
Home >Technology peripherals >AI >Ant Group releases new algorithm that can speed up large model inference by 2-6 times
Ant Group releases new algorithm that can speed up large model inference by 2-6 times

- 王林forward
- 2024-01-17 21:33:05841browse
Recently, Ant Group has open sourced a set of new algorithms that can help large models speed up inference by 2 to 6 times, attracting attention in the industry.
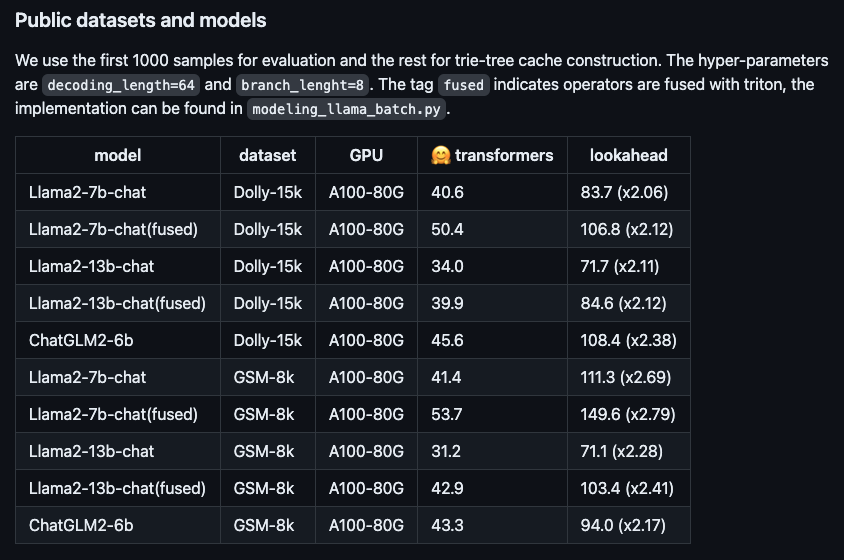
#Figure: The speed-up performance of the new algorithm on different open source large models.
This new algorithm is called Lookahead Inference Acceleration Framework, which can achieve lossless effects and is plug-and-play. This algorithm has been implemented in a large number of ant scenes, significantly reducing the Reduce reasoning time.
Taking the Llama2-7B-chat model and the Dolly data set as examples, we conducted actual measurements and found that the token generation speed increased from 48.2/second to 112.9/second, which is a 2.34 times increase. On Ant's internal RAG (Retrieval Enhanced Generation) data set, the acceleration ratio of the 10B version of the Bailing large model AntGLM reached 5.36. At the same time, the increase in video memory and memory consumption are almost negligible.
Current large-scale models are usually based on autoregressive decoding and only generate one token at a time. This method not only wastes the parallel processing power of the GPU, but also results in excessive user experience delays, affecting smoothness. In order to improve this problem, you can try to use parallel decoding to generate multiple tokens at the same time to improve efficiency and user experience.
For example, the original token generation process can be compared to the early Chinese input method. Users need to tap the keyboard word by word to enter text. However, after adopting Ant's acceleration algorithm, the token generation process is like the modern Lenovo input method, and the entire sentence can be directly popped up through the Lenovo function. Such improvements greatly improve input speed and efficiency.
Some optimization algorithms have emerged in the industry before, mainly focusing on methods of generating better quality drafts (that is, guessing and generating token sequences). However, it has been proven in practice that once the length of the draft exceeds 30 tokens, the efficiency of end-to-end reasoning cannot be further improved. Obviously, this length does not fully utilize the computing power of the GPU.
In order to further improve hardware performance, the Ant Lookahead inference acceleration algorithm adopts a multi-branch strategy. This means that the draft sequence no longer has just one branch, but contains multiple parallel branches that can be verified simultaneously. In this way, the number of tokens generated by a forward process can be increased while keeping the time consumption of the forward process basically unchanged.
The Ant Lookahead inference acceleration algorithm further improves computing efficiency by using trie trees to store and retrieve token sequences, and merging the same parent nodes in multiple drafts. In order to improve the ease of use, the trie tree construction of this algorithm does not rely on additional draft models, but only uses prompts and generated answers during the reasoning process for dynamic construction, thereby reducing the user's access cost.
The algorithm is now open source on GitHub (https://www.php.cn/link/51200d29d1fc15f5a71c1dab4bb54f7c), and related papers are published in ARXIV (https://www .php.cn/link/24a29a235c0678859695b10896513b3d).
Public information shows that Ant Group has continued to invest in artificial intelligence based on the needs of rich business scenarios, and has laid out technical fields including large models, knowledge graphs, operations optimization, graph learning, and trusted AI.
The above is the detailed content of Ant Group releases new algorithm that can speed up large model inference by 2-6 times. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Where is the address of the World VR Industry Conference?
- Artificial intelligence injects new momentum into my country's pharmaceutical industry
- The scale of my country's computing industry reaches 2.6 trillion yuan, with more than 20.91 million general-purpose servers and 820,000 AI servers shipped in the past six years.
- Xuhui District CPPCC members organized intensive inspection activities and paid attention to the development of the artificial intelligence industry
- 360 Group won the 'China Data Intelligence Industry AI Large Model Pioneer Enterprise' award based on 360 Intelligent Brain