
Home >Technology peripherals >AI >In the era of big models, NTU Zhou Zhihua is immersed in studying software, and his latest paper is online
In the era of big models, NTU Zhou Zhihua is immersed in studying software, and his latest paper is online

- 王林forward
- 2024-01-31 11:06:08986browse
Machine learning has achieved great success in various fields, and a large number of high-quality machine learning models continue to emerge. However, it is not easy for ordinary users to find a model suitable for their tasks, let alone build a new model from scratch. In order to solve this problem, Professor Zhou Zhihua of Nanjing University proposed a paradigm called "learningware". Through the idea of models and regulations, a learningware market (now called the learningware base system) was constructed to enable users to unify Choose and deploy models to meet your needs. Now, the learningware paradigm has ushered in its first open source basic platform, named Beimingwu. This platform will provide users with a rich model library and deployment tools, making it easier and more efficient to use and customize machine learning models. Through Beimingwu, users can better utilize the power of machine learning to solve various practical problems.

In the classic machine learning paradigm, in order to train a high-performance model from scratch, a large amount of high-quality data, expert experience and computing resources are required. It is undoubtedly a time-consuming and costly task. In addition, there are also some problems in reusing existing models. For example, it is difficult to adapt a specific trained model to different environments, and catastrophic forgetting may occur during the gradual improvement of a trained model. Therefore, we need to find a more efficient and flexible way to deal with these challenges.
Data privacy and ownership issues not only hinder the sharing of experience among developers, but also limit the ability of large models to be applied in data-sensitive scenarios. Research often focuses on these issues, but in practice they often occur simultaneously and influence each other.
In the fields of natural language processing and computer vision, although the mainstream large model development paradigm has made remarkable achievements, some important issues have not yet been resolved. These issues include unlimited unplanned tasks and scenarios, constant changes in the environment, catastrophic forgetting, high resource requirements, privacy concerns, localized deployment requirements, and requirements for personalization and customization. Therefore, building a corresponding large model for each potential task is an impractical solution. These challenges require us to find new methods and strategies to deal with, such as adopting more flexible and customizable model architectures, and using techniques such as transfer learning and incremental learning to adapt to changes in different tasks and environments. Only by integrating multiple approaches and strategies can we better solve these complex problems.
In order to solve machine learning tasks, Professor Zhou Zhihua of Nanjing University proposed the concept of learnware in 2016. He created a new paradigm based on learningware and proposed the learningware dock system as the basic platform. The goal of this system is to uniformly accommodate machine learning models submitted by developers around the world, and to use model capabilities to solve new tasks based on the task needs of potential users. This innovation brings new possibilities and opportunities to the field of machine learning.
The core design of the learningware paradigm is this: for high-quality models from different tasks, learningware is a basic unit with a unified format. Learningware consists of the model itself and a specification that describes the characteristics of the model in some representation. Developers can freely submit models, and the learning dock system will assist in generating specifications and store the learning software in the learning dock. In this process, developers do not need to disclose their training data to the learning dock. In the future, users can submit requirements to the learningware base system and solve their own machine learning tasks by finding and reusing learningware without leaking their own data to the learningware system. This design makes model sharing and task solving more efficient, convenient, and privacy-safe.
In order to establish a preliminary scientific research platform for learningware paradigms, Professor Zhou Zhihua’s team recently built Beimingwu, which is the first open source learning platform for future learningware paradigm research. Part base system. The relevant paper has been published and is 37 pages long.
At the technical level, the Beimingwu system has laid the foundation for future academic software-related algorithm and system research through scalable system and engine architecture design and extensive engineering implementation and optimization. In addition, the system also integrates the full-process baseline algorithm and builds a basic algorithm evaluation scenario. These features not only enable the system to provide support for learningware, but also provide the possibility to host a large number of learningware and establish a learningware ecosystem.

Paper title: Beimingwu: A Learnware Dock System
Paper address: https://arxiv .org/pdf/2401.14427.pdf
Beimingwu homepage: https://bmwu.cloud/
Beimingwu open source warehouse :https://www.gitlink.org.cn/beimingwu/beimingwu
Core engine open source warehouse: https://www.gitlink.org.cn/beimingwu/learnware
In this article, the researcher’s contributions can be summarized as follows:
Based on the learningware paradigm, it simplifies model development for users to solve new tasks: data efficiency is achieved, no expert knowledge is required, and original data is not leaked;
Proposed a complete, unified and scalable system engine architecture design;
developed an open source learning software base system with a unified user interface;
Full-process baseline algorithm implementation and evaluation for different scenarios.
Overview of the learnware paradigm
The learnware paradigm was proposed by Professor Zhou Zhihua’s team in 2016 and published in the 2024 paper "Learnware: small Summarize and further design in "models do big". The simplified process of this paradigm is shown in Figure 1 below: For high-quality machine learning models of any type and structure, their developers or owners can voluntarily submit the trained models to the learning base system (formerly known as the learning base system). parts market).
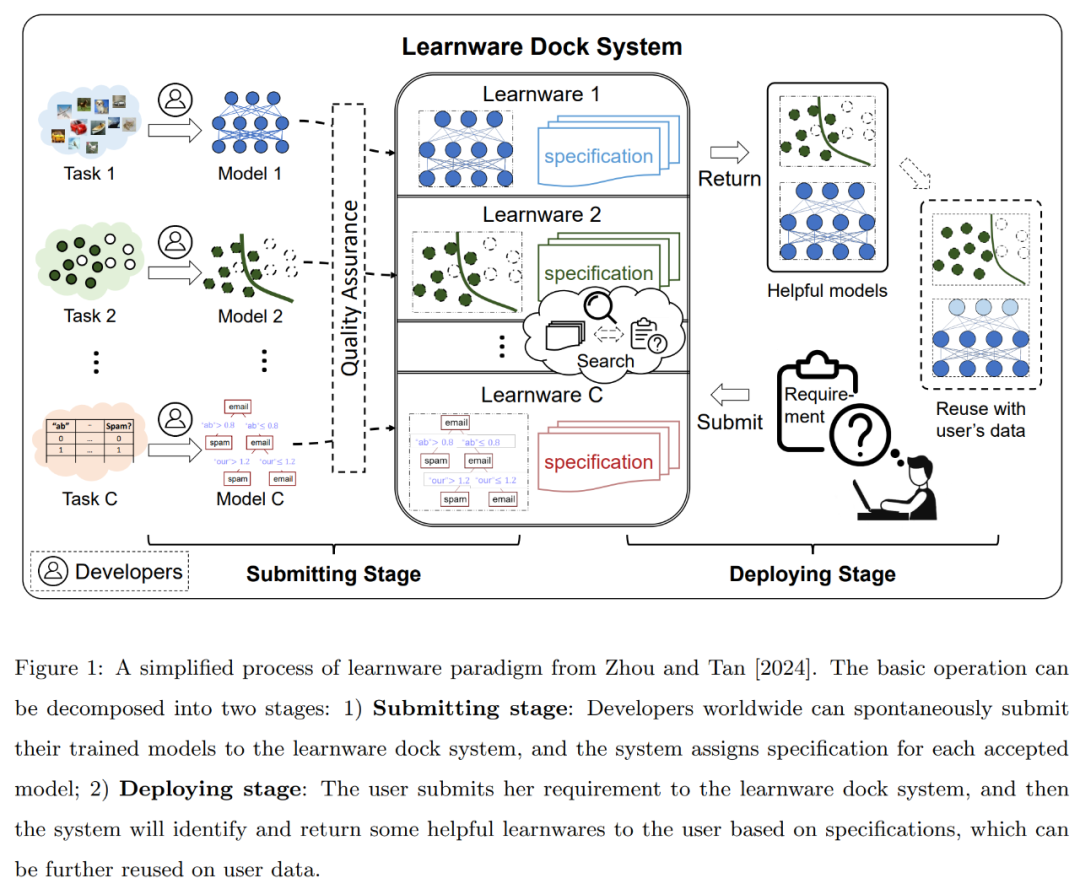
As introduced above, the learningware paradigm proposes to establish a learningware base system to uniformly accommodate, organize and utilize existing models with good performance, so as to uniformly utilize Efforts from all communities to solve new user tasks may also address some of the major issues of concern, including lack of training data and training skills, catastrophic forgetting, difficulty in achieving continuous learning, data privacy or proprietaryization, and openness. Unplanned new tasks in the world, carbon emissions caused by repeated wasted training, etc.
Recently, the learningware paradigm and its core ideas have received more and more attention. But the key question and the main challenge is this: considering that a learning base system can accommodate thousands or even millions of models, how to identify and select the learning piece or set of learning pieces that are most helpful for a new user's task? Obviously, submitting user data directly into the system for experimentation is expensive and exposes the user's original data.
The core design of the learning software paradigm lies in the protocol. Recent research is mainly based on the reduced kernel mean embedding (RKME) protocol.
Although existing theoretical and empirical analysis and research have proven the effectiveness of protocol-based learningware identification, the implementation of the learningware base system is still missing and faces huge challenges, requiring a new protocol-based architecture. Designed to cope with diverse real-world tasks and models, and to uniformly search and reuse a large number of learning materials according to user task requirements.
The researchers built the first learningware base system, Beimingwu, which provides support for the entire process including submission, usability testing, organization, management, identification, deployment and learningware reuse. .
Use Beimingwu to solve learning tasks
The first system implementation based on the learningware paradigm, Beimingwu significantly simplifies the process of building machine learning models for new tasks. Now, we can build the model following the process of the learningware paradigm. And benefiting from the unified learning software structure, unified architecture design and unified user interface, all submitted models in Beimingwu achieve unified identification and reuse.
The exciting thing is that given a new user task, if Beimingwu has learning software that can solve this task, users can easily obtain and deploy it with just a few lines of code. High-quality models that do not require large amounts of data and expert knowledge, and do not leak their own raw data.
Figure 2 below is a code example of using Beimingwu to solve learning tasks.

Figure 3 below shows the entire workflow of using Beimingwu, including statistical protocol generation, learning software identification, loading and reuse. Based on engineering implementation and unified interface design, each step can be realized through a line of key code.

The researchers said that when solving learning tasks, the model development process using the learning software paradigm based on Beimingwu has the following significant advantages:
Does not require a large amount of data and computing resources;
does not require a large amount of machine learning expertise;
is Diversified models provide unified and simple local deployment;
Privacy protection: Do not leak the user’s original data.
Currently, Beimingwu only has 1,100 learning tools built on open source data sets in the early stage. It does not cover many scenarios, and its ability to handle a large number of specific and unseen scenarios is still limited. . Based on the scalable architecture design, Beimingwu can be used as a research platform for learningware paradigms, providing convenient algorithm implementation and experimental design for learningware-related research.
At the same time, relying on basic implementation and scalable architecture support, continuously submitted learning materials and continuously improved algorithms will continue to enhance the system's ability to solve tasks and enhance the system's reuse of existing well-trained models. The ability to solve new tasks beyond the developer's original goals. In the future, the continued evolution of learningware base systems will enable them to respond to an increasing number of user tasks without catastrophic forgetting and naturally enable lifelong learning.
Beimingwu Design
Section 4 of the paper introduces the design of the Beimingwu system. As shown in Figure 4, the entire system includes four levels: learning software storage, system engine, system background and user interface. This section first introduces the overview of each layer, then introduces the core engine of the system based on protocol design, and finally introduces the algorithms implemented in the system.
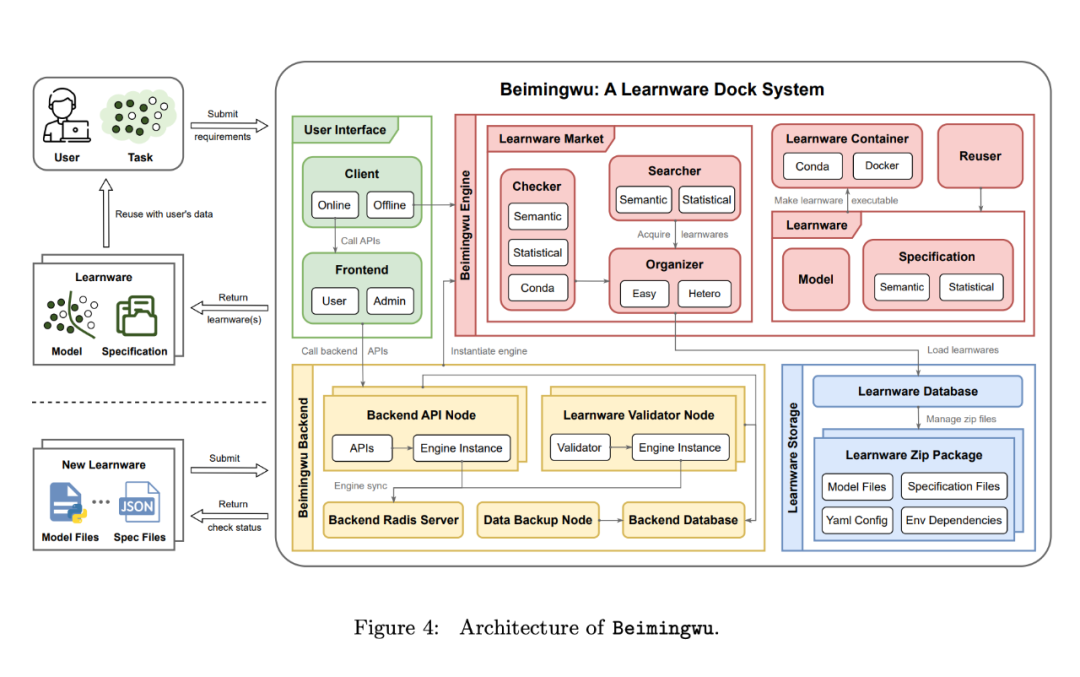
First look at the overview of each layer:
Learningware Storage Layer. In Beimingwu, learning materials are stored in compressed packages. These compressed packages mainly include four types of files: model files, specification files, model execution environment dependency files and learning software configuration files.
These learningware compressed packages are centrally managed by the learningware database. The learning item table in the database stores key information, including the learning item ID, storage path, and learning item status (such as unverified and verified). This database provides a unified interface for Beimingwu's subsequent core engines to access learning information.
Additionally, the database can be built using SQLite (suitable for easy setup in development and experimental environments) or PostgreSQL (recommended for stable deployment in production environments), both using the same interface.
Core Engine Layer. In order to maintain the simplicity and structure of Beimingwu, the authors separated the core components and algorithms from a large number of engineering details. These extracted components can now be used as learning software python packages, which are the core engine of Beimingwu.
As the core of the system, this engine covers all processes in the learningware paradigm, including learningware submission, usability testing, organization, identification, deployment and reuse. It runs independently of the background and the foreground, and provides a comprehensive algorithm interface for learning software-related tasks and research experiments.
In addition, specifications are the core component of the engine, representing each model from a semantic and statistical perspective, and connecting various important components in the learning software system. In addition to the specifications generated when developers submit models, the engine can also use system knowledge to generate new system specifications for learning software, thereby enhancing the management of learning software and further characterizing its capabilities.
In contrast to existing model management platforms, such as Hugging Face, which only passively collect and host models, allowing users to determine the model's capabilities and relevance to the task, Beimingwu uses its engine to , actively manage learning materials with a new system architecture. This active management is not limited to collection and storage. The system organizes learning materials according to protocols, can match relevant learning materials according to user task requirements, and provides corresponding learning software reuse and deployment methods.
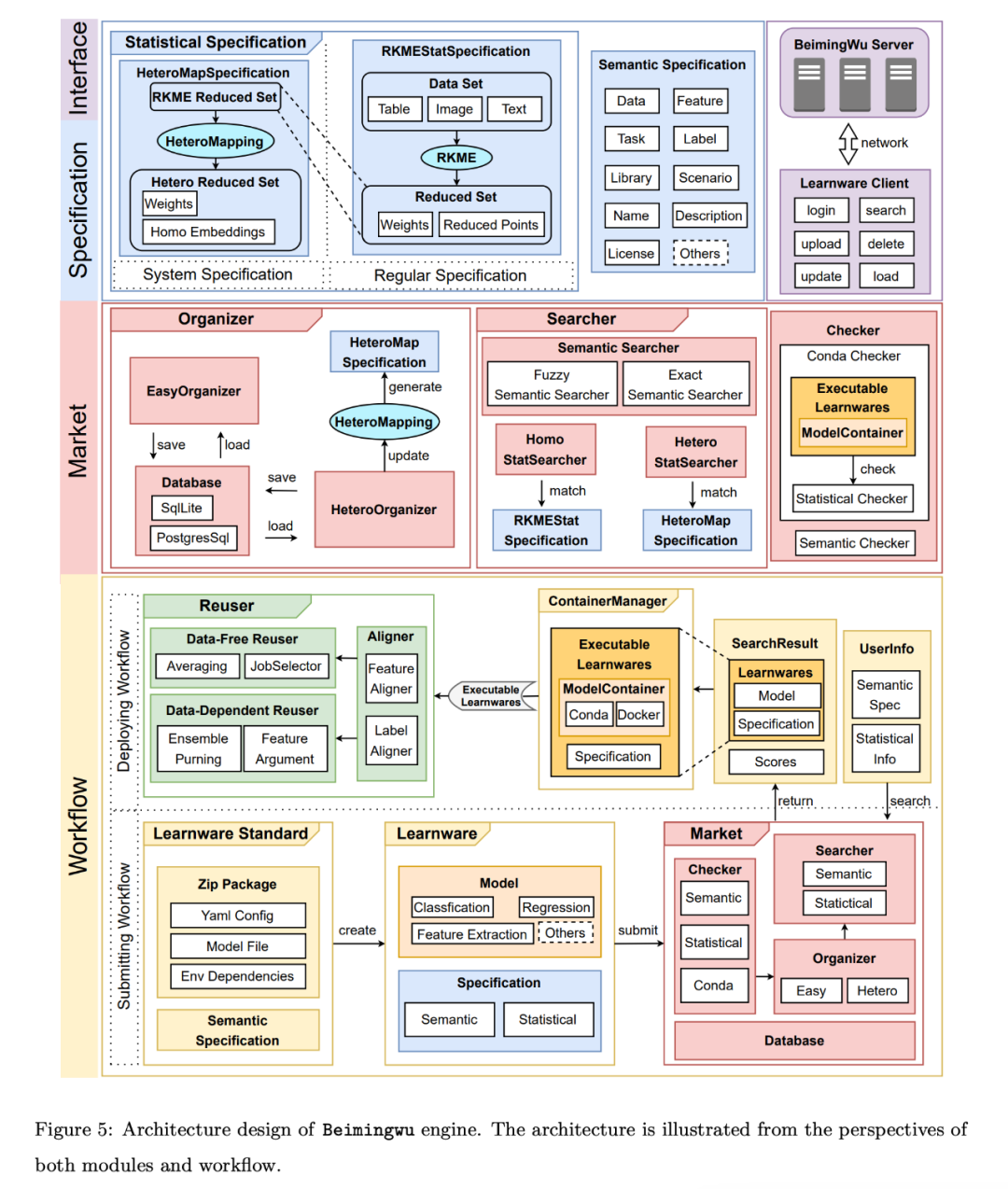
The core module design is as follows:
System backend layer. In order to achieve stable deployment of Beimingwu, the author developed the system backend based on the core engine layer. Through the design of multiple modules and a large amount of engineering development, Beimingwu now has the ability to stably deploy online, providing a unified back-end application program interface for the front-end and client.
In order to ensure efficient and stable operation of the system, the author has carried out a number of engineering optimizations in the system backend layer, including asynchronous learning software verification, high concurrency across multiple backend nodes, interface-level permission management, and backend database reading and writing. Separation and automatic backup of system data.
User Interface Layer. In order to facilitate the use of Beimingwu users, the author developed the corresponding user interface layer, including a network-based browser front-end and command line client.
The web-based front-end provides both user and administrator versions, providing various user interaction and system management pages. In addition, it supports multi-node deployment for smooth access to the Beimingwu system.
The command line client is integrated with the learningware python package. By calling the corresponding interface, users can call the backend online API through the front end to access the relevant modules and algorithms of the learning software.
Experimental Evaluation
In Section 5, the author constructs various types of basic experimental scenarios to evaluate specification generation on table, image and text data , a benchmark algorithm for learning piece identification and reuse.
Tabular Data Experiment
On various tabular data sets, the author first evaluated the identification and reuse of the learning software system with the same feature space as the user task. Performance of learning software. In addition, since tabular tasks usually come from different feature spaces, the authors also evaluated the identification and reuse of learning artifacts from different feature spaces.
Homogeneous Case
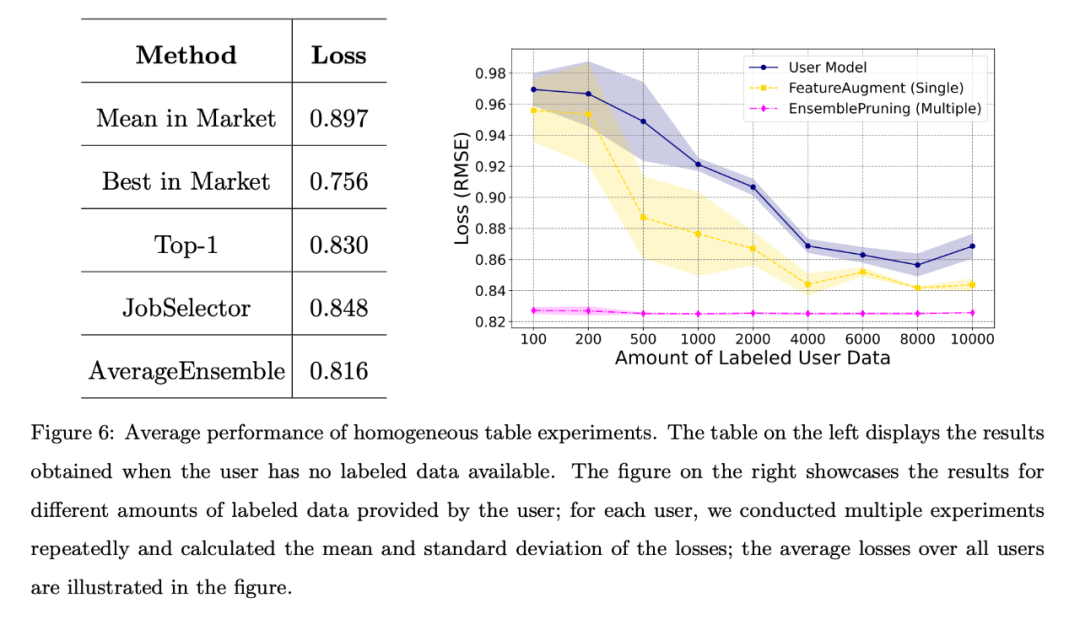
In the homogeneous case, the 53 stores in the PFS dataset act as 53 independent users. Each store utilizes its own test data as user task data and adopts a unified feature engineering approach. These users can then search the base system for homogeneous learning items that share the same feature space as their tasks.
When the user has no labeled data or the amount of labeled data is limited, the author compared different baseline algorithms, and the average loss of all users is shown in Figure 6. The left table shows that the data-free approach is much better than randomly selecting and deploying a learnware from the market; the right chart shows that when the user has limited training data, identifying and reusing single or multiple learnware is better than user-trained models. Better performance.
Heterogeneous Cases
According to the similarity between software on the market and user tasks, heterogeneous cases can be further divided into different feature engineering and different tasks Scenes.
Different feature engineering scenarios: The results shown on the left in Figure 7 show that even if the user lacks annotation data, the learning software in the system can show strong performance, especially the AverageEnsemble that reuses multiple learning software method.
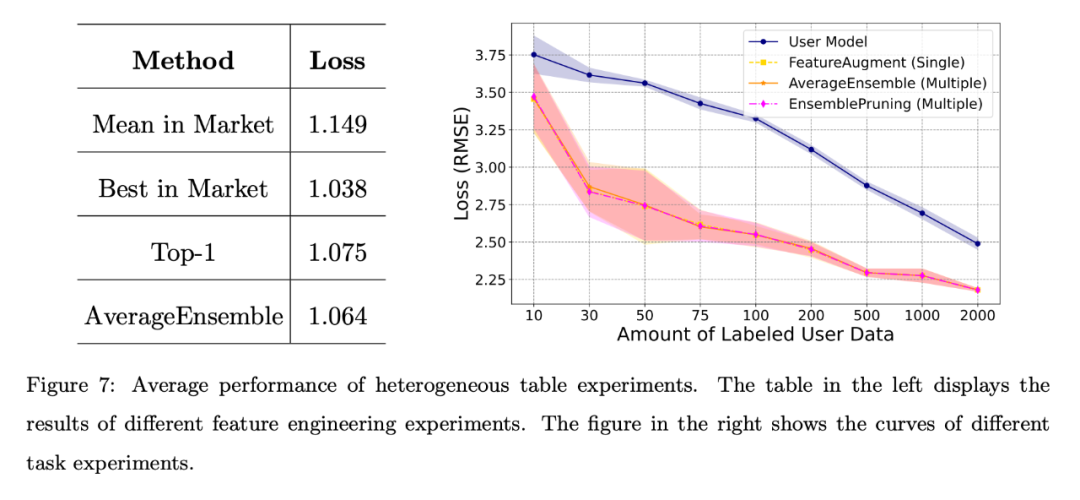
Different mission scenarios. The right side of Figure 7 shows the loss curves of the user-self-trained model and several learning-ware reuse methods. Obviously, experimental verification of heterogeneous learning components is beneficial when the amount of user annotated data is limited, and helps to better align with the user's feature space.
Image and text data experiments
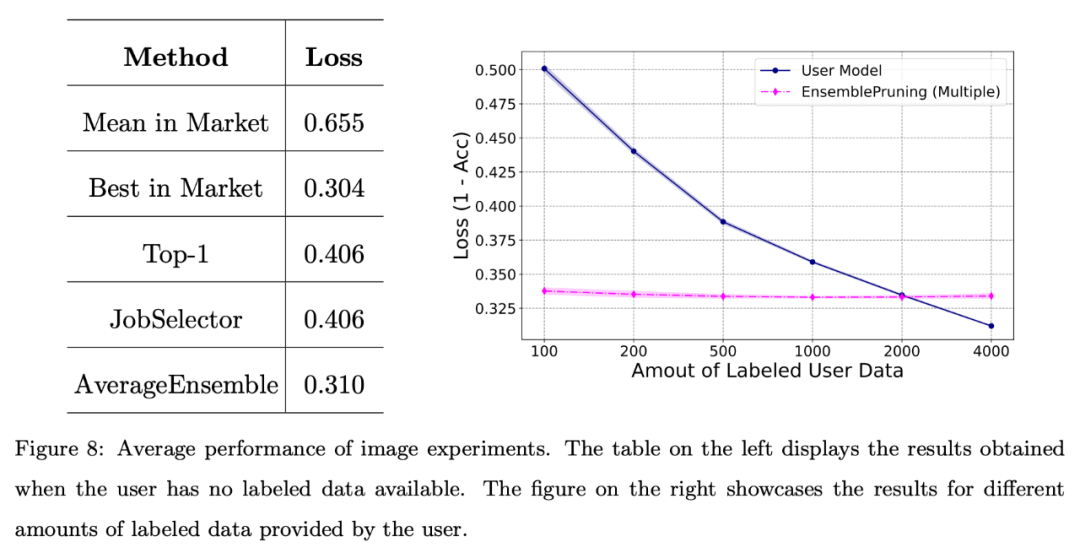
In addition, the author conducted a basic evaluation of the system on image data sets.
Figure 8 shows that leveraging a learning base system can yield good performance when users face scarcity of annotated data or only have a limited amount of data (fewer than 2000 instances).
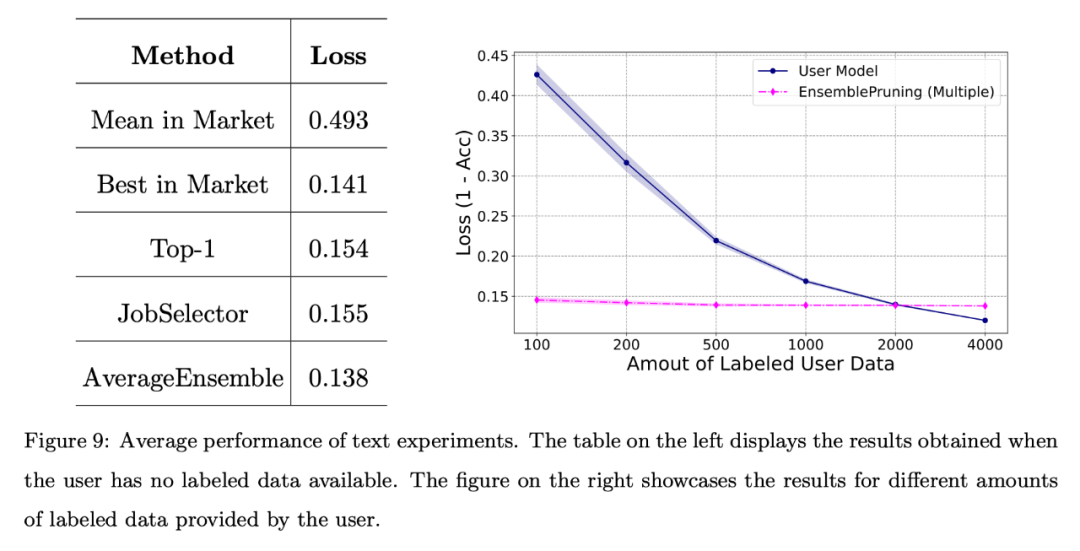
#Finally, the author conducts a basic evaluation of the system on a benchmark text data set. Feature space alignment via a unified feature extractor.
The results are shown in Figure 9. Likewise, even when no annotation data is provided, the performance achieved through learningware identification and reuse is comparable to the best learningware in the system. Additionally, leveraging the learning base system resulted in approximately 2000 fewer samples compared to training the model from scratch.
For more research details, please refer to the original paper.
The above is the detailed content of In the era of big models, NTU Zhou Zhihua is immersed in studying software, and his latest paper is online. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Where is the address of the World VR Industry Conference?
- The world's first 5G RedCap industry alliance was established to accelerate the development of 5G technology
- Taking the 'Exhibition Express', Qingdao Artificial Intelligence Industrial Park explores new ways to attract investment
- Feature article|The demand for computing power explodes under the boom of AI large models: Lingang wants to build a tens of billions industry, and SenseTime will be the 'chain master'
- Let's build digital Guangxi together and go to a digital future together! 2023 Guangxi Kunpeng Shengteng Artificial Intelligence Industry Ecological Conference was successfully held