

 Backend DevelopmentGolangWhy is downloading in memory slower than downloading in the file system from aws s3?
Backend DevelopmentGolangWhy is downloading in memory slower than downloading in the file system from aws s3?

Why is downloading in memory slower than downloading in the file system from AWS S3? When downloading files, we usually choose to download from an AWS S3 bucket to the local file system. However, sometimes we find that using the in-memory download method is slower than downloading directly from S3 to the file system. This is because downloading in memory involves some extra steps and resource consumption. First, in-memory downloads require reading the file contents into memory and then writing them to the file system. This process involves additional memory operations and IO operations, which will cause the download speed to be slower than downloading directly from S3 to the file system. In addition, in-memory downloads may also be affected by memory limitations. When the downloaded files are large, it may cause insufficient memory problems, thereby affecting the download speed. Therefore, when choosing a download method, you need to weigh the pros and cons according to the specific situation and choose the most suitable method for downloading.
Question content
I am using aws gosdk to download from a certain bucket. The following are two implementations for download
- Download to file
func (a *awsclient) downloadtofile(ctx context.context, objectkey string) (string, error) {
params := &awss3.getobjectinput{
bucket: aws.string(a.bucket),
key: aws.string(objectkey),
}
downloadpath := "some/valid/path"
f, err := os.create(downloadpath)
defer f.close()
_, err = a.downloader.download(ctx, f, params)
return downloadpath, err
}
- Download to memory
func (a *AwsClient) DownloadToMemory(ctx context.Context, objectKey string) (string, error) {
params := &awsS3.GetObjectInput{
Bucket: aws.String(a.bucket),
Key: aws.String(objectKey),
}
buffer := manager.NewWriteAtBuffer([]byte{})
_, err = a.downloader.Download(ctx, buffer, params)
return buffer.Bytes(), err
}
For a 100 mb file, it takes 30 seconds to download to memory and only 8 seconds to download to the file system. My expectation is that memory downloads should be much faster. My system (apple m1, ventura, 8gb ram) has enough ram available so this is not an issue. Can anyone help me understand this behavior?
Solution
Downloading large S3 objects into dynamic buffers is very inefficient. The buffer was reallocated multiple times to handle 100M of data and multiple download threads. Memory reallocation requires a lot of CPU time.
Try to allocate 100M at the beginning instead of using null byte slices.
If the object size is unknown, you can use S3.HeadObject to get the object length in real time.
The above is the detailed content of Why is downloading in memory slower than downloading in the file system from aws s3?. For more information, please follow other related articles on the PHP Chinese website!

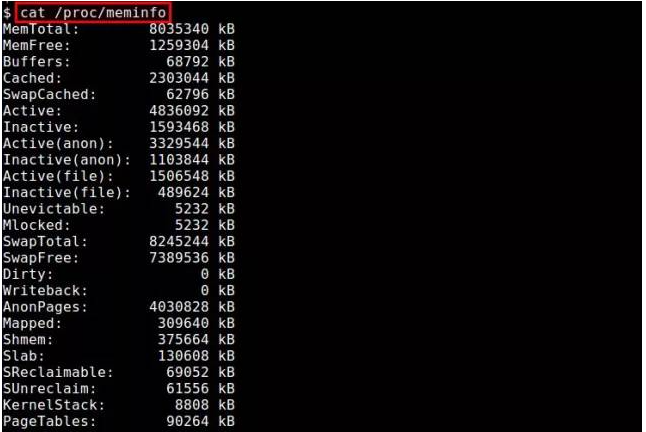 Linux下查看内存使用情况方法总结Feb 05, 2024 am 11:45 AM
Linux下查看内存使用情况方法总结Feb 05, 2024 am 11:45 AMQ:我有一个问题,我想要监视Linux系统的内存使用情况。在Linux下有哪些可用的视图或命令行工具可以使用呢?A:在Linux系统中,有多种方法可以监视内存使用情况。下面是一些通过视图工具或命令行来查看内存使用情况的方法。/proc/meminfo:最简单的方法是查看/proc/meminfo文件。这个虚拟文件会动态更新,并提供了关于内存使用情况的详细信息。它列出了各种内存指标,可以满足你对内存使用情况的大部分需求。另外,你还可以通过/proc//statm和/proc//status来查看进
 揭秘NVIDIA大模型推理框架:TensorRT-LLMFeb 01, 2024 pm 05:24 PM
揭秘NVIDIA大模型推理框架:TensorRT-LLMFeb 01, 2024 pm 05:24 PM一、TensorRT-LLM的产品定位TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。TensorRT-LL
 Linux 上的最佳白板应用程序Feb 05, 2024 pm 12:48 PM
Linux 上的最佳白板应用程序Feb 05, 2024 pm 12:48 PM“我们将介绍几款适用于Linux系统的白板应用程序,相信这些信息对您会非常有帮助。请继续阅读!”一般来说,数字白板是一种用于大型互动显示面板的工具,常见的设备类型包括平板电脑、大屏手机、触控笔记本和表面显示设备等。当教师使用白板时,您可以使用触控笔、手写笔、手指甚至鼠标在设备屏幕上进行绘画、书写或操作元素。这意味着您可以在白板上拖动、点击、删除和绘画,就像在纸上使用笔一样。然而,要实现这一切,需要有一款软件来支持这些功能,并实现触控和显示之间的精细协调。目前市面上有许多商业应用可以完成这项工作。
 ZR币升值空间大吗? ZR币在哪里购买交易?Feb 01, 2024 pm 08:09 PM
ZR币升值空间大吗? ZR币在哪里购买交易?Feb 01, 2024 pm 08:09 PMZRX(0x)是一个基于以太坊区块链的开放协议,用于实现分布式交易和去中心化交易所(DEX)功能。作为0x协议的原生代币,ZRX可用于支付交易费用、治理协议变更和获取平台优惠。1.ZRX币升值空间展望:从技术角度来看,ZRX作为0x协议的核心代币,在去中心化交易所的应用逐渐增多,市场对其认可度也在增加。以下是几个关键因素,有助于提升ZRX币的价值空间:市场需求潜力大、社区活跃度高、开发者生态繁荣等。这些因素共同促进了ZRX的广泛应用和使用,进而推动了其市场价格的上升。市场需求的增长潜力,意味着更
 BOSS直聘怎么创建多个简历Feb 05, 2024 pm 02:18 PM
BOSS直聘怎么创建多个简历Feb 05, 2024 pm 02:18 PMBOSS直聘怎么创建多个简历?BOSS直聘是很多小伙伴找工作的一大招聘平台,为用户们提供了非常多便利的求职服务。各位在使用BOSS直聘的时候,可以创建多个不同的简历,以便投送到不同的工作岗位上,获取到更高成功率的求职操作,各位如果对此感兴趣的话,就随小编一起来看看BOSS直聘双简历创建教程吧。BOSS直聘怎么创建多个简历1.登录Boss直聘:在您的电脑或手机上,登录您的Boss直聘账户。2.进入简历管理:在Boss直聘首页,点击“简历管理”,进入简历管理页面。3.创建新简历:在简历管理页面,点击
 手把手教你构建linux rootfsFeb 05, 2024 pm 03:51 PM
手把手教你构建linux rootfsFeb 05, 2024 pm 03:51 PMbusybox概述众所周知,在Linux环境下,一切皆文件,文件可以表示一切。而文件系统则是这些普通组件的集合。在嵌入式领域中,常常使用基于busybox构建的rootfs来构建文件系统。busybox诞生至今已有近20年的历史,如今已成为嵌入式行业中主流的rootfs构建工具。busybox的代码是完全开源的。你可以进入官方网站,点击”GetBusyBox”下面的”DownloadSource”进入源码下载界面。“官方网站链接:https://busybox.net/”2.busybox的配置
 Linux字节对齐的那些事Feb 05, 2024 am 11:06 AM
Linux字节对齐的那些事Feb 05, 2024 am 11:06 AM最近,我正在进行一个项目,遇到了一个问题。在ARM上运行的ThreadX与DSP通信时采用了消息队列的方式传递消息(最终实现使用了中断和共享内存的方法)。然而,在实际的操作过程中,发现ThreadX经常崩溃。经过排查,发现问题出在传递消息的结构体没有考虑字节对齐的问题上。我想顺便整理一下关于C语言中字节对齐的问题,并与大家分享。一、概念字节对齐与数据在内存中的位置有关。如果一个变量的内存地址恰好是它长度的整数倍,那么它就被称为自然对齐。例如,在32位CPU下,假设一个整型变量的地址为0x0000
 比 Vim 更现代直观的 Linux 文本编辑器Feb 05, 2024 pm 02:00 PM
比 Vim 更现代直观的 Linux 文本编辑器Feb 05, 2024 pm 02:00 PM如果你厌倦了Vi和Vim的奇怪界面和繁琐的键绑定,为什么不试试Micro编辑器呢?命令行文本编辑器证明了Linux终端的实用性,让您可以在不离开终端的情况下进行文件编辑。这些编辑器使用的资源更少,速度也非常快,非常适合进行一些快速编辑。一些流行的命令行文本编辑器包括Vi、Vim和Nano。它们在大多数Linux发行版中都预装了。然而,对于初学者来说,学习Vi或Vim的曲线和键绑定可能有些困难。这时,Micro文本编辑器就成为了一个更简单的选择。Micro与其他编辑相比的表现如何Micro宣称自己


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Notepad++7.3.1
Easy-to-use and free code editor

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

