

 Technology peripheralsAIOK-Robot developed by Meta and New York University: tea-pouring robot has emerged
Technology peripheralsAIOK-Robot developed by Meta and New York University: tea-pouring robot has emergedOK-Robot developed by Meta and New York University: tea-pouring robot has emerged

In a family environment, family members are often asked to get the remote control on the TV cabinet. Sometimes even pet dogs are not immune. But there are always times when people are in situations where they are unable to control others. And pet dogs may not be able to understand the instructions. Human beings' expectation of robots is to help complete these chores. This is our ultimate dream for robots.
Recently, New York University and Meta collaborated to develop a robot with the ability to act autonomously. When you tell it: "Please put the cornflakes on the table on the bedside table," it will successfully complete the task by independently searching for the cornflakes and planning the best route and corresponding actions. In addition, the robot also has the ability to organize items and handle garbage to provide you with convenience.



#This robot is called OK-Robot and was built by researchers from New York University and Meta. They integrated the basic modules of visual language model, navigation and grasping into an open knowledge-based framework to provide a solution for efficient pick-and-place operations of robots. This means that when we get older, buying a robot to help us serve tea and pour water may become a reality.
OK-Robot’s “open knowledge” positioning refers to its learning model trained on large public data sets. When OK-Robot is placed in a new home environment, it fetches scan results from the iPhone. Based on these scans, it computes dense visual language representations using LangSam and CLIP and stores them in semantic memory. Then, when given a linguistic query for an object to be picked up, the linguistic representation of the query is matched against semantic memory. Next, OK-Robot will gradually apply the navigation and picking modules, move to the required object and pick it up. A similar process can be used for discarding objects.
To study OK-Robot, researchers tested it in 10 real home environments. Through experiments, they found that in an unseen natural home environment, the system's zero-sample deployment success rate averaged 58.5%. However, this success rate depends heavily on the "naturalness" of the environment. They also found that this success rate could be increased to about 82.4% by improving the query, tidying up the space, and excluding objects that were obviously adversarial (such as too large, too translucent, or too slippery).
OK-Robot attempted 171 pickup tasks in 10 home environments in New York City.
In short, through experiments, they came to the following conclusions:
- Pre-trained visual language models are very good for open vocabulary navigation Effective: Current open-vocabulary visual language models—such as CLIP or OWL-ViT—are excellent at identifying arbitrary objects in the real world and navigating and finding them in a zero-shot manner.
- Pre-trained grasping models can be directly applied to mobile manipulation: Similar to VLM, specialized robot models pre-trained on large amounts of data can be directly applied to open vocabulary grasping in the home. These robot models do not require any additional training or fine-tuning.
- How to combine components is crucial: Researchers found that when the model is pre-trained, they can be combined using a simple state-machine model , without any training. They also found that using heuristics to offset the robot's physical limitations led to higher success rates in the real world.
- There are still some challenges: Considering the huge challenge of zero-sample operation in any household, OK-Robot improved on the basis of previous work: by analyzing failure modes, They found that significant improvements can be made in visual language models, robot models, and robot morphology, which would directly improve the performance of open knowledge manipulation agents.
In order to encourage and support other researchers’ work in the field of open knowledge robotics, the author stated that he will share the code and modules of OK-Robot. More information can be found at: https://ok-robot.github.io.
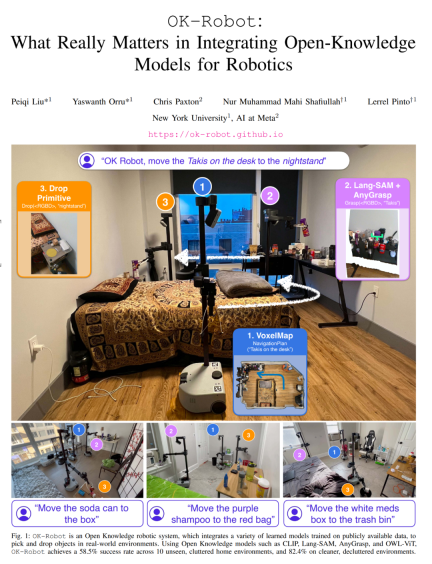
- ##Paper title: OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
- Paper link: https://arxiv.org/pdf/2401.12202.pdf
Technical composition and method
The research mainly solves this problem: pick up A from B and place it on C, where A is an object and B and C are places in the real-world environment. To achieve this, the proposed system needs to include the following modules: an open vocabulary object navigation module, an open vocabulary RGB-D grabbing module, and a heuristic module for releasing or placing objects (dropping heuristic).
Open Vocabulary Object Navigation
Start by scanning the room. Open Vocabulary Object Navigation follows the CLIP-Fields approach and assumes a pre-mapping phase of manual scanning of the home environment using an iPhone. This manual scan simply captures a home video using the Record3D app on an iPhone, which will produce a series of RGB-D images with locations.
Scanning each room takes less than a minute, and once the information is collected, the RGB-D images along with the camera pose and position are exported to the project library for map building. The recording must capture the ground surface as well as objects and containers in the environment.
The next step is object detection. On each frame scanned, an open vocabulary object detector processes the scanned content. This paper chooses the OWL-ViT object detector because this method performs better on preliminary queries. We apply the detector on each frame and extract each object bounding box, CLIP embedding, and detector confidence and pass them to the object storage module of the navigation module.
Then perform object-centric semantic storage. This paper uses VoxelMap to accomplish this step. Specifically, they use the depth image and the pose collected by the camera to back-project the object mask into real-world coordinates. This way can provide a point cloud in which each point has a Associative semantic vectors from CLIP.
Followed by the query memory module: given a language query, this article uses the CLIP language encoder to convert it into a semantic vector. Since each voxel is associated with a real location in the home, the location where the query object is most likely to be found can be found, similar to Figure 2 (a).
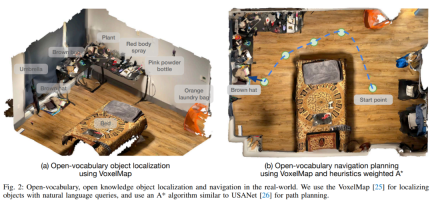
When necessary, this article implements "A on B" as "A close B". To do this, query A selects the first 10 points and query B selects the first 50 points. Then calculate the 10×50 pairwise Euclidean distance and select the point A associated with the shortest (A, B) distance.
After completing the above process, the next step is to navigate to the object in the real world: Once the 3D position coordinates in the real world are obtained, they can be used as the navigation target of the robot to initialize Operation stage. The navigation module must place the robot within arms reach so that the robot can then manipulate the target object.
Robot grasping of real-world objects
Different from open vocabulary navigation, in order to complete the grasping task, The algorithm requires physical interaction with arbitrary objects in the real world, which makes this part even more difficult. Therefore, this paper chooses to use a pre-trained grasping model to generate real-world grasping gestures and use VLM for language condition filtering.
The grasp generation module used in this article is AnyGrasp, which generates collision-free grasps using parallel jaw grippers in a scene given a single RGB image and a point cloud.
AnyGrasp provides the possible grasps in the scene (column 2 of Figure 3), including the grasp point, width, height, depth and grasp score, which represents the number of possible grasps for each grasp. Uncalibrated model confidence in hand.

Filter grasps using language queries: For grasp suggestions obtained from AnyGrasp, this article uses LangSam to filter grasps. This paper projects all proposed grip points onto the image and finds the grip points that fall within the object mask (Figure 3, column 4).
Grasp execution. Once the optimal grasp is determined (Figure 3, column 5), a simple pre-grasp method can be used to grasp the target object.
Heuristic module for releasing or placing objects
After grabbing the object, then The next step is where to place the object. Unlike HomeRobot's baseline implementation, which assumes that the location where the object is dropped is a flat surface, this paper extends it to also cover concave objects such as sinks, bins, boxes, and bags.
Now that navigation, grabbing, and placement are all there, it’s a straightforward matter of combining them, and the method can be applied directly to any new home. For new home environments, the study can scan a room in under a minute. It then takes less than five minutes to process it into a VoxelMap. Once completed, the robot can be placed immediately at the chosen site and begin operations. From arriving in a new environment to starting to operate autonomously within it, the system takes an average of less than 10 minutes to complete its first pick-and-place task.
Experiments
In more than 10 home experiments, OK-Robot achieved a 58.5% success rate on pick-and-place tasks.
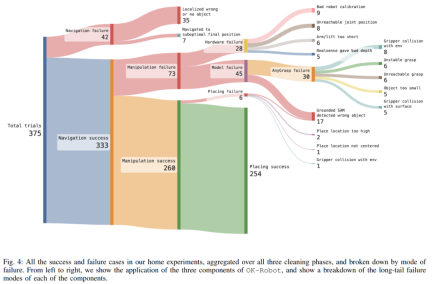
The study also conducted an in-depth exploration of OK-Robot to better understand its failure modes. The study found that the main cause of failure was operational failure. However, after careful observation, it was noticed that the cause of failure was caused by the long tail. As shown in Figure 4, the three major reasons for failure included failure to retrieve from semantic memory the location to which to navigate. of the correct object (9.3%), the pose obtained from the manipulation module is difficult to complete (8.0%), and hardware reasons (7.5%).
As can be seen from Figure 5, the VoxelMap used in OK-Robot is slightly better than other semantic memory modules. As for the scraping module, AnyGrasp significantly outperforms other scraping methods, outperforming the best candidate (top-down scraping) by almost 50% on a relative scale. However, the fact that HomeRobot's top-down crawling based on heuristics beat the open source AnyGrasp baseline and Contact-GraspNet demonstrates that building a truly universal crawling model remains difficult.
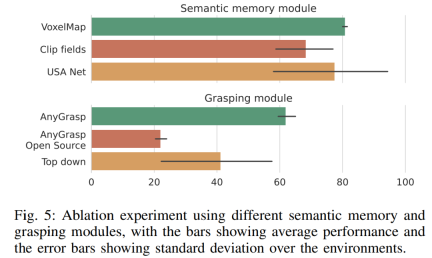
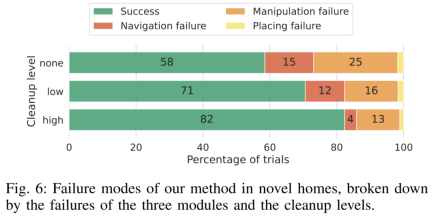
Figure 6 shows the complete analysis of OK-Robot failure at various stages. According to the analysis, when the researchers clean up the environment and delete blurry objects, the navigation accuracy increases, and the total error rate drops from 15% to 12%, and finally drops to 4%. Likewise, accuracy improved when the researchers cleared the environment of clutter, with error rates falling from 25 percent to 16 percent and finally to 13 percent.
For more information, please refer to the original paper.
The above is the detailed content of OK-Robot developed by Meta and New York University: tea-pouring robot has emerged. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

