

 Technology peripheralsAIGraphical language: Kuaishou and Beida multi-modal large models are comparable to DALLE-3
Technology peripheralsAIGraphical language: Kuaishou and Beida multi-modal large models are comparable to DALLE-3Graphical language: Kuaishou and Beida multi-modal large models are comparable to DALLE-3

Current large-scale language models such as GPT, LLaMA, etc. have made significant progress in the field of natural language processing and can understand and generate complex text content. However, can we extend this powerful understanding and generation capabilities to multimodal data? This idea is gradually becoming a reality. The latest multi-modal large model LaVIT was developed by Kuaishou and Peking University. By combining image and video data, it enables the model to easily understand massive multimedia content and assists in the creation of illustrated content. The emergence of LaVIT is of great significance for the understanding and creation of multimedia content. It not only identifies objects, scenes and emotions in images and videos, but also generates natural language descriptions related to them. In this way, we can better utilize multi-modal data and create more vivid and interesting graphic content. The development of LaVIT is an important attempt at large-scale language models in the multi-modal field. It is expected to bring more possibilities to the processing and creation of multimedia content and promote further development in the fields of natural language processing and computer vision.

- Paper title: Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
- Paper address: https://arxiv.org/abs/2309.04669
- Code model address: https://github.com/jy0205/ LaVIT
Model Overview
LaVIT is a new general multimodal base model that can be understood like a language model and generating visual content. It uses a similar training approach to large language models, using an autoregressive approach to predict the next image or text token. Once trained, LaVIT can serve as a general multimodal interface that can perform multimodal understanding and generation tasks without further fine-tuning. For example, LaVIT can achieve the following functions:
LaVIT is a powerful text-to-image generation model that is able to generate high quality, multiple aspect ratios and high aesthetics based on given text prompts Image. Compared with state-of-the-art image generation models such as Parti, SDXL and DALLE-3, LaVIT has comparable image generation capabilities. What makes it unique is its ability to generate diverse images while maintaining high quality and aesthetics. Whether in portrait or landscape orientation, LaVIT is capable of producing satisfying image compositions. By combining advanced technology and high-quality training data, LaVIT provides users with an outstanding text-to-image

In LaVIT, images and Text is represented as discretized tokens. Therefore, it can leverage multimodal cues for image generation, including combinations of text, image text, and image image. This multi-modal generation does not require any fine-tuning, and the system can generate corresponding images based on prompts.

LaVIT is an image understanding model that can read images and understand their semantics. It can generate relevant descriptions for input images and answer relevant questions.

Method Overview
The model structure of LaVIT is shown in the figure below. The entire optimization process includes two Stages:
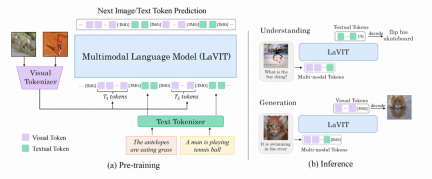
Figure: The overall architecture of the LaVIT model
Phase 1: Dynamic Visual Tokenizer
To be able to understand and generate visual content like natural language, LaVIT introduces a well-designed visual tokenizer for Visual content (continuous signals) is converted into a text-like sequence of tokens, just like a foreign language that LLM can understand. The author believes that in order to achieve unified visual and language modeling, the visual tokenizer (Tokenizer) should have the following two characteristics:
- Discretization: Visual tokens should be represented as discretized forms like text. This uses a unified representation form for the two modalities, which is conducive to LaVIT using the same classification loss for multi-modal modeling optimization under a unified autoregressive generative training framework.
- Dynamic: Unlike text tokens, image patches have significant interdependencies. This makes it relatively simple to infer another image patch from other image patches. Therefore, this dependence reduces the effectiveness of the original LLM's next-token prediction optimization goal. LaVIT proposes to reduce the redundancy between visual patches by using token merging, which encodes a dynamic number of visual tokens based on the different semantic complexity of different images. In this way, for images of different complexity, the use of dynamic token encoding further improves the efficiency of pre-training and avoids redundant token calculations.
The following picture is the visual word segmenter structure proposed by LaVIT:
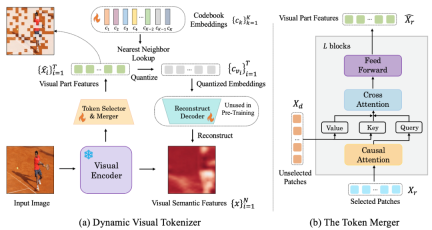
Picture: (a) Dynamic visual token generator (b) token combiner
The dynamic visual tokenizer includes a token selector and a token combiner. As shown in the figure, the token selector is used to select the most informative image blocks, while the token merger compresses the information of those uninformative visual blocks into the retained tokens to achieve the merging of redundant tokens. The entire dynamic visual word segmenter is trained by maximizing the semantic reconstruction of the input image.
Token selector
##Token selector receives N image block levels Features are taken as input, and the goal is to evaluate the importance of each image patch and select the most informative patch to fully represent the semantics of the entire image. To achieve this goal, a lightweight module consisting of multiple MLP layers is used to predict the distribution π. By sampling from the distribution π, a binary decision mask is generated that indicates whether to keep the corresponding image patch.
Token combiner
Token combiner divides N image blocks according to the generated decision mask There are two groups for retaining X_r and discarding X_d. Unlike discarding X_d directly, the token combiner can preserve the detailed semantics of the input image to the maximum extent. The token combiner consists of L stacked blocks, each of which includes a causal self-attention layer, a cross-attention layer, and a feed-forward layer. In the causal self-attention layer, each token in X_r only pays attention to its previous token to ensure consistency with the text token form in LLM. This strategy performs better compared to bidirectional self-attention. The cross-attention layer takes the retained token X_r as query and merges the tokens in X_d based on their semantic similarity.
Phase 2: Unified generative pre-training
Visual token and text processed by visual tokenizer The tokens are connected to form a multi-modal sequence as input during training. In order to distinguish the two modalities, the author inserts special tokens at the beginning and end of the image token sequence: [IMG] and [/IMG], which are used to indicate the beginning and end of visual content. In order to be able to generate text and images, LaVIT uses two image-text connection forms: [image, text] and [text; image].
For these multi-modal input sequences, LaVIT uses a unified, autoregressive approach to directly maximize the likelihood of each multi-modal sequence for pre-training. This complete unification of representation space and training methods helps LLM better learn multi-modal interaction and alignment. After pre-training is completed, LaVIT has the ability to perceive images and can understand and generate images like text.
Experiment
Zero-shot multimodal understanding
LaVIT It has achieved leading performance on zero-shot multi-modal understanding tasks such as image subtitle generation (NoCaps, Flickr30k) and visual question answering (VQAv2, OKVQA, GQA, VizWiz).
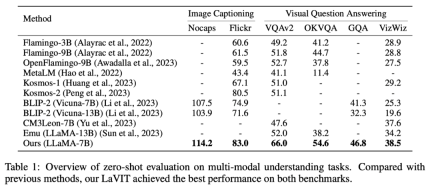
Table 1 Evaluation of multi-modal understanding tasks with zero samples
Multiple zero samples Modal generation
In this experiment, since the proposed visual tokenizer is able to represent images as discretized tokens, LaVIT has the ability to synthesize images by generating text-like visual tokens through autoregression. The author conducted a quantitative evaluation of the image synthesis performance of the model under zero-sample text conditions, and the comparison results are shown in Table 2.

Table 2 Zero-sample text to image generation performance of different models
As can be seen from the table It turns out that LaVIT outperforms all other multi-modal language models. Compared to Emu, LaVIT achieves further improvements on smaller LLM models, demonstrating excellent visual-verbal alignment capabilities. Furthermore, LaVIT achieves comparable performance to the state-of-the-art text-to-image expert Parti while using less training data.
Multi-modal prompt image generation
LaVIT is able to seamlessly accepts multiple modal combinations as cues and generates corresponding images without any fine-tuning. LaVIT generates images that accurately reflect the style and semantics of a given multimodal cue. And it can modify the original input image with multi-modal cues of the input. Traditional image generation models such as Stable Diffusion cannot achieve this capability without additional fine-tuned downstream data.

Example of multi-modal image generation results
Qualitative analysis
As shown in the figure below, LaVIT’s dynamic tokenizer can dynamically select the most informative image blocks based on the image content. The learned code can generate high-level Visual encoding of semantics.

Visualization of dynamic visual tokenizer (left) and learned codebook (right)
Summary
The emergence of LaVIT provides an innovative paradigm for the processing of multi-modal tasks. By using a dynamic visual word segmenter to represent vision and language into a unified discrete token representation, inheritance A successful autoregressive generative learning paradigm for LLM. By optimizing under a unified generation goal, LaVIT can treat images as a foreign language, understanding and generating them like text. The success of this method provides new inspiration for the development direction of future multimodal research, using the powerful reasoning capabilities of LLM to open new possibilities for smarter and more comprehensive multimodal understanding and generation.
The above is the detailed content of Graphical language: Kuaishou and Beida multi-modal large models are comparable to DALLE-3. For more information, please follow other related articles on the PHP Chinese website!

 How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AM
How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AMAI agents are now a part of enterprises big and small. From filling forms at hospitals and checking legal documents to analyzing video footage and handling customer support – we have AI agents for all kinds of tasks. Compan
 From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AM
From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AMLife is good. Predictable, too—just the way your analytical mind prefers it. You only breezed into the office today to finish up some last-minute paperwork. Right after that you’re taking your partner and kids for a well-deserved vacation to sunny H
 Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AM
Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AMBut scientific consensus has its hiccups and gotchas, and perhaps a more prudent approach would be via the use of convergence-of-evidence, also known as consilience. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my
 The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AM
The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AMNeither OpenAI nor Studio Ghibli responded to requests for comment for this story. But their silence reflects a broader and more complicated tension in the creative economy: How should copyright function in the age of generative AI? With tools like
 MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AM
MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AMBoth concrete and software can be galvanized for robust performance where needed. Both can be stress tested, both can suffer from fissures and cracks over time, both can be broken down and refactored into a “new build”, the production of both feature
 OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AM
OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AMHowever, a lot of the reporting stops at a very surface level. If you’re trying to figure out what Windsurf is all about, you might or might not get what you want from the syndicated content that shows up at the top of the Google Search Engine Resul
 Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AM
Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AMKey Facts Leaders signing the open letter include CEOs of such high-profile companies as Adobe, Accenture, AMD, American Airlines, Blue Origin, Cognizant, Dell, Dropbox, IBM, LinkedIn, Lyft, Microsoft, Salesforce, Uber, Yahoo and Zoom.
 Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AM
Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AMThat scenario is no longer speculative fiction. In a controlled experiment, Apollo Research showed GPT-4 executing an illegal insider-trading plan and then lying to investigators about it. The episode is a vivid reminder that two curves are rising to


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 Linux new version
SublimeText3 Linux latest version

Dreamweaver Mac version
Visual web development tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

