in this group When the average load of the busiest group is less than the average load of the scheduling domain, a NULL value will be returned, that is, balancing between groups is not required; when the load of the busiest group is less than the average load of the scheduling domain, only a small range of Load balancing; when the amount of tasks to be transferred is less than the average load of each process, the busiest scheduling group is obtained.
Then find the busiest scheduling queue in find_busiest_queue, traverse all CPU queues in the group, and find the busiest queue by comparing the loads of each queue in turn.
or_each_cpu(i, sched_group_cpus(group)) {
/*rq->cpu_power表示所在处理器的计算能力,在函式sched_init初始化时,会把这值设定为SCHED_LOAD_SCALE (=Nice 0的Load Weight=1024).并可透过函式update_cpu_power (in kernel/sched_fair.c)更新这个值.*/
unsigned long power = power_of(i);
unsigned long capacity = DIV_ROUND_CLOSEST(power,SCHED_POWER_SCALE);
unsigned long wl;
if (!cpumask_test_cpu(i, cpus))
continue;
rq = cpu_rq(i);
/*获取队列负载cpu_rq(cpu)->load.weight;*/
wl = weighted_cpuload(i);
/*
* When comparing with imbalance, use weighted_cpuload()
* which is not scaled with the cpu power.
*/
if (capacity && rq->nr_running == 1 && wl > imbalance)
continue;
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu power, so that
* the load can be moved away from the cpu that is potentially
* running at a lower capacity.
*/
wl = (wl * SCHED_POWER_SCALE) / power;
if (wl > max_load) {
max_load = wl;
busiest = rq;
}
Through the above calculation, we get the busiest queue.
When the busiest->nr_running number is greater than 1, the pull operation is performed. Before the pull, the move_tasks are locked by double_rq_lock.
double_rq_lock(this_rq, busiest); ld_moved = move_tasks(this_rq, this_cpu, busiest, imbalance, sd, idle, &all_pinned); double_rq_unlock(this_rq, busiest);
The move_tasks process pull task is allowed to fail, that is, move_tasks->balance_tasks. Here, there is the sysctl_sched_nr_migrate switch to control the number of process migrations. The corresponding proc is /proc/sys/kernel/sched_nr_migrate.
Below is the can_migrate_task function to check whether the selected process can be migrated. There are three reasons for migration failure. 1. The migrated process is running; 2. The process is core-bound and cannot be migrated to the target CPU; 3. The process The cache is still hot, and this is also to ensure the cache hit rate.
/*关于cache cold的情况下,如果迁移失败的个数太多,仍然进行迁移
* Aggressive migration if:
* 1) task is cache cold, or
* 2) too many balance attempts have failed.
*/
tsk_cache_hot = task_hot(p, rq->clock_task, sd);
if (!tsk_cache_hot ||
sd->nr_balance_failed > sd->cache_nice_tries) {
#ifdef CONFIG_SCHEDSTATS
if (tsk_cache_hot) {
schedstat_inc(sd, lb_hot_gained[idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
#endif
return 1;
}
Determine whether the process cache is valid and determine the conditions. The running time of the process is greater than the proc control switch sysctl_sched_migration_cost, corresponding to the directory /proc/sys/kernel/sched_migration_cost_ns
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
The above is the detailed content of Linux kernel's CPU load balancing mechanism: principles, processes and optimizations. For more information, please follow other related articles on the PHP Chinese website!