
Home >Technology peripherals >AI >Transformer model successfully learns the physical world using 2 billion data points in challenge video generation
Transformer model successfully learns the physical world using 2 billion data points in challenge video generation

- 王林forward
- 2024-01-29 09:09:261308browse
Building a world model that can make videos can also be realized through Transformer!
Researchers from Tsinghua University and Jiji Technology have joined forces to launch a new universal world model for video generation-WorldDreamer.
It can complete a variety of video generation tasks, including natural scenes and autonomous driving scenes, such as Vincent videos, Tu videos, video editing, action sequence videos, etc.

#According to the team, WorldDreamer is the first in the industry to build a universal scenario world model by predicting Tokens.
It converts video generation into a sequence prediction task, which can fully learn the changes and motion patterns of the physical world.
Visualization experiments have proven that WorldDreamer has a deep understanding of the dynamic changes of the general world.
So, what video tasks can it complete, and what is its effect?
Supports a variety of video tasks
Image to Video (Image to Video)
WorldDreamer can predict future frames based on a single image.
As long as the first image is input, WorldDreamer treats the remaining video frames as masked visual tokens and predicts these tokens.
As shown in the figure below, WorldDreamer has the ability to generate high-quality movie-level videos.
The resulting video exhibits seamless frame-by-frame motion, similar to the smooth camera movements in real movies.
Moreover, these videos strictly adhere to the constraints of the original image, ensuring remarkable consistency in frame composition.

Text to Video
WorldDreamer can also generate videos based on text.
Given only language text input, WorldDreamer considers all video frames to be masked visual tokens and predicts these tokens.
The figure below demonstrates WorldDreamer’s ability to generate video from text under various style paradigms.
The generated video adapts seamlessly to the input language, where the language input by the user can shape the video content, style and camera movement.

Video modification (Video Inpainting)
WorldDreamer can further implement the video inpainting task.
Specifically, given a video, the user can specify the mask area, and then the video content of the masked area can be changed according to the language input.
As shown in the figure below, WorldDreamer can replace the jellyfish with a bear, or the lizard with a monkey, and the replaced video is highly consistent with the user's language description.

Video Stylization
In addition, WorldDreamer can achieve video stylization.
As shown in the figure below, input a video segment in which certain pixels are randomly masked. WorldDreamer can change the style of the video, such as creating an autumn theme effect based on the input language.

Based on action synthesis video (Action to Video)
WorldDreamer can also generate videos from driving actions in autonomous driving scenarios.
As shown in the figure below, given the same initial frame and different driving strategies (such as left turn, right turn), WorldDreamer can generate videos that are highly consistent with the first frame constraints and driving strategies.

So, how does WorldDreamer achieve these functions?
Building a world model with Transformer
Researchers believe that the most advanced video generation methods are mainly divided into two categories-Transformer-based methods and diffusion model-based methods.
Using Transformer for token prediction can efficiently learn the dynamic information of video signals and reuse the experience of the large language model community. Therefore, the solution based on Transformer is an effective way to learn a general world model.
Methods based on diffusion models are difficult to integrate multiple modes within a single model and are difficult to expand to larger parameters, so it is difficult to learn the changes and motion laws of the general world.
The current world model research is mainly concentrated in the fields of games, robots and autonomous driving, and lacks the ability to comprehensively capture general world changes and motion laws.
Therefore, the research team proposed WorldDreamer to enhance the learning and understanding of changes and movement patterns in the general world, thereby significantly enhancing the ability to generate videos.
Drawing on the successful experience of large-scale language models, WorldDreamer adopts the Transformer architecture to convert the world model modeling framework into an unsupervised visual token prediction problem.
The specific model structure is shown in the figure below:
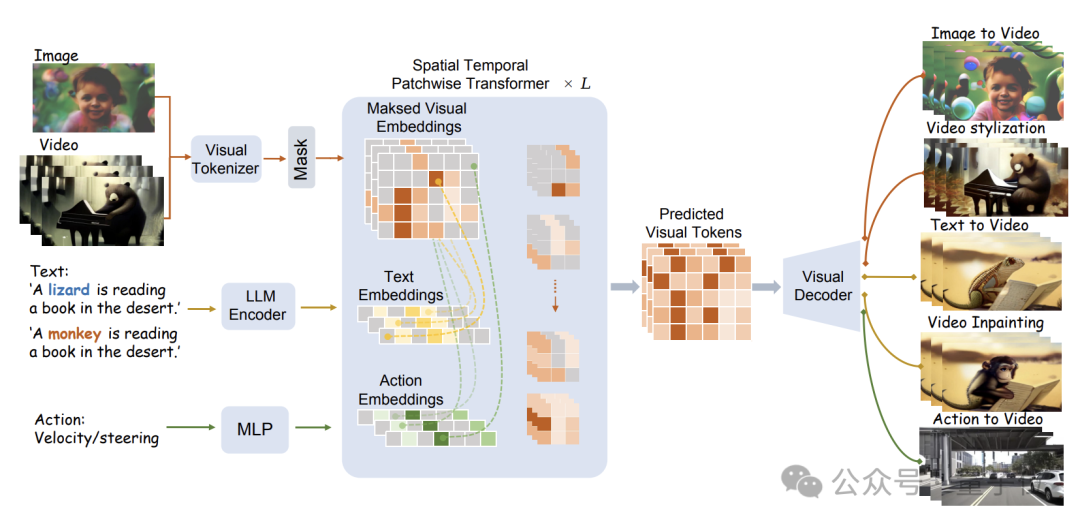
WorldDreamer first uses a visual Tokenizer to encode visual signals (images and videos) into discrete Tokens.
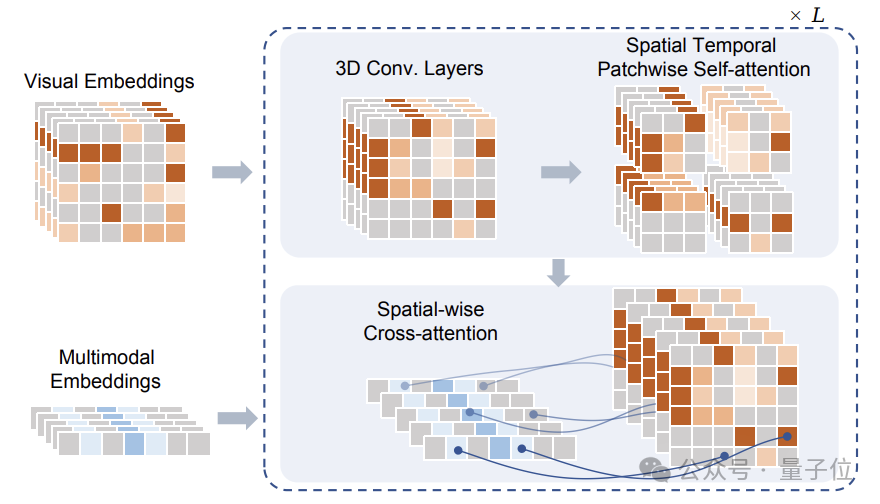
After masking, these Tokens are input to the Sptial Temporal Patchwuse Transformer (STPT) module proposed by the research team.
At the same time, text and action signals are encoded into corresponding feature vectors respectively, and are input to STPT as multi-modal features.
STPT fully interactively learns visual, language, action and other features internally, and can predict the visual token of the masked part.
Ultimately, these predicted visual tokens can be used to complete a variety of video generation and video editing tasks.
It is worth noting that when training WorldDreamer, the research team also constructed a triplet of Visual-Text-Action (visual-text-action) data. The loss function only involves predicting the masked visual token, with no additional supervision signal.
In the data triplet proposed by the team, only visual information is necessary, which means that WorldDreamer training can still be performed even without text or action data.
This mode not only reduces the difficulty of data collection, but also allows WorldDreamer to support the completion of video generation tasks without known or only a single condition.
The research team used a large amount of data to train WorldDreamer, including 2 billion cleaned image data, 10 million videos of common scenes, 500,000 high-quality language annotated videos, and nearly a thousand self-driving videos Scene video.
The team conducted millions of iterative trainings on 1 billion levels of learnable parameters. After convergence, WorldDreamer gradually understood the changes and movement patterns of the physical world, and has various video generation and video editing capabilities. .
Paper address: https://arxiv.org/abs/2401.09985
Project homepage: https://world-dreamer.github.io/
The above is the detailed content of Transformer model successfully learns the physical world using 2 billion data points in challenge video generation. For more information, please follow other related articles on the PHP Chinese website!