
Home >Technology peripherals >AI >Defeating OpenAI, the weights, data, and codes are all open source, and the embedding model Nomic Embed that can be reproduced perfectly is here.
Defeating OpenAI, the weights, data, and codes are all open source, and the embedding model Nomic Embed that can be reproduced perfectly is here.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-02-04 09:54:151434browse
A week ago, OpenAI gave out benefits to users. They solved the problem of GPT-4 becoming lazy and introduced 5 new models, including the text-embedding-3-small embedding model, which is smaller and more efficient.
Embeddings are sequences of numbers used to represent concepts in natural language, code, and more. They help machine learning models and other algorithms better understand how content is related and make it easier to perform tasks such as clustering or retrieval. In the field of NLP, embedding plays a very important role.
However, OpenAI’s embedding model is not free for everyone to use. For example, text-embedding-3-small charges $0.00002 per 1k tokens.
Now, a better embedding model than text-embedding-3-small is here, and it’s free.
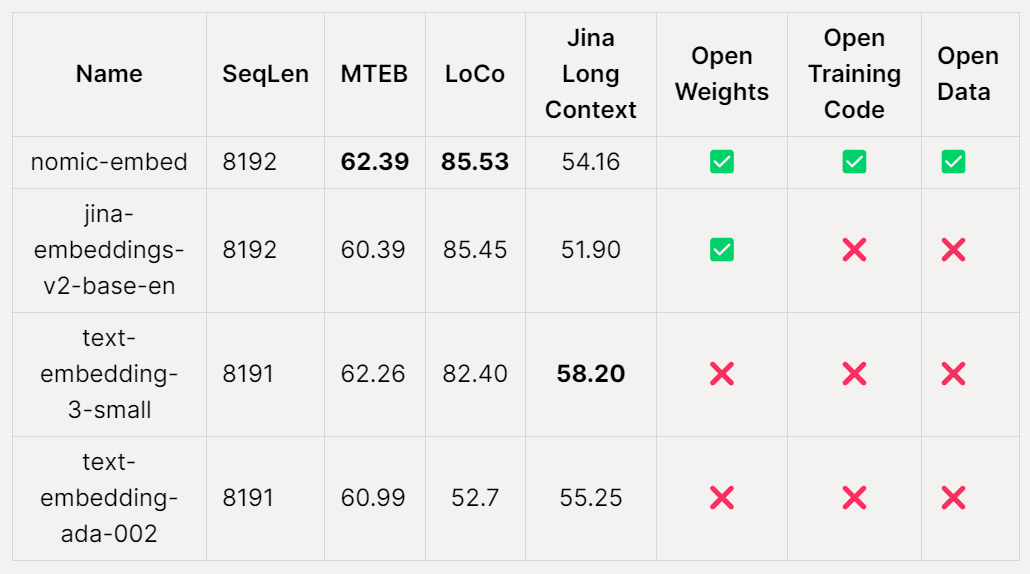
Nomic AI, an AI startup, recently released the first embedding model that is open source, open data, open weights, and open training code - Nomic Embed. The model is fully reproducible and auditable, with a context length of 8192. Nomic Embed beat OpenAI’s text-embeding-3-small and text-embedding-ada-002 models in both short- and long-context benchmarks. This achievement marks Nomic AI’s important progress in the field of embedded models.

Text embedding is a key component in modern NLP applications to provide retrieval-enhanced generation (RAG) functionality, providing support for LLM and semantic search. This technology enables more efficient processing by encoding the semantic information of a sentence or document into a low-dimensional vector and applying it to downstream applications such as clustering for data visualization, classification, and information retrieval. Currently, OpenAI’s text-embedding-ada-002 is one of the most popular long-context text embedding models, supporting up to 8192 context lengths. Unfortunately, however, Ada is closed source and its training data cannot be audited, which limits its credibility. Despite this, the model is still widely used and performs well in many NLP tasks. In the future, we hope to develop more transparent and auditable text embedding models to improve their credibility and reliability. This will help promote the development of the NLP field and provide more efficient and accurate text processing capabilities for various applications.
The best performing open source long context text embedding models, such as E5-Mistral and jina-embeddings-v2-base-en, may have some limitations. On the one hand, due to the large size of the model, it may not be suitable for general use. On the other hand, these models may not be able to surpass the performance levels of their OpenAI counterparts. Therefore, these factors need to be considered when choosing a model suitable for a specific task.
The release of Nomic-embed changes that. The model has only 137M parameters, which is very easy to deploy and can be trained in 5 days.

##Paper address: https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
Thesis title: Nomic Embed: Training a Reproducible Long Context Text Embedder
Project address: https://github.com/nomic-ai/ contrastors
How to build nomic-embed
One of the main disadvantages of existing text encoders is Limited by sequence length, limited to 512 tokens. To train a model for longer sequences, the first thing to do is to adjust BERT so that it can accommodate long sequence lengths. The target sequence length for this study was 8192.
Training BERT with a context length of 2048
This study follows a multi-stage contrastive learning pipeline to train nomic-embed . First, the study performed BERT initialization. Since bert-base can only handle a context length of up to 512 tokens, the study decided to train its own BERT with a context length of 2048 tokens - nomic-bert-2048.
Inspired by MosaicBERT, the research team made some modifications to BERT’s training process, including:
- Use rotated position embedding to allow context length extrapolation;
- Use SwiGLU activation as it has been shown to improve model performance;
- Set dropout to 0.
And the following training optimizations were performed:
- Use Deepspeed and FlashAttention for training;
- Train with BF16 accuracy;
- Increase the vocabulary (vocab) size to a multiple of 64;
- Train The batch size is 4096;
- During the masked language modeling process, the masking rate is 30% instead of 15%;
- Do not use the next sentence to predict the target.
During training, the study trained all stages with a maximum sequence length of 2048 and used dynamic NTK interpolation to extend to 8192 sequence length during inference.
Experiment
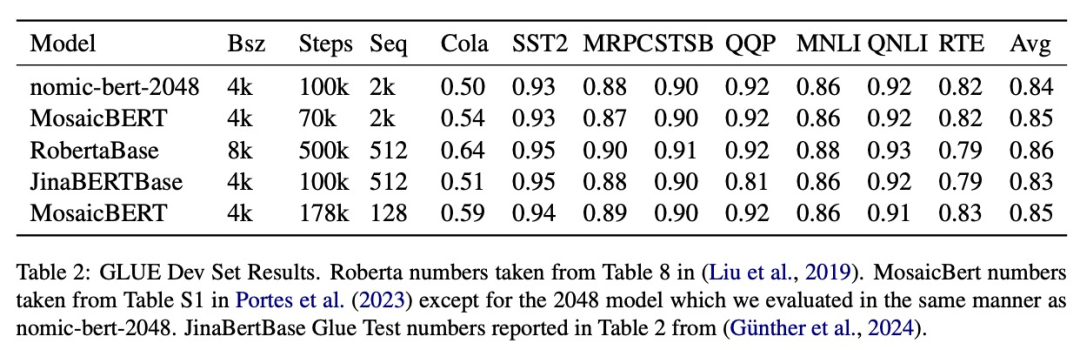
The study evaluated the quality of nomic-bert-2048 on the standard GLUE benchmark and found that its performance was comparable to other BERT models Comparable, but with the advantage of significantly longer context length.
Contrast training of nomic-embed
This study uses nomic- bert-2048 initializes nomic-embed training. The comparison dataset consists of approximately 235 million text pairs, and its quality was extensively verified using Nomic Atlas during collection.
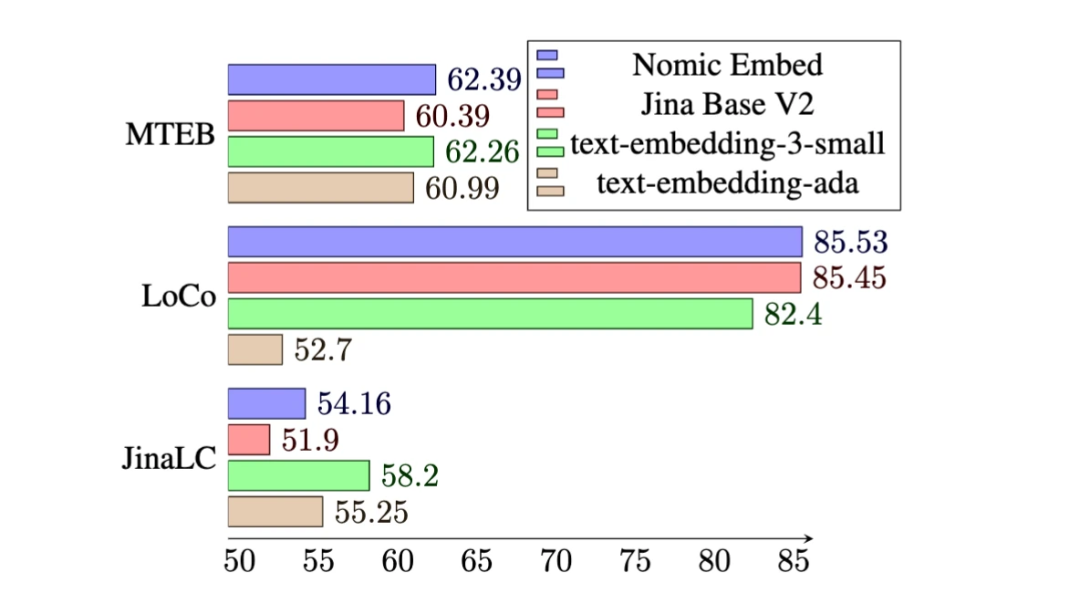
On the MTEB benchmark, nomic-embed outperforms text-embedding-ada-002 and jina-embeddings-v2-base-en.
# However, MTEB cannot evaluate long context tasks. Therefore, this study evaluates nomic-embed on the recently released LoCo benchmark as well as the Jina Long Context benchmark.
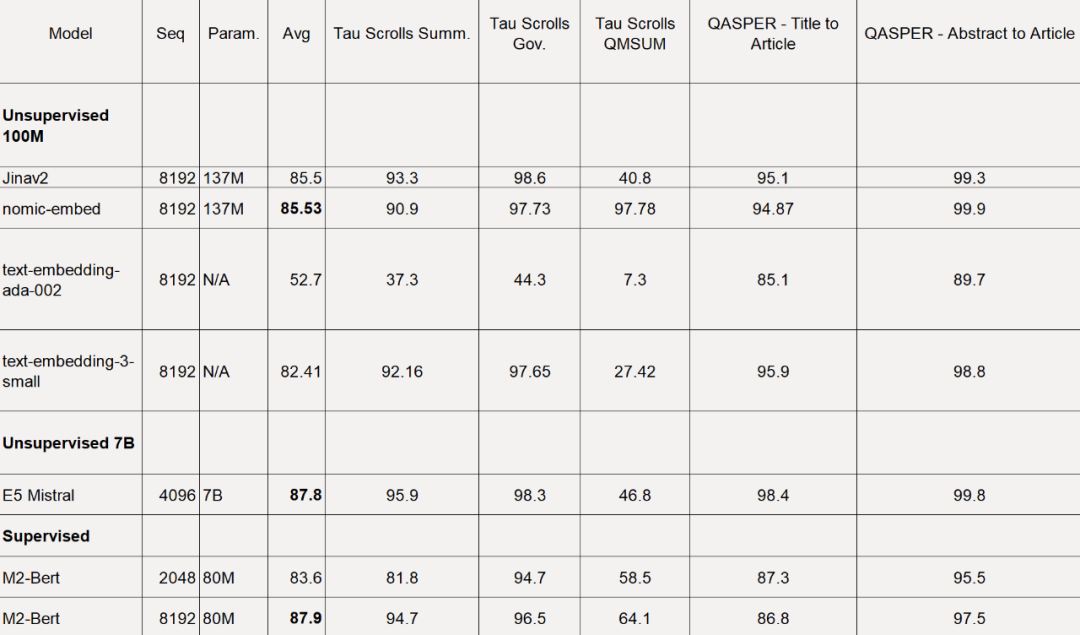
For the LoCo benchmark, the study evaluates separately by parameter category and whether the evaluation is performed in a supervised or unsupervised setting.
As shown in the table below, Nomic Embed is the best performing 100M parameter unsupervised model. Notably, Nomic Embed is comparable to the best performing models in the 7B parameter category as well as models trained specifically on the LoCo benchmark in a supervised environment:
On the Jina Long Context benchmark, Nomic Embed also performs better overall than jina-embeddings-v2-base-en, but Nomic Embed does not perform better than OpenAI ada-002 or text-embedding in this benchmark. -3-small:
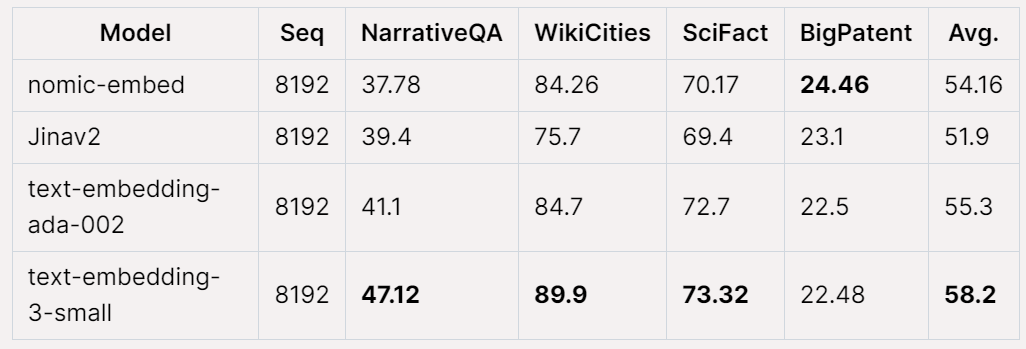
Overall, Nomic Embed outperforms OpenAI Ada-002 and text-embedding- in 2/3 benchmarks 3-small.
The study indicates that the best option for using Nomic Embed is the Nomic Embedding API. The way to obtain the API is as follows:

Finally, data access: To access the complete data, the study provides users with Cloudflare R2 (an AWS S3-like object storage service) access key. To gain access, users need to first create a Nomic Atlas account and follow the instructions in the contrastors repository.
contrastors address: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
The above is the detailed content of Defeating OpenAI, the weights, data, and codes are all open source, and the embedding model Nomic Embed that can be reproduced perfectly is here.. For more information, please follow other related articles on the PHP Chinese website!