

 Technology peripheralsAIData is king! How to build an efficient autonomous driving algorithm step by step through data?
Technology peripheralsAIData is king! How to build an efficient autonomous driving algorithm step by step through data?Data is king! How to build an efficient autonomous driving algorithm step by step through data?

Written before&The author’s personal understanding
The next generation of autonomous driving technology is expected to rely on specialized integration and integration between intelligent perception, prediction, planning and low-level control. Interaction. There has always been a huge bottleneck in the upper limit of autonomous driving algorithm performance. Academics and industry agree that the key to overcoming the bottleneck lies in data-centric autonomous driving technology. AD simulation, closed-loop model training and AD big data engine have recently gained some valuable experience. However, there is a lack of systematic knowledge and deep understanding of how to build efficient data-centric AD technology to realize the self-evolution of AD algorithms and better AD big data accumulation. To fill this research gap, here we will pay close attention to the latest data-driven autonomous driving technology, focusing on a comprehensive classification of autonomous driving datasets, mainly including milestones, key features, data collection settings, etc. In addition, we conducted a systematic review of the existing benchmark closed-loop AD big data pipeline from the industry frontier, including the process, key technologies and empirical research of the closed-loop framework. Finally, future development directions, potential applications, limitations, and concerns are discussed to elicit joint efforts from academia and industry to promote further development of autonomous driving.
In summary, the main contributions are as follows:
- Introduced the first comprehensive taxonomy of autonomous driving datasets classified by milestone generations, modular tasks, sensor suites and key functions ;
- Based on deep learning and generative artificial intelligence models, a systematic review of the most advanced closed-loop data-driven autonomous driving pipeline and related key technologies;
- gives a closed-loop big data driver Empirical study of how pipeline works in autonomous driving industrial applications;
- discusses the pros and cons of current pipeline and solutions, as well as research into the future of data-centric autonomous driving direction.
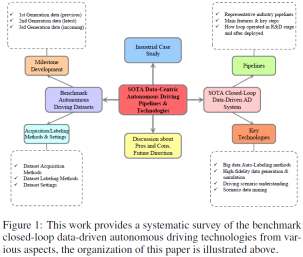
SOTA Autonomous Driving Dataset: Classification and Development
The evolution of autonomous driving datasets reflects the field’s Technological advances and growing ambitions. The early AVT research at the Institute of Advancement and the PATH program at the University of California, Berkeley, at the end of the 20th century laid the foundation for basic sensor data, but were limited by the technological level of the era. The past two decades have seen significant leaps forward, driven by advances in sensor technology, computing power and sophisticated machine learning algorithms. In 2014, the Society of Automotive Engineers (SAE) announced to the public a systematic six-level (L0-L5) autonomous driving system, which has been widely recognized by the progress of autonomous driving research and development. Driven by deep learning, computer vision-based methods have dominated intelligent perception. Deep reinforcement learning and its variants provide crucial improvements in intelligent planning and decision-making. Recently, large language models (LLM) and visual language models (VLM) have demonstrated their powerful scene understanding, driving behavior reasoning and prediction, and intelligent decision-making capabilities, opening up new possibilities for the future development of autonomous driving.
Milestone development of autonomous driving data sets
Figure 2 shows the milestone development of open source autonomous driving data sets in chronological order. Significant progress has led to the classification of mainstream datasets into three generations, characterized by significant leaps in dataset complexity, volume, scene diversity, and annotation granularity, pushing the field to a new frontier of technological maturity. Specifically, the horizontal axis represents the development timeline. The header of each row includes the dataset name, sensor modality, suitable task, data collection location, and associated challenges. To further compare datasets across generations, we use differently colored bar charts to visualize the perceived and predicted/planned dataset sizes. The early stages, the first generation starting in 2012, led by KITTI and Cityscapes, provided high-resolution images for perception tasks and were the basis for benchmark progress in vision algorithms. Advancing to the second generation, NuScenes, Waymo, Argoverse 1 and other data sets have introduced a multi-sensor method, integrating data from vehicle cameras, high-precision maps (HD Map), lidar, radar, GPS, IMU, trajectories, and surrounding objects. Integrated together, this is critical for comprehensive driving environment modeling and decision-making processes. More recently, NuPlan, Argoverse 2, and Lyft L5 have significantly raised the bar for impact, delivering unprecedented data scale and fostering an ecosystem conducive to cutting-edge research. Characterized by their massive size and multi-modal sensor integration, these datasets have played an important role in developing algorithms for sensing, prediction and planning tasks, paving the way for advanced End2End or hybrid autonomous driving models. In 2024, we will usher in the third generation of autonomous driving data sets. Supported by VLM, LLM and other third-generation artificial intelligence technologies, the third-generation data set highlights the industry's commitment to address the increasingly complex challenges of autonomous driving, such as data long-tail distribution problems, out-of-distribution detection, corner case analysis, etc. .

Dataset acquisition, setup and key features
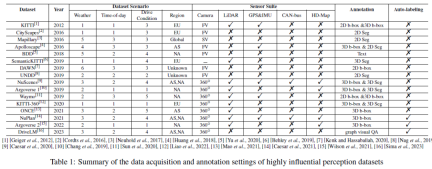
Table 1 summarizes the data acquisition and annotation setup for the highly impactful perception dataset, including driving scenarios, sensor suites and annotations , we report the total number of weather/time/driving condition categories under the dataset scenarios, where weather usually includes sunny/cloudy/foggy/rainy/snow/other (extreme conditions); time of day usually includes morning, afternoon and At night; driving conditions typically include city streets, main roads, side streets, rural areas, highways, tunnels, parking lots, etc. The more diverse the scenarios, the more powerful the data set. We also report the region where the dataset was collected, denoted as (Asia), EU (Europe), NA (North America), SA (South America), AU (Australia), AF (Africa). It is worth noting that Mapillary is collected through AS/EU/NA/SA/AF/AF, and DAWN is collected from Google and Bing image search engines. For the sensor suite, we looked at cameras, lidar, GPS and IMU, etc. FV and SV in Table 1 are the abbreviations of front view camera and street view camera respectively. A 360° panoramic camera setup usually consists of multiple front view cameras, rare view cameras, and side view cameras. We can observe that with the development of AD technology, the type and number of sensors included in the data set are increasing, and the data patterns are becoming more and more diverse. Regarding data set annotation, early data sets usually used manual annotation methods, while recent NuPlan, Argoverse 2, and DriveLM have adopted automatic annotation technology for AD big data. We believe that the transition from traditional manual annotation to automatic annotation is a major trend in data-centric autonomous driving in the future.
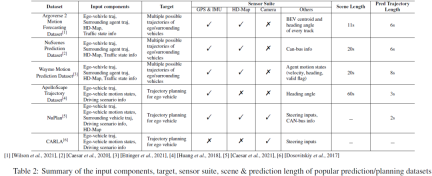
For prediction and planning tasks, we summarize the input/output components, sensor suites, scene lengths, and prediction lengths of mainstream datasets in Table 2. For motion prediction/prediction tasks, input components usually include the historical trajectory of the own vehicle, the historical trajectory of surrounding agents, high-precision maps, and traffic status information (i.e., traffic signal status, road ID, stop signs, etc.). The target output is several most likely trajectories (such as the top 5 or top 10 trajectories) of the self-vehicle and/or surrounding subjects in a short period of time. Motion prediction tasks usually adopt a sliding time window setting to divide the entire scene into several shorter time windows. For example, NuScenes uses the past 2 seconds of GT data and high-precision maps to predict the trajectory of the next 6 seconds, while Argoverse 2 uses historical 5 seconds of ground truth and high-precision maps to predict the trajectory of the next 6 seconds. NuPlan, CARLA and ApoloScape are the most popular planning task datasets. Input components include self/surrounding vehicle historical trajectories, self-vehicle motion states, and driving scene representations. While NuPlan and ApoloScape were obtained in the real world, CARLA is a simulated dataset. CARLA contains road images taken during simulated driving in different towns. Each road image is associated with a steering angle, which represents the adjustment required to keep the vehicle moving properly. The prediction length of the plan can vary according to the requirements of different algorithms.
Closed-loop data-driven autonomous driving system
We are now moving from the previous era of autonomous driving defined by software and algorithms to a new era Inspiring big data-driven and intelligent model collaborative autonomous driving era. The closed-loop data-driven system aims to bridge the gap between AD algorithm training and its real-world application/deployment. Unlike traditional open-loop approaches, where models are passively trained on datasets collected from human customer driving or road testing, closed-loop systems dynamically interact with the real environment. This approach addresses the challenge of distribution variation—behaviors learned from static datasets may not translate to the dynamic nature of real-world driving scenarios. Closed-loop systems allow AVs to learn from interactions and adapt to new situations, improving through iterative cycles of action and feedback.
However, building a real-world data-centric closed-loop AD system remains challenging due to several key issues: The first issue is related to AD data collection. In real-world data collection, most data samples are common/normal driving scenarios, while data on curves and abnormal driving scenarios are almost impossible to collect. Secondly, further efforts are needed to explore accurate and efficient automatic annotation methods for AD data. Third, in order to alleviate the problem of poor performance of AD models in certain scenes in urban environments, scene data mining and scene understanding should be emphasized.
SOTA closed-loop autonomous driving pipeline
The autonomous driving industry is actively building an integrated big data platform to cope with the challenges brought by the accumulation of large amounts of AD data. This can be appropriately called the new infrastructure for the era of data-driven autonomous driving. In our survey of data-driven closed-loop systems developed by top AD companies/research institutions, we found several commonalities:
- Thesepipeline usually follow a workflow cycle, including: (I) data collection, (II) data storage, (III) data selection and preprocessing, (IV) data annotation, (V) AD model training, (VI) simulation/test validation, and (VII) real-world deployment.
- For the design of closed-loop within the system, existing solutions either choose to set up "data closed-loop" and "model closed-loop" separately, or set up cycles in different stages: "R&D stage closed-loop", "deployment stage closed-loop" ".
- In addition, the industry also highlighted the long-term distribution problem of real-world AD datasets and the challenges in dealing with corner cases. Tesla and Nvidia are industry pioneers in this field, and their data system architecture provides an important reference for the development of this field.
NVIDIA MagLev AV platform Figure 3 (left)) follows "Collect → Select → Label → Train the Dragon" as a program, which is a replicable workflow that can achieve active learning of SDC, and Smart annotation in loops. MagLev mainly includes two closed loopspipeline. The first cycle is centered on autonomous driving data, starting from data ingestion and intelligent selection, through annotation and annotation, and then model search and training. The trained model is then evaluated, debugged, and ultimately deployed into the real world. The second closed loop is the platform's infrastructure support system, including the data center backbone and hardware infrastructure. This loop includes secure data processing, scalable DNN and system KPIs, dashboards for tracking and debugging. It supports the full cycle of AV development, ensuring continuous improvement and integration of real-world data and simulation feedback during the development process.
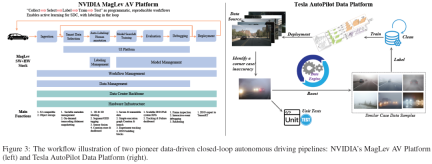
The Tesla Autonomous Driving Data Platform (Figure 3 (right)) is another representative AD platform, which emphasizes the use of big data-driven closed loop pipeline to significantly improve the performance of the autonomous driving model. pipelineStart with source data collection, typically from Tesla’s fleet learning, event-triggered vehicle-side data collection, and shadow mode. The data collected will be stored, managed and reviewed by data platform algorithms or human experts. Whenever a corner case/inaccuracy is discovered, the data engine will retrieve and match data samples that are highly similar to the corner case/inaccuracy from the existing database. At the same time, unit tests will be developed to replicate the scenario and rigorously test the system's response. The retrieved data samples are then annotated by automatic annotation algorithms or human experts. The well-annotated data will then be fed back to the AD database, which will be updated to generate new versions of training datasets for AD sensing/prediction/planning/control models. After model training, verification, simulation and real-world testing, new AD models with higher performance will be released and deployed.
High-fidelity AD data generation and simulation based on Generative AI
Most AD data samples collected from the real world are common/normal driving scenarios, among which we There are already a large number of similar samples in the database. However, to collect some type of AD data samples from real-world acquisitions, we would need to drive for an exponentially long time, which is not feasible in industrial applications. Therefore, high-fidelity autonomous driving data generation and simulation methods have attracted great attention from the academic community. CARLA is an open source simulator for autonomous driving research that can generate autonomous driving data under various user-specified settings. The strength of CARLA is its flexibility, allowing users to create different road conditions, traffic scenarios and weather dynamics, which facilitates comprehensive model training and testing. However, as a simulator, its main disadvantage is the domain gap. The AD data generated by CARLA cannot fully simulate the physical and visual effects of the real world; the dynamic and complex characteristics of the real driving environment are also not represented.
Recently, world models have been used for high-fidelity AD data generation with their more advanced intrinsic concepts and more promising performance. A world model can be defined as an artificial intelligence system that builds an internal representation of the environment it perceives and uses the learned representation to simulate data or events in the environment. The goal of a general world model is to represent and simulate situations and interactions just as mature humans encounter them in the real world. In the field of autonomous driving, GAIA-1 and DriveDreamer are masterpieces of data generation based on world models. GAIA-1 is a generative artificial intelligence model that achieves image/video-to-image/video generation by taking raw images/videos as input along with text and action prompts. The input modalities of GAIA-1 are encoded into a unified sequence of tokens. These annotations are processed by an autoregressive transformer within the world model to predict subsequent image annotations. The video decoder then reconstructs these annotations into coherent video outputs with enhanced temporal resolution, enabling dynamic and context-rich visual content generation. DriveDreamer innovatively adopts a diffusion model in its architecture, focusing on capturing the complexity of real-world driving environments. Its two-stage training pipeline first enables the model to learn structured traffic constraints and then predict future states, ensuring strong environmental understanding tailored for autonomous driving applications.
Automatic labeling method for autonomous driving data sets
High-quality data labeling is essential for success and reliability. So far, data annotation pipeline can be divided into three types, from traditional manual annotation to semi-automatic annotation to the most advanced fully automatic annotation method. As shown in Figure 4, AD data annotation is usually regarded as Be task/model specific. The workflow starts with careful preparation of the requirements for the annotation task and the original dataset. Then, the next step is to generate initial annotation results using human experts, automatic annotation algorithms, or End2End large models. The annotation quality is then checked by human experts or automated quality checking algorithms based on predefined requirements. If the annotation results of this round fail the quality check, they are sent back to the annotation cycle again and this annotation job is repeated until they meet the predefined requirements. Finally, we can obtain a ready-made labeled AD dataset.

The automatic annotation method is the key to the closed-loop autonomous driving big data platform to alleviate the labor-intensive manual annotation, improve the efficiency of AD data closed-loop circulation, and reduce related costs. Classic automatic labeling tasks include scene classification and understanding. Recently, with the popularity of BEV methods, the industry standards for AD data annotation are also constantly improving, and automatic annotation tasks have become more complex. In today's industrial cutting-edge scenarios, automatic labeling of 3D dynamic targets and automatic labeling of 3D static scenes are two commonly used advanced automatic labeling tasks.
Scene classification and understanding are the basis of the autonomous driving big data platform. The system classifies video frames into predefined scenes, such as driving places (streets, highways, urban overpasses, main roads, etc.) and scene weather ( Sunny day, rainy day, snowy day, foggy day, thunderstorm day, etc.). CNN-based methods are commonly used for scene classification, including pre-trained fine-tuned CNN models, multi-view and multi-layer CNN models, and various CNN-based models for improved scene representation. Scene understanding goes beyond mere classification. It involves interpreting dynamic elements in the scene, such as surrounding vehicle agents, pedestrians, and traffic lights. In addition to image-based scene understanding, lidar-based data sources, such as SemanticKITTI, are also widely adopted due to the fine-grained geometric information they provide.
The emergence of automatic annotation of three-dimensional dynamic objects and automatic annotation of three-dimensional static scenes is to meet the requirements of widely adopted pure electric vehicle perception technology. Waymo proposed a 3D automatic labeling pipeline based on lidar point cloud sequence data, which uses a 3D detector to locate targets frame by frame. The bounding boxes of the identified objects across frames are then linked via a multi-object tracker. Object trajectory data (corresponding point cloud 3D bounding box at each frame) is extracted for each object, and object-centered automatic labeling is performed using a divide-and-conquer architecture to generate the final refined 3D bounding box as a label. The Auto4D pipeline proposed by Uber explores AD perception markers at the spatiotemporal scale for the first time. In the field of autonomous driving, 3D target bounding box marking in the spatial scale and 1D corresponding timestamp marking in the time scale are called 4D marking. Auto4D pipeline starts with a continuous lidar point cloud to establish initial object trajectories. The trajectory is refined by the target size branch, which encodes and decodes the target size using target observations. At the same time, the motion path branch encodes path observations and motion, allowing the path decoder to refine the trajectory with a constant target size.
3D static scene automatic labeling can be considered as HDMap generation, where lanes, road boundaries, crosswalks, traffic lights and other relevant elements in the driving scene should be labeled. Under this topic, there are several attractive research works: vision-based methods, such as MVMap, NeMO; lidar-based methods, such as VMA; pre-trained 3D scene reconstruction methods, such as OccBEV, OccNet/ADPT, ALO . VMA is a recently proposed work for automatic labeling of 3D static scenes. The VMA framework utilizes crowdsourced, multi-trip aggregated lidar point clouds to reconstruct static scenes and segment them into units for processing. The MapTR-based unit annotator encodes the raw input into feature maps through querying and decoding, generating semantically typed point sequences. The output of VMA is a vectorized map, which will be refined through closed-loop annotation and manual verification to provide a satisfactory high-precision map for autonomous driving.
Empirical Study
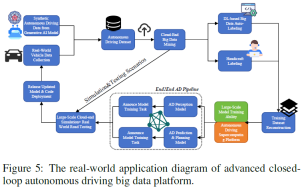
We provide an empirical study to better illustrate the advanced closed-loop AD data platform mentioned in this article. The entire process diagram is shown in Figure 5. In this case, the researchers’ goal is to develop an AD big data closed-looppipeline based on Generative AI and various deep learning-based algorithms, so as to achieve a smooth transition between the autonomous driving algorithm development phase and the OTA upgrade phase (in After real-world deployment) achieve data closed loop. Specifically, the generated artificial intelligence model is used to (1) generate high-fidelity AD data for specific scenarios based on text prompts provided by engineers. (2) Automatic labeling of AD big data to effectively prepare ground truth labels.
The figure shows two closed loops. One of the larger stages is the autonomous driving algorithm development phase, which starts with the data collection of synthetic autonomous driving data to generate artificial intelligence models and data samples obtained from real-world driving. These two data sources are integrated into a self-driving data set and mined in the cloud to gain valuable insights. Afterwards, the dataset enters a dual labeling path: automatic labeling based on deep learning or manual manual labeling, ensuring the speed and accuracy of annotation. The labeled data is then used to train the model on a high-capacity autonomous driving supercomputing platform. These models are tested on simulations and real-world roads to evaluate their efficacy, leading to the release and subsequent deployment of autonomous driving models. The smaller one is for the OTA upgrade phase after real-world deployment, which involves large-scale cloud simulations and real-world testing to collect inaccuracies/corner cases of the AD algorithm. The identified inaccuracies/corner cases are used to inform the next iteration of model testing and updates. For example, suppose we discover that our AD algorithm performs poorly in a tunnel driving scenario. Identified tunnel driving curves will be announced to the ring immediately and updated in the next iteration. The generative artificial intelligence model uses relevant descriptions of tunnel driving scenes as text prompts to generate large-scale tunnel driving data samples. The generated data and raw datasets will be fed into simulations, tests and model updates. The iterative nature of these processes is critical to optimizing models to adapt to challenging environments and new data, maintaining high accuracy and reliability of autonomous driving capabilities.
Discuss
New autonomous driving data sets of the third generation and beyond. Although basic models such as LLM/VLM have achieved success in language understanding and computer vision, it is still challenging to directly apply them to autonomous driving. There are two reasons for this: On the one hand, these LLM/VLM must have the ability to fully integrate and understand multi-source AD big data (such as FOV images/videos, lidar cloud points, high-definition maps, GPS/IMU data, etc.), which is better than It's even harder to understand the images we see in our daily lives. On the other hand, the existing data scale and quality in the field of autonomous driving are not comparable to other fields (such as finance and medical care), making it difficult to support the training and optimization of larger-capacity LLM/VLM. Big data for autonomous driving is currently limited in scale and quality due to regulations, privacy concerns, and cost. We believe that with the joint efforts of all parties, the next generation of AD big data will be significantly improved in scale and quality.
Hardware support for autonomous driving algorithms. Current hardware platforms have made significant progress, especially with the emergence of specialized processors such as GPUs and TPUs, which provide the massive parallel computing power critical to deep learning tasks. High-performance computing resources in on-board and cloud infrastructure are critical to processing the massive data streams generated by vehicle sensors in real time. Despite these advances, there are still limitations in scalability, energy efficiency, and processing speed when dealing with the increasing complexity of autonomous driving algorithms. VLM/LLM guided user-vehicle interaction is a very promising application case. Based on this application, user-specific behavioral big data can be collected. However, VLM/LLM in-vehicle devices will require high standards of hardware computing resources, and interactive applications are expected to have low latency. Therefore, there may be some lightweight large-scale autonomous driving models in the future, or the compression technology of LLM/VLM will be further studied.
Personalized autonomous driving recommendations based on user behavior data. Smart cars have developed from simple means of transportation to the latest application expansion in smart terminal scenarios. Therefore, the expectation for vehicles equipped with advanced autonomous driving features is that they can learn the driver's behavioral preferences, such as driving style and route preferences, from historical driving data records. This will enable smart cars to better align with users’ favorite vehicles in the future as they help drivers with vehicle control, driving decisions and route planning. We call the above concept a personalized autonomous driving recommendation algorithm. Recommendation systems have been widely used in e-commerce, online shopping, food delivery, social media, and live streaming platforms. However, in the field of autonomous driving, personalized recommendations are still in their infancy. We believe that in the near future, a more appropriate data system and data collection mechanism will be designed to collect big data on users’ driving behavior preferences with the user’s permission and compliance with relevant regulations, thereby achieving customized autonomous driving recommendations for users. system.
Data security and trustworthy autonomous driving. The massive amount of autonomous driving big data poses major challenges to data security and user privacy protection. As connected autonomous vehicles (CAVs) and Internet of Vehicles (IoV) technologies develop, vehicles become increasingly connected, and the collection of detailed user data from driving habits to frequent routes has raised concerns about the potential misuse of personal information. We recommend the need for transparency regarding the types of data collected, retention policies, and third-party sharing. It emphasizes the importance of user consent and control, including honoring “do not track” requests and providing the option to delete personal data. For the autonomous driving industry, protecting this data while promoting innovation requires strict adherence to these guidelines, ensuring user trust and compliance with evolving privacy legislation.
In addition to data security and privacy, another issue is how to achieve trustworthy autonomous driving. With the tremendous development of AD technology, intelligent algorithms and generative artificial intelligence models (such as LLM, VLM) will "act as driving factors" when performing increasingly complex driving decisions and tasks. In this field, a natural question arises: Can humans trust autonomous driving models? In our view, the key to trustworthiness lies in the interpretability of self-driving models. They should be able to explain to a human driver the reasons for a decision, not just perform the driving action. LLM/VLM is expected to enhance trustworthy autonomous driving by providing advanced reasoning and understandable explanations in real time.
Conclusion
This survey provides the first systematic review of data-centric evolution in autonomous driving, including big data systems, data mining, and closed-loop technologies. In this survey, we first develop a taxonomy of datasets by milestone generation, review the development of AD datasets across the historical timeline, and introduce dataset acquisition, setup, and key features. Furthermore, we elaborate on closed-loop data-driven autonomous driving systems from both academic and industrial perspectives. Workflowpipeline, processes and key technologies in data-centric closed-loop systems are discussed in detail. Through empirical research, the utilization rate and advantages of the data-centered closed-loop AD platform in algorithm development and OTA upgrades are demonstrated. Finally, the advantages and disadvantages of existing data-driven autonomous driving technologies and future research directions are comprehensively discussed. The focus is on new data sets, hardware support, personalized AD recommendations, and explainable autonomous driving after the third generation. We also expressed concerns about the trustworthiness of Generative AI models, data security, and the future development of autonomous driving.

Original link: https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rA
The above is the detailed content of Data is king! How to build an efficient autonomous driving algorithm step by step through data?. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

