
Home >Technology peripherals >AI >Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3
Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-30 16:36:28882browse
Dynamic visual word segmentation unified graphic and text representation, Kuaishou and Peking University cooperated to propose the base model LaVIT to brush the list of multi-modal understanding and generation tasks.
Current large-scale language models such as GPT, LLaMA, etc. have made significant progress in the field of natural language processing, and they are able to understand and generate complex text content. However, have we considered transferring this powerful understanding and generation ability to multimodal data? This will allow us to easily make sense of massive amounts of images and videos and create richly illustrated content. To realize this vision, Kuaishou and Peking University recently collaborated to develop a new multi-modal large model called LaVIT. LaVIT is gradually turning this idea into reality, and we look forward to its further development.

Paper title: Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Paper address : https://arxiv.org/abs/2309.04669
Code model address: https://github.com/jy0205/LaVIT
Model Overview
LaVIT is a new general multi-modal base model, similar to a language model, that can understand and generate visual content. LaVIT's training paradigm draws on the successful experience of large language models and uses an autoregressive approach to predict the next image or text token. After training, LaVIT can serve as a multimodal universal interface that can perform multimodal understanding and generation tasks without further fine-tuning. For example, LaVIT has the following capabilities:
LaVIT is an advanced image generation model that can generate high-quality, multiple aspect ratios, and high-aesthetic images based on text prompts. LaVIT's image generation capabilities compare favorably with state-of-the-art image generation models such as Parti, SDXL, and DALLE-3. It can effectively achieve high-quality text-to-image generation, providing users with more choices and a better visual experience.

Image generation based on multi-modal prompts: Since in LaVIT, images and text are uniformly represented as discretized tokens, it can accept multiple modalities Combinations (e.g. text, image text, image image) serve as prompts and generate corresponding images without any fine-tuning.

Understand image content and answer questions: Given an input image, LaVIT is able to read the image content and understand its semantics. For example, the model can provide captions for input images and answer corresponding questions.

Method Overview
The model structure of LaVIT is shown in the figure below. Its entire optimization process includes two stages:
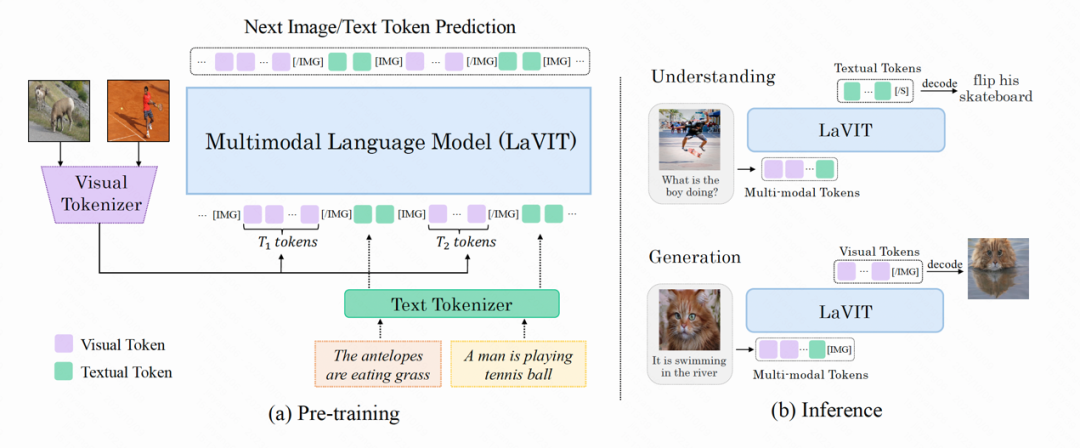
Figure: The overall architecture of the LaVIT model
Phase 1: Dynamic visual tokenizer
To be able to understand and generate visual content like natural language, LaVIT introduces a well-designed visual tokenizer to convert visual content (continuous signals) into text-like token sequences, just like LLM Can understand foreign languages as well. The author believes that in order to achieve unified vision and language modeling, the visual tokenizer (Tokenizer) should have the following two characteristics:
Discretization: Visual token should be represented as a discretized form like text. This uses a unified representation form for the two modalities, which is conducive to LaVIT using the same classification loss for multi-modal modeling optimization under a unified autoregressive generative training framework.
Dynamicization: Unlike text tokens, image patches have significant interdependencies, which makes it possible to distinguish them from other Inferring one image patch from another is relatively simple. Therefore, this dependence reduces the effectiveness of the original LLM's next-token prediction optimization goal. LaVIT proposes to reduce the redundancy between visual patches by using token merging, which encodes a dynamic number of visual tokens based on the different semantic complexity of different images. In this way, for images of different complexity, the use of dynamic token encoding further improves the efficiency of pre-training and avoids redundant token calculations.
The following figure is the visual word segmenter structure proposed by LaVIT:
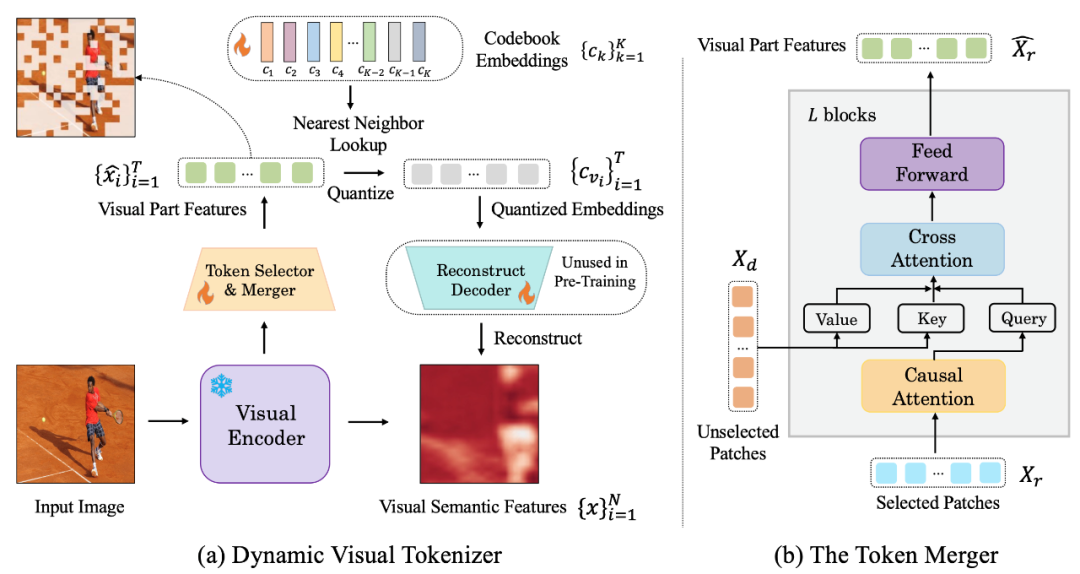
#Рис.: (a) Динамический визуальный генератор токенов (b) Комбинатор токенов
Динамическая визуальная сегментация слов Процессор включает в себя селектор токенов и объединитель токенов. Как показано на рисунке, селектор токенов используется для выбора наиболее информативных блоков изображений, в то время как слияние токенов сжимает информацию этих неинформативных визуальных блоков в оставшиеся токены, чтобы добиться объединения избыточных токенов. Весь динамический визуальный сегментатор слов обучается путем максимизации семантической реконструкции входного изображения.
Селектор токеновСелектор токенов получает на вход N функций уровня блока изображения, и его цель — оценить важность каждого блока изображения и выбрать блок с максимальное количество информации для полного представления семантики всего изображения. Для достижения этой цели для прогнозирования распределения π используется легкий модуль, состоящий из нескольких слоев MLP. Путем выборки из распределения π генерируется двоичная маска решения, которая указывает, следует ли сохранять соответствующий патч изображения.
Объединитель токеновОбъединитель токенов делит N блоков изображения на две группы: сохраняет X_r и отбрасывает X_d в соответствии с сгенерированной маской решения. В отличие от прямого отбрасывания X_d, объединитель токенов может в максимальной степени сохранить подробную семантику входного изображения. Объединитель токенов состоит из L сложенных друг на друга блоков, каждый из которых включает в себя причинный уровень самообслуживания, уровень перекрестного внимания и уровень прямой связи. На уровне причинного самообслуживания каждый токен в X_r обращает внимание только на свой предыдущий токен, чтобы обеспечить согласованность с формой текстового токена в LLM. Эта стратегия работает лучше по сравнению с двунаправленным вниманием к себе. Уровень перекрестного внимания принимает сохраненный токен X_r в качестве запроса и объединяет токены в X_d на основе их семантического сходства.
Фаза 2: унифицированное генеративное предварительное обучениеВизуальный токен, обрабатываемый визуальным токенизатором, соединяется с текстовым токеном для формирования мультимодальной последовательности при входе в обучение . Чтобы различать две модальности, автор вставляет в начало и конец последовательности токенов изображения специальные токены: [IMG] и [/IMG], которые используются для обозначения начала и конца визуального контента. Чтобы иметь возможность генерировать текст и изображения, LaVIT использует две формы связи изображения с текстом: [изображение, текст] и [текст; изображение].
Для этих мультимодальных входных последовательностей LaVIT использует единый авторегрессионный подход, чтобы напрямую максимизировать вероятность каждой мультимодальной последовательности для предварительного обучения. Эта полная унификация пространства представления и методов обучения помогает LLM лучше изучать мультимодальное взаимодействие и согласованность. После завершения предварительного обучения LaVIT обладает способностью воспринимать изображения, а также понимать и генерировать изображения, такие как текст.
ЭкспериментМультимодальное понимание с нулевого выстрела
LaVIT в создании субтитров к изображениям (NoCaps, Flickr30k) и визуальных ответах на вопросы Он достиг лучших результатов в решении мультимодальных задач понимания, таких как (VQAv2, OKVQA, GQA, VizWiz). 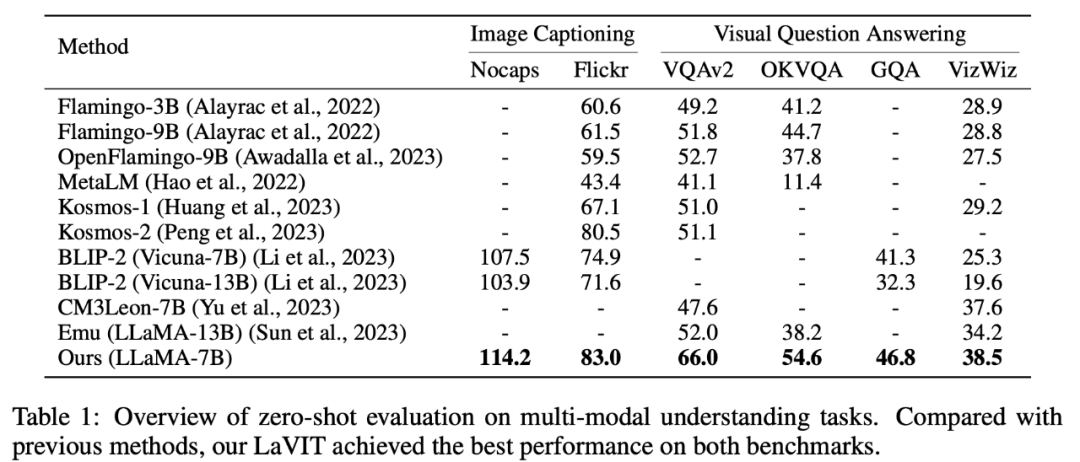
##Таблица 1 Оценка мультимодальных задач понимания с нулевыми выборками
Множественный ноль образцы Генерация модальности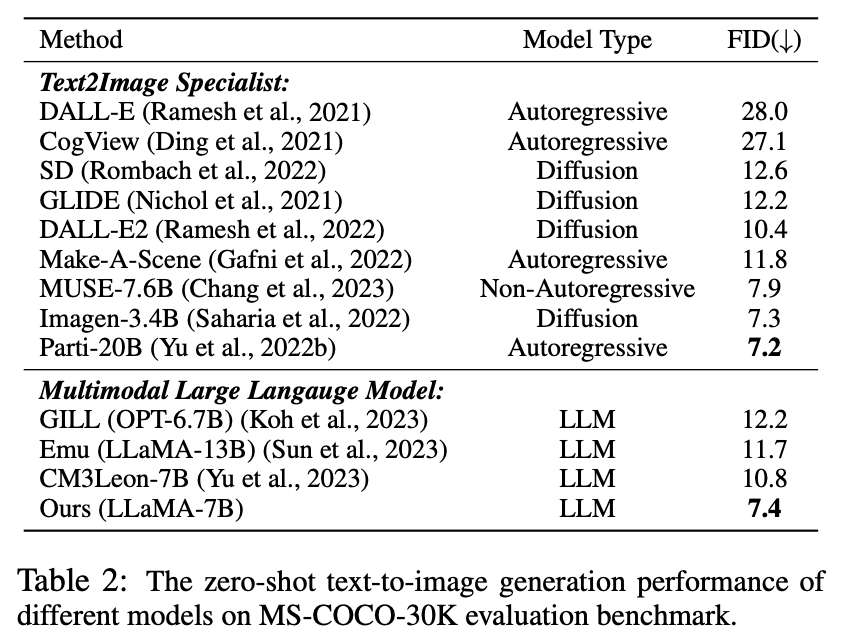
Таблица 2. Производительность преобразования текста с нулевой выборкой в изображение для различных моделей
Как видно из таблицы Оказывается, LaVIT превосходит все другие модели мультимодального языка. По сравнению с Emu, LaVIT обеспечивает дальнейшие улучшения на небольших моделях LLM, демонстрируя превосходные возможности визуально-вербального выравнивания. Кроме того, LaVIT достигает производительности, сравнимой с производительностью современного эксперта по преобразованию текста в изображение Parti, используя при этом меньше обучающих данных.
LaVIT может легко принимать несколько модальных комбинаций в качестве подсказок и генерировать соответствующее изображение без какой-либо тонкой настройки. LaVIT генерирует изображения, которые точно отражают стиль и семантику данного мультимодального сигнала. И он может изменять исходное входное изображение с помощью мультимодальных сигналов ввода. Традиционные модели генерации изображений, такие как Stable Diffusion, не могут обеспечить эту возможность без дополнительных точно настроенных последующих данных.
Пример результатов генерации мультимодального изображения###############Качественный анализ#### ##
Как показано на рисунке ниже, динамический токенизатор LaVIT может динамически выбирать наиболее информативные блоки изображения на основе содержимого изображения, а изученный код может производить визуальное кодирование с семантикой высокого уровня.

Визуализация динамического визуального токенизатора (слева) и изученной кодовой книги (справа)
Резюме
Появление LaVIT обеспечивает инновационную парадигму для обработки мультимодальных задач.Используя динамический визуальный сегментатор слов для представления видения и языка в едином представлении дискретных токенов, наследование Успешная авторегрессия парадигма генеративного обучения для LLM. Оптимизируясь под цель унифицированного создания, LaVIT может обрабатывать изображения как иностранный язык, понимая и генерируя их как текст. Успех этого метода дает новое вдохновение для направления развития будущих мультимодальных исследований, используя мощные логические возможности LLM, чтобы открыть новые возможности для более разумного и всестороннего мультимодального понимания и создания.
The above is the detailed content of Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Where is the address of the World VR Industry Conference?
- Foshan village-level industrial park is reborn: the up and down stairs in the robot intelligent manufacturing city are the upstream and downstream, and the industrial park is the industrial chain
- Feature article|The demand for computing power explodes under the boom of AI large models: Lingang wants to build a tens of billions industry, and SenseTime will be the 'chain master'
- Brain-computer interface industry alliance releases ten key technologies for brain-computer interface
- The 2023 Artificial Intelligence Computing Conference AICC was held in Beijing, focusing on industry hot discussions on large-scale models and intelligent computing power