

 Technology peripheralsAIUniVision introduces a new generation of unified framework: BEV detection and Occupancy dual tasks reach the most advanced level!
Technology peripheralsAIUniVision introduces a new generation of unified framework: BEV detection and Occupancy dual tasks reach the most advanced level!UniVision introduces a new generation of unified framework: BEV detection and Occupancy dual tasks reach the most advanced level!

Written in front&Personal understanding
In recent years, vision-centered 3D perception in autonomous driving technology has developed rapidly. Although 3D perception models are structurally and conceptually similar, there are still gaps in feature representation, data formats, and objectives, which poses a challenge to design a unified and efficient 3D perception framework. Therefore, researchers need to work hard to address these gaps to achieve more accurate and reliable autonomous driving systems. Through collaboration and innovation, we hope to further improve the safety and performance of autonomous driving.
Especially for detection tasks and Occupancy tasks under BEV, it is very difficult to achieve joint training and achieve good results. This brings great troubles to many applications due to instability and effects that are difficult to control. However, UniVision is a simple and efficient framework that unifies the two main tasks of vision-centric 3D perception, namely occupancy prediction and object detection. The core of the framework is an explicit-implicit view transformation module for complementary 2D-3D feature transformation. In addition, UniVision also proposes a local global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. By adopting these methods, UniVision is able to achieve satisfactory results in detection tasks and Occupancy tasks under BEV.
UniVision proposes a joint occupancy detection data enhancement strategy and a progressive loss weight adjustment strategy to improve the efficiency and stability of multi-task framework training. Extensive experiments are conducted on four public benchmarks, including scene-free lidar segmentation, scene-free detection, OpenOccupancy and Occ3D. Experimental results show that UniVision achieved gains of 1.5 mIoU, 1.8 NDS, 1.5 mIoU and 1.8 mIoU on each benchmark respectively, reaching the SOTA level. Therefore, the UniVision framework can serve as a high-performance baseline for unified vision-centric 3D perception tasks.
The current state of the field of 3D perception
3D perception is the primary task of autonomous driving systems, which aims to utilize a series of sensors (such as lidar, radar and cameras) The data obtained can be used to comprehensively understand the driving scene and be used for subsequent planning and decision-making. In the past, the field of 3D perception has been dominated by lidar-based models due to the precise 3D information derived from point cloud data. However, lidar-based systems are costly, susceptible to severe weather, and inconvenient to deploy. In contrast, vision-based systems have many advantages, such as low cost, easy deployment, and good scalability. Therefore, vision-centered three-dimensional perception has attracted widespread attention from researchers.
Recently, vision-based 3D detection has made significant progress through improved feature representation transformation, temporal fusion, and supervision signal design, and the gap with LiDAR-based models continues to narrow. In addition, vision-based occupancy tasks have also developed rapidly in recent years. Unlike using 3D boxes to represent objects, occupancy can describe the geometric and semantic characteristics of the driving scene more comprehensively and is not limited by object shape and category.
Although detection methods and occupancy methods share structural and conceptual similarities, there is insufficient research on handling these two tasks simultaneously and exploring their interrelationships. Occupancy models and detection models usually extract different feature representations. The occupancy prediction task requires exhaustive semantic and geometric judgments, so voxel representations are widely used to preserve fine-grained 3D information. However, in detection tasks, BEV representation is more preferable since most objects lie on the same horizontal plane with smaller overlap.
Compared with BEV representation, voxel representation is higher in fineness, but less efficient. In addition, many advanced operators are mainly designed and optimized for 2D features, making their integration with 3D voxel representation not so simple. BEV representation is more advantageous in terms of time efficiency and memory efficiency, but it is suboptimal for dense spatial prediction because structural information is lost in the height dimension. In addition to feature representation, different perception tasks also differ in data formats and goals. Therefore, ensuring the uniformity and efficiency of training multi-task 3D perception frameworks is a huge challenge.
UniVision Network Structure

The overall architecture of the UniVision framework is shown in Figure 1. The framework receives multi-view images from surrounding N cameras as input and extracts image features through an image feature extraction network. Next, the Ex-Im view transformation module is used to convert 2D image features into 3D voxel features. This module combines depth-guided explicit feature boosting and query-guided implicit feature sampling. After view transformation, the voxel features are fed into the local global feature extraction and fusion block to extract local context-aware voxel features and global context-aware BEV features respectively. Next, information is exchanged on voxel features and BEV features for different downstream perception tasks through the cross-representation feature interaction module. During the training process, the UniVision framework uses combined Occ-Det data enhancement and progressive loss weight adjustment strategies for effective training. These strategies can improve the training effect and generalization ability of the framework. In short, the UniVision framework realizes the task of sensing the surrounding environment through the processing of multi-view images and 3D voxel features, as well as the application of feature interaction modules. At the same time, through the application of data enhancement and loss weight adjustment strategies, the training effect of the framework is effectively improved.
1) Ex-Im View Transform
Depth-oriented explicit feature enhancement. The LSS approach is followed here:
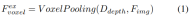
#2) Query-guided implicit feature sampling. However, there are some drawbacks in representing 3D information. The accuracy of is highly correlated with the accuracy of the estimated depth distribution. Furthermore, the points generated by LSS are not evenly distributed. Points are densely packed near the camera and sparse at distance. Therefore, we further use query-guided feature sampling to compensate for the above shortcomings.

Compared to points generated from LSS, voxel queries are uniformly distributed in 3D space, and they are learned from the statistical properties of all training samples, which is consistent with The depth prior information used in LSS is irrelevant. Therefore, and complement each other, connect them as the output features of the view transformation module:

2) Local and global feature extraction and fusion
Given input voxel features, first overlay the features on the Z-axis and use convolutional layers to reduce channels to obtain BEV features:

Then, The model is divided into two parallel branches for feature extraction and enhancement. Local feature extraction, global feature extraction, and the final cross-representation feature interaction! As shown in Figure 1(b).
3) Loss function and detection head
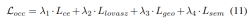
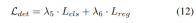

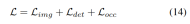
Progressive loss weight adjustment strategy. In practice, it is found that directly incorporating the above losses often causes the training process to fail and the network to fail to converge. In the early stages of training, voxel features Fvoxel are randomly distributed, and supervision in the occupancy head and detection head contributes less than other losses in convergence. At the same time, loss items such as the classification loss Lcls in the detection task are very large and dominate the training process, making it difficult to optimize the model. To overcome this problem, a progressive loss weight adjustment strategy is proposed to dynamically adjust the loss weight. Specifically, the control parameter δ is added to the non-image-level losses (i.e., occupancy loss and detection loss) to adjust the loss weight in different training epochs. The control weight δ is set to a small value Vmin at the beginning and gradually increases to Vmax over N training epochs:

4) Combined with Occ-Det spatial data enhancement
In 3D detection tasks, in addition to common image-level data enhancement, spatial-level data enhancement is also effective in improving model performance. Effective. However, applying spatial level enhancement in occupancy tasks is not straightforward. When we apply data augmentation (such as random scaling and rotation) to discrete occupancy labels, it is difficult to determine the resulting voxel semantics. Therefore, existing methods only apply simple spatial augmentation such as random flipping in occupancy tasks.
To solve this problem, UniVision proposes a joint Occ-Det spatial data enhancement to allow simultaneous enhancement of 3D detection tasks and occupancy tasks in the framework. Since the 3D box labels are continuous values and the enhanced 3D box can be directly calculated for training, the enhancement method in BEVDet is followed for detection. Although occupancy labels are discrete and difficult to manipulate, voxel features can be treated as continuous and can be processed through operations such as sampling and interpolation. It is therefore recommended to transform voxel features instead of directly operating on occupancy labels for data augmentation.
Specifically, spatial data augmentation is first sampled and the corresponding 3D transformation matrix is calculated. For the occupancy labels and their voxel indices , we calculate their three-dimensional coordinates. Then, apply and normalize it to obtain the voxel indices in the enhanced voxel feature :

Experiment Comparison of results
Used multiple data sets for verification, NuScenes LiDAR Segmentation, NuScenes 3D Object Detection, OpenOccupancy and Occ3D.
NuScenes LiDAR Segmentation: According to the recent OccFormer and TPVFormer, camera images are used as input for the lidar segmentation task, and the lidar data is only used to provide 3D locations for querying the output features. Use mIoU as the evaluation metric.
NuScenes 3D Object Detection: For detection tasks, use the official metric of nuScenes, the nuScene Detection Score (NDS), which is the weighted sum of average mAP and several metrics, including average translation error (ATE), average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE) and Average Attribute Error (AAE).
OpenOccupancy: The OpenOccupancy benchmark is based on the nuScenes dataset and provides semantic occupancy labels at 512×512×40 resolution. The labeled classes are the same as those in the lidar segmentation task, using mIoU as the evaluation metric!
Occ3D: The Occ3D benchmark is based on the nuScenes dataset and provides semantic occupancy labels at 200×200×16 resolution. Occ3D further provides visible masks for training and evaluation. The labeled classes are the same as those in the lidar segmentation task, using mIoU as the evaluation metric!
1) Nuscenes LiDAR segmentation
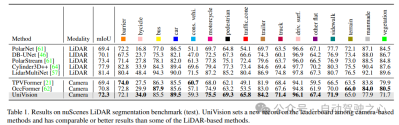
Table 1 shows the results of the nuScenes LiDAR segmentation benchmark. UniVision significantly outperforms the state-of-the-art vision-based method OccFormer by 1.5% mIoU and sets a new record for vision-based models on the leaderboard. Notably, UniVision also outperforms some lidar-based models such as PolarNe and DB-UNet.
2) NuScenes 3D object detection task
As shown in Table 2, when using the same training settings for fair comparison , UniVision was shown to outperform other methods. Compared with BEVDepth at 512×1408 image resolution, UniVision achieves gains of 2.4% and 1.1% in mAP and NDS respectively. When the model is scaled up and UniVision is combined with temporal input, it further outperforms SOTA-based temporal detectors by significant margins. UniVision achieves this with a smaller input resolution, and it does not use CBGS.

3) Comparison of OpenOccupancy results
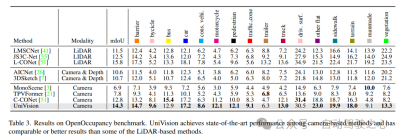
The results of the OpenOccupancy benchmark test are shown in Table 3. UniVision significantly outperforms recent vision-based occupancy methods including MonoScene, TPVFormer, and C-CONet in terms of mIoU by 7.3%, 6.5%, and 1.5%, respectively. Furthermore, UniVision outperforms some lidar-based methods such as LMSCNet and JS3C-Net.
4) Occ3D experimental results
Table 4 lists the results of the Occ3D benchmark test. UniVision significantly outperforms recent vision-based methods in terms of mIoU under different input image resolutions, by more than 2.7% and 1.8% respectively. It is worth noting that BEVFormer and BEVDet-stereo load pre-trained weights and use temporal inputs in inference, while UniVision does not use them but still achieves better performance.

#5) Effectiveness of components in detection tasks
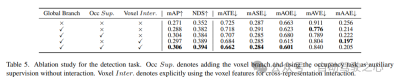
Ablation studies for detection tasks are shown in Table 5. When the BEV-based global feature extraction branch is inserted into the baseline model, the performance improves by 1.7% mAP and 3.0% NDS. When the voxel-based occupancy task is added to the detector as an auxiliary task, the model’s mAP gain increases by 1.6%. When cross-representation interactions are explicitly introduced from voxel features, the model achieves the best performance, improving mAP and NDS by 3.5% and 4.2%, respectively, compared to the baseline;
6) Effectiveness of components in the occupancy task
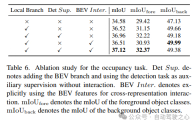
Ablation studies for the occupancy task are shown in Table 6. The voxel-based local feature extraction network brings an improvement of 1.96% mIoU gain to the baseline model. When the detection task is introduced as an auxiliary supervision signal, the model performance improves by 0.4% mIoU.
7) Others
Table 5 and Table 6 show that in the UniVision framework, detection tasks and occupancy tasks complement each other of. For detection tasks, occupancy supervision can improve mAP and mATE metrics, indicating that voxel semantic learning effectively improves the detector's perception of object geometry, i.e., centrality and scale. For the occupancy task, detection supervision significantly improves the performance of the foreground category (i.e., the detection category), resulting in an overall improvement.

The effectiveness of the combined Occ-Det spatial enhancement, Ex-Im view conversion module and progressive loss weight adjustment strategy is shown in Table 7. With the proposed spatial augmentation and the proposed view transformation module, it shows significant improvements in detection tasks and occupancy tasks on mIoU, mAP and NDS metrics. The loss weight adjustment strategy can effectively train the multi-task framework. Without this, the training of the unified framework cannot converge and the performance is very low.
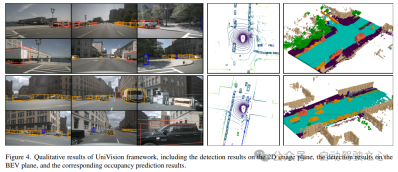
Original link: https://mp.weixin.qq.com/s/8jpS_I-wn1-svR3UlCF7KQ
The above is the detailed content of UniVision introduces a new generation of unified framework: BEV detection and Occupancy dual tasks reach the most advanced level!. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

