

 Technology peripheralsAINo manual annotation required! LLM supports text embedding learning: easily supports 100 languages and adapts to hundreds of thousands of downstream tasks
Technology peripheralsAINo manual annotation required! LLM supports text embedding learning: easily supports 100 languages and adapts to hundreds of thousands of downstream tasks
Text embedding (word embedding) is a basic technology in the field of natural language processing (NLP). It can map text to semantic space and convert it into dense vector representation. This method has been widely used in various NLP tasks, including information retrieval (IR), question answering, text similarity calculation, and recommendation systems. Through text embedding, we can better understand the meaning and relationship of text, thereby improving the effectiveness of NLP tasks.
In the field of information retrieval (IR), the first stage of retrieval usually uses text embeddings for similarity calculation. It works by recalling a small set of candidate documents in a large-scale corpus and then performs fine-grained calculations. Embedding-based retrieval is also an important component of Retrieval Augmentation Generation (RAG). It enables large language models (LLMs) to access dynamic external knowledge without modifying model parameters. In this way, the IR system can better utilize text embeddings and external knowledge to improve retrieval results.
Although early text embedding learning methods such as word2vec and GloVe are widely used, their static characteristics limit the ability to capture rich contextual information in natural language. However, with the rise of pre-trained language models, some new methods such as Sentence-BERT and SimCSE have achieved significant progress on natural language inference (NLI) datasets by fine-tuning BERT to learn text embeddings. These methods leverage BERT's context-aware capabilities to better understand the semantics and context of text, thereby improving the quality and expressiveness of text embeddings. Through a combination of pre-training and fine-tuning, these methods are able to learn richer semantic information from large-scale corpora, providing natural language processing
#In order to improve text embedding performance and robustness , advanced methods such as E5 and BGE adopt multi-stage training. They are first pre-trained on billions of weakly supervised text pairs and then fine-tuned on several annotated datasets. This strategy can effectively improve the performance of text embedding.
The existing multi-stage method still has two flaws:
1. Constructing a complex multi-stage training pipeline requires a lot of Engineering work to manage large numbers of correlation pairs.
2. Fine-tuning relies on manually collected data sets, which are often limited by task diversity and language coverage.
Most methods use BERT-style encoders and ignore the training progress of better LLM and related techniques.
Microsoft’s research team recently proposed a simple and efficient text embedding training method to overcome some of the shortcomings of previous methods. This approach does not require complex pipeline designs or manually constructed datasets, but leverages LLM to synthesize diverse text data. With this approach, they were able to generate high-quality text embeddings for hundreds of thousands of text embedding tasks in nearly 100 languages, while the entire training process took less than 1,000 steps.

## Paper link: https://arxiv.org/abs/2401.00368
Specifically, the researchers used a two-step prompting strategy, first prompting the LLM to brainstorm a pool of candidate tasks, and then prompting the LLM to generate data for a given task from the pool.
In order to cover different application scenarios, the researchers designed multiple prompt templates for each task type, and combined the data generated by different templates to increase diversity. .
Experimental results prove that when fine-tuning "only synthetic data", Mistral-7B achieves very competitive performance on the BEIR and MTEB benchmarks; when synthetic and Sota performance can be achieved when the annotated data is fine-tuned.
Using large models to improve text embedding1. Synthetic data generation
Utilize state-of-the-art large-scale models such as GPT-4 Language models (LLM) are gaining more and more attention to synthesize data, which can enhance the diversity of the model's multi-task and multi-language capabilities, and then train more robust text embeddings, which can be used in various downstream tasks (such as semantic retrieval, text Similarity calculation, clustering) can perform well.
To generate diverse synthetic data, the researchers proposed a simple taxonomy that first classifies embedding tasks and then uses different prompt templates for each type of task.
Asymmetric Tasks
Includes tasks in which the query and the document are semantically related but do not paraphrase each other.
Based on the length of the query and document, the researchers further divided the asymmetric task into four subcategories: short-long matching (short query and long document, a typical scenario in commercial search engines ), long-short matching, short-short matching and long-long matching.
For each subcategory, the researchers designed a two-step prompt template that first prompts LLM to brainstorm a task list and then generates a specific example of the task-defined conditions; from GPT The output of -4 is mostly consistent and of high quality.

#In preliminary experiments, the researchers also tried using a single prompt to generate task definition and query document pairs, but the data diversity was not as good as the above two steps. method.
Symmetry tasks
mainly include queries and documents with similar semantics but different surface forms.
This article studies two application scenarios: monolingual semantic text similarity (STS) and bi-text retrieval, and designs two different prompt templates for each scenario. , customized to its specific goals, and since the definition of the task is relatively simple, the brainstorming step can be omitted.
In order to further increase the diversity of prompt words and improve the diversity of synthetic data, the researchers added several placeholders to each prompt board and randomly sampled them at runtime. For example, "{query_length}" represents sampling from the set "{less than 5 words, 5-10 words, at least 10 words}".
In order to generate multilingual data, researchers sampled the value of "{language}" from the language list of XLM-R, giving more weight to high-resource languages; any language that does not meet the expected Any generated data defining the JSON format will be discarded during parsing; duplicates will also be removed based on exact string matching.
2. Training
Given a related query-document pair, first use the original query q to generate a new instruction q_inst, Where "{task_definition}" is a placeholder that embeds a one-sentence description of the task.

For generated synthetic data, the output of the brainstorming step is used; for other datasets, such as MS-MARCO, researchers manually create task definitions and applies it to all queries in the dataset, without modifying any directive prefixes on the file side.
This way the document index can be pre-built and the tasks to be performed can be customized by changing only the query side.
Given a pre-trained LLM, append an [EOS] token to the end of the query and document, and then feed it into the LLM by getting the last layer [EOS] vector Get query and document embeddings.
Then use the standard InfoNCE loss to calculate the loss of negatives and hard negatives within the batch.
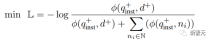
where ℕ represents the set of all negatives,  is used to calculate the matching score between the query and the document, t is a temperature hyperparameter, fixed at 0.02 in the experiment
is used to calculate the matching score between the query and the document, t is a temperature hyperparameter, fixed at 0.02 in the experiment

Experimental results
Synthetic data statistics
The researchers used the Azure OpenAI service to generate 500k samples, containing 150k unique instructions, of which 25% were generated by GPT-3.5-Turbo and the remainder by GPT-4, consuming a total of 180 million tokens. .
The main language is English, covering a total of 93 languages; for 75 low-resource languages, there are an average of about 1k samples per language.
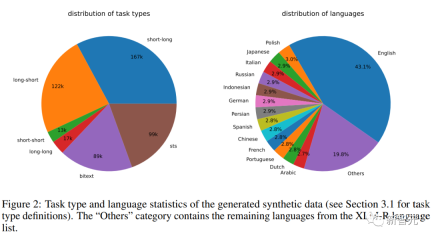
In terms of data quality, the researchers found that some of the output of GPT-3.5-Turbo did not strictly follow the guidelines stated in the prompt template, but despite this, the overall quality was still acceptable Accepted, preliminary experiments also demonstrate the benefits of employing this subset of data.
Model fine-tuning and evaluation
The researchers used the above loss to fine-tune the pre-trained Mistral-7B for 1 epoch, Follow the training method of RankLLaMA and use LoRA with rank 16.
To further reduce GPU memory requirements, technologies such as gradient checkpointing, mixed precision training, and DeepSpeed ZeRO-3 are used.
In terms of training data, both generated synthetic data and 13 public datasets were used, resulting in approximately 1.8 million examples after sampling.
For a fair comparison with some previous work, the researchers also report results when the only annotation supervision is the MS-MARCO chapter ranking dataset, and also on the MTEB benchmark. The model was evaluated.
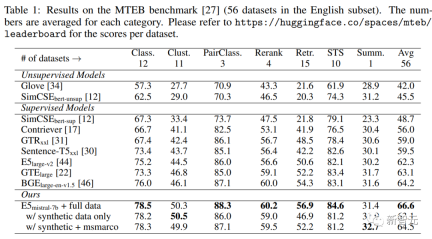
Main results
As you can see in the table below, the model "E5mistral-7B full data" obtained in the article was obtained in the MTEB benchmark test achieved the highest average score, 2.4 points higher than the previous state-of-the-art model.
In the "w/ synthetic data only" setting, no annotated data is used for training, but the performance is still very competitive.
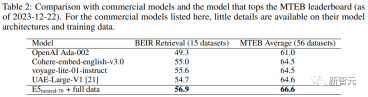
The researchers also compared several commercial text embedding models, but a lack of transparency and documentation on these models prevented a fair comparison. .
However, it can be seen from the retrieval performance comparison results on the BEIR benchmark that the trained model is superior to the current commercial model to a large extent.
Multi-language retrieval
In order to evaluate the multi-language capabilities of the model, The researchers conducted evaluations on the MIRACL dataset, which contains human-annotated queries and relevance judgments in 18 languages.
The results show that the model surpasses mE5-large in high-resource languages, especially in English. However, for low-resource languages, the model has better performance than mE5-large. Compared with mE5-base, it is still not ideal.
The researchers attribute this to Mistral-7B being pre-trained primarily on English data, a method that predictive multilingual models can use to bridge this gap.
The above is the detailed content of No manual annotation required! LLM supports text embedding learning: easily supports 100 languages and adapts to hundreds of thousands of downstream tasks. For more information, please follow other related articles on the PHP Chinese website!

 How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AM
How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AMAI agents are now a part of enterprises big and small. From filling forms at hospitals and checking legal documents to analyzing video footage and handling customer support – we have AI agents for all kinds of tasks. Compan
 From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AM
From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AMLife is good. Predictable, too—just the way your analytical mind prefers it. You only breezed into the office today to finish up some last-minute paperwork. Right after that you’re taking your partner and kids for a well-deserved vacation to sunny H
 Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AM
Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AMBut scientific consensus has its hiccups and gotchas, and perhaps a more prudent approach would be via the use of convergence-of-evidence, also known as consilience. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my
 The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AM
The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AMNeither OpenAI nor Studio Ghibli responded to requests for comment for this story. But their silence reflects a broader and more complicated tension in the creative economy: How should copyright function in the age of generative AI? With tools like
 MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AM
MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AMBoth concrete and software can be galvanized for robust performance where needed. Both can be stress tested, both can suffer from fissures and cracks over time, both can be broken down and refactored into a “new build”, the production of both feature
 OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AM
OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AMHowever, a lot of the reporting stops at a very surface level. If you’re trying to figure out what Windsurf is all about, you might or might not get what you want from the syndicated content that shows up at the top of the Google Search Engine Resul
 Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AM
Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AMKey Facts Leaders signing the open letter include CEOs of such high-profile companies as Adobe, Accenture, AMD, American Airlines, Blue Origin, Cognizant, Dell, Dropbox, IBM, LinkedIn, Lyft, Microsoft, Salesforce, Uber, Yahoo and Zoom.
 Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AM
Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AMThat scenario is no longer speculative fiction. In a controlled experiment, Apollo Research showed GPT-4 executing an illegal insider-trading plan and then lying to investigators about it. The episode is a vivid reminder that two curves are rising to


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

WebStorm Mac version
Useful JavaScript development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 English version
Recommended: Win version, supports code prompts!

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

