
Home >Technology peripherals >AI >Multi-modal large models are preferred by young people online with open source: easily run 1080Ti
Multi-modal large models are preferred by young people online with open source: easily run 1080Ti

- WBOYforward
- 2024-01-29 09:15:261045browse
A "young people's first multi-modal large model" called Vary-toy is here!
The model size is less than 2B, it can be trained on consumer-grade graphics cards, and it can run easily on GTX1080ti 8G old graphics cards.
Want to convert a document image into Markdown format? In the past, multiple steps such as text recognition, layout detection and sorting, formula table processing, and text cleaning were required.
Now you only need one command:
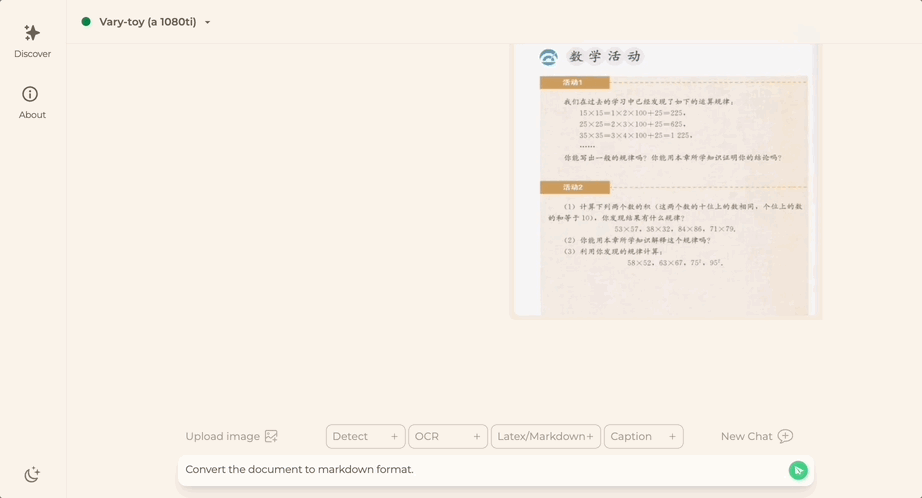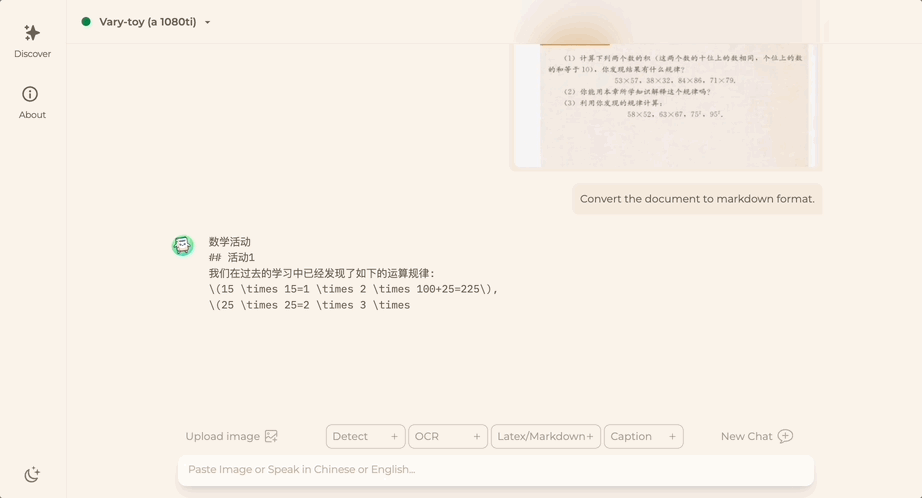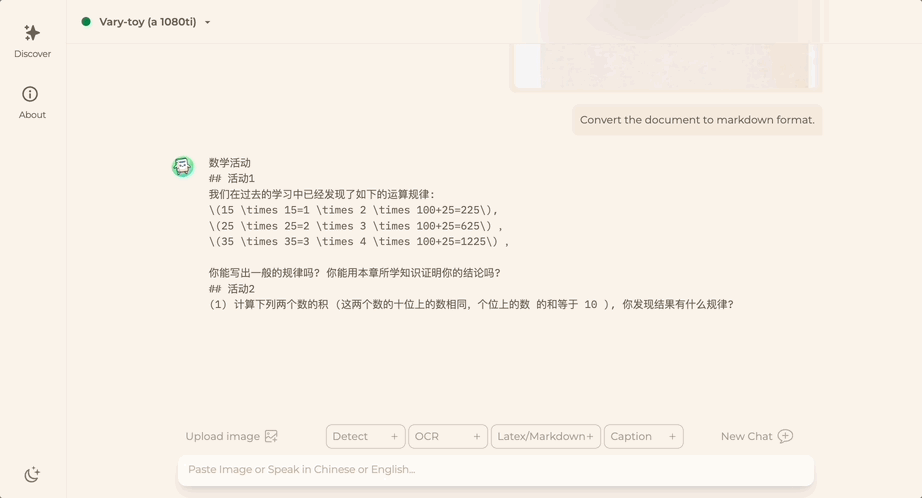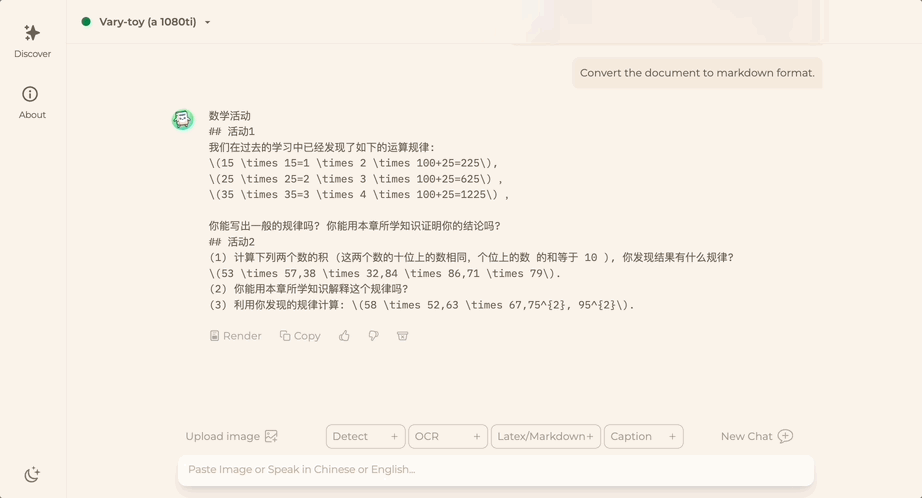
No matter Chinese or English, large sections of text in the picture can be extracted in minutes :

Object detection on a picture can still give specific coordinates:

This The study was jointly proposed by researchers from Megvii, National University of Science and Technology, and Huazhong University of Science and Technology.
According to reports, although Vary-toy is small, it covers almost all capabilities in current mainstream research on LVLM (Large Scale Visual Language Model): Document OCR recognition (Document OCR ), visual positioning(Visual Grounding), image description(Image Caption), visual question answering(VQA).

Now, the Vary-toy code and model are open source, and there is an online demo available for trial play.

While netizens expressed interest, they also focused on 老·GTX1080 and felt like:

“Shrinking version” Vary
In fact, the Vary team released Vary’s first research result “Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models” as early as December last year.
The researchers pointed out the shortcomings of CLIP visual vocabulary in dense perception capabilities, and used a simple and effective vocabulary expansion scheme to provide a new OCR paradigm.
Vary has received widespread attention since its release. Currently, it has 1.2k stars on Github, but many people cannot run it due to limited resources.
Considering that there are relatively few “small” VLMs that are well open sourced and have excellent performance, the team has newly released Vary-toy, which is known as “young people’s first multi-mode large model”.
Compared with Vary, Vary-toy is not only small, but also trains a stronger visual vocabulary. The new vocabulary no longer limits the model to document-level OCR, but It provides a more universal and comprehensive visual vocabulary, which can not only do document-level OCR, but also general visual target detection. So how is this done?
The model structure and training process of Vary-toy are shown in the figure below. In general, the training is divided into two stages.
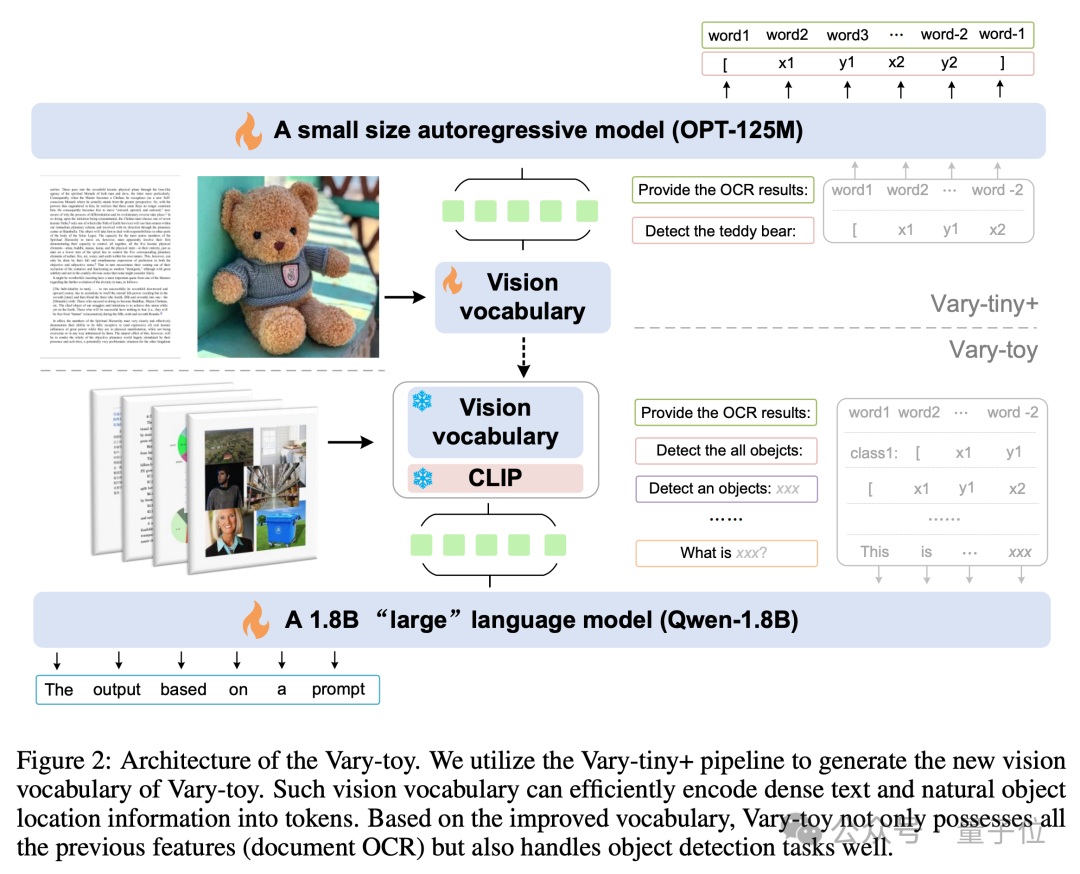 First of all, in the first stage, the Vary-tiny structure is used to pre-train a visual vocabulary that is better than the original Vary. The new visual vocabulary solves the problem of the original Vary. Vary only uses it for document-level OCR, which has the problem of wasting network capacity and not fully utilizing the advantages of SAM pre-training.
First of all, in the first stage, the Vary-tiny structure is used to pre-train a visual vocabulary that is better than the original Vary. The new visual vocabulary solves the problem of the original Vary. Vary only uses it for document-level OCR, which has the problem of wasting network capacity and not fully utilizing the advantages of SAM pre-training.
Then in the second stage, the visual vocabulary trained in the first stage is merged into the final structure for multi-task training/SFT.
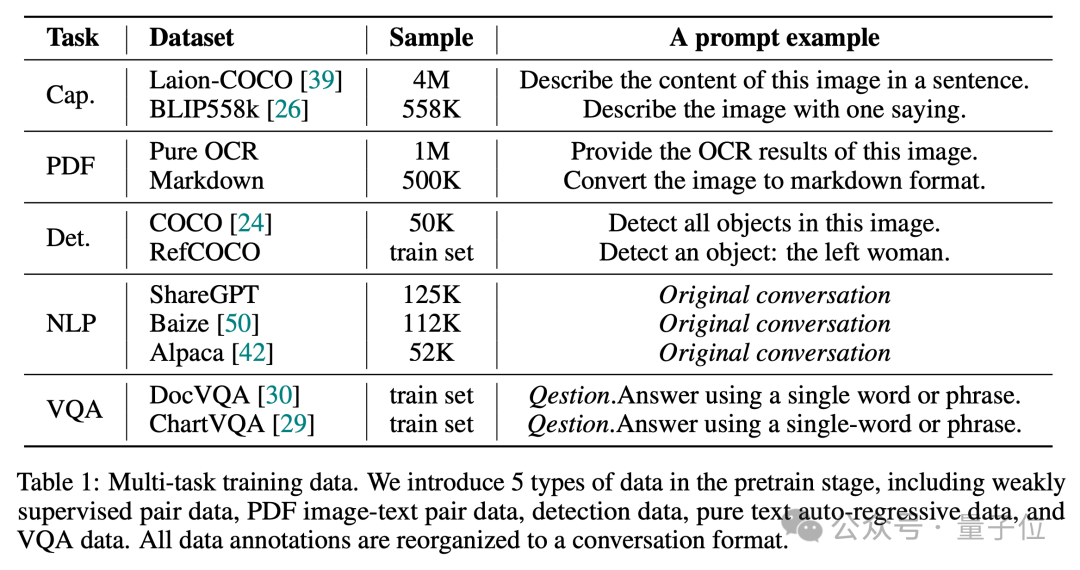
As we all know, a good data ratio is crucial to produce a VLM with comprehensive capabilities.
Therefore, in the pre-training stage, Vary-toy used data from 5 task types to construct dialogues. The data ratio and example prompt are as shown in the figure below:
 In the SFT stage, only LLaVA-80K data is used. For more technical details, please view Vary-toy’s technical report.
In the SFT stage, only LLaVA-80K data is used. For more technical details, please view Vary-toy’s technical report.
Experimental test results
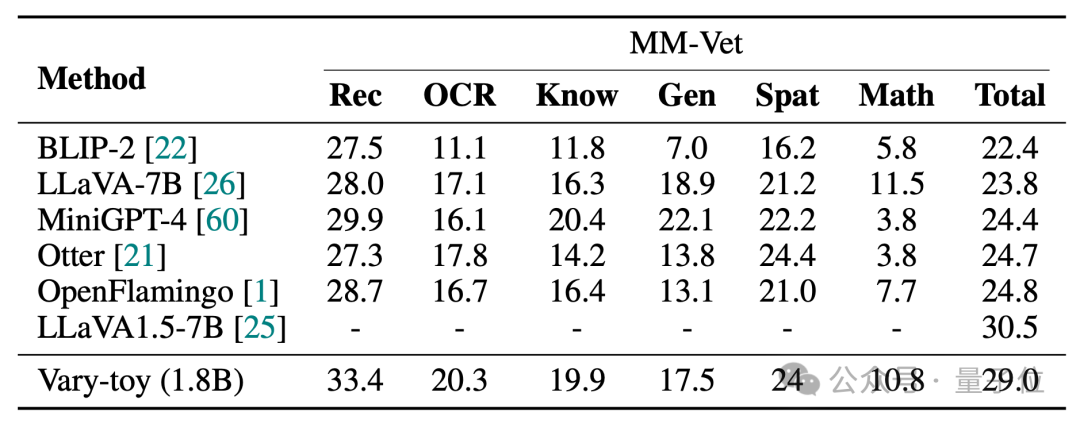
The scores of Vary-toy in the four benchmark tests of DocVQA, ChartQA, RefCOCO, and MMVet are as follows:
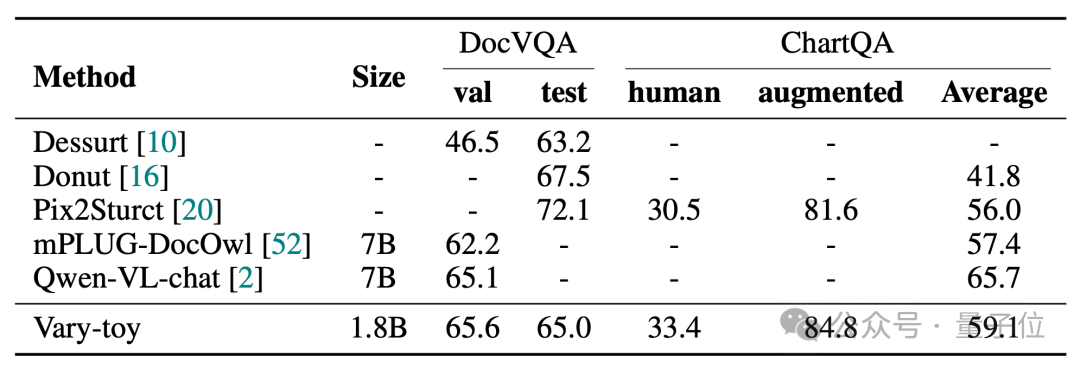
Vary-toy can achieve 65.6% ANLS on DocVQA, 59.1% accuracy on ChartQA, and 88.1% accuracy on RefCOCO:
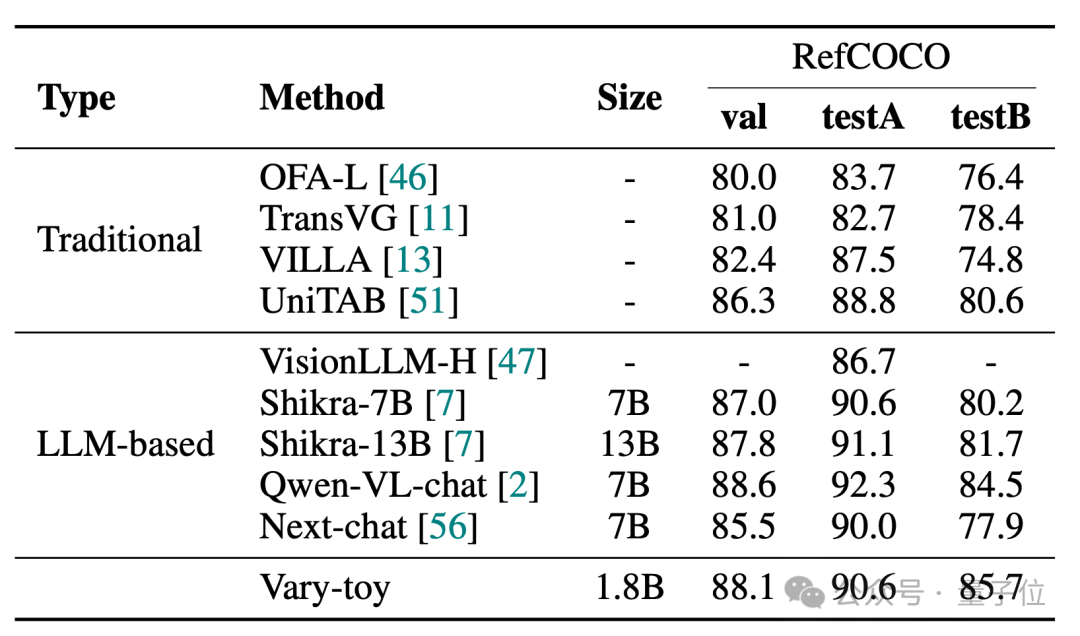
MMVet can reach 29% accuracy. Whether it is in terms of benchmark scores or visualization effects, Vary-toy, which is less than 2B, can even compete with the performance of some popular 7B models. .
Project link:
[1]https://arxiv.org/abs/2401.12503
[3] https://varytoy.github.io/
The above is the detailed content of Multi-modal large models are preferred by young people online with open source: easily run 1080Ti. For more information, please follow other related articles on the PHP Chinese website!