

 Technology peripheralsAIThe potential of open source VLMs is unleashed by the RoboFlamingo framework
Technology peripheralsAIThe potential of open source VLMs is unleashed by the RoboFlamingo framework
In recent years, research on large models has been accelerating, and it has gradually demonstrated multi-modal understanding and temporal and spatial reasoning capabilities in various tasks. Various embodied operation tasks of robots naturally have high requirements for language command understanding, scene perception, and spatio-temporal planning. This naturally leads to a question: Can the capabilities of large models be fully utilized and migrated to the field of robotics? What about directly planning the underlying action sequence?
ByteDance Research uses the open source multi-modal language vision large model OpenFlamingo to develop an easy-to-use RoboFlamingo robot operation model that requires only stand-alone training. VLM can be turned into Robotics VLM through simple fine-tuning, which is suitable for language interaction robot operation tasks.
Verified by OpenFlamingo on the robot operation data set CALVIN. Experimental results show that RoboFlamingo uses only 1% of the data with language annotation and achieves SOTA performance in a series of robot operation tasks. With the opening of the RT-X data set, RoboFlamingo, which is pre-trained on open source data, and fine-tuned for different robot platforms, is expected to become a simple and effective large-scale robot model process. The paper also tested the fine-tuning performance of VLM with different strategy heads, different training paradigms and different Flamingo structures on robot tasks, and came to some interesting conclusions.

- ## Project homepage: https://roboflamingo.github.io
- Code address: https://github.com/RoboFlamingo/RoboFlamingo
- Paper address: https://arxiv.org/ abs/2311.01378
Research background
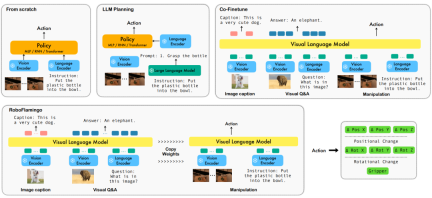
Language-based robot operation is an important application in the field of embodied intelligence, involving the understanding and processing of multi-modal data, including vision, language and control. In recent years, visual language-based models (VLMs) have made significant progress in areas such as image description, visual question answering, and image generation. However, applying these models to robot operations still faces challenges, such as how to integrate visual and language information and how to handle the temporal sequence of robot operations. Solving these challenges requires improvements in multiple aspects, such as improving the multi-modal representation capabilities of the model, designing a more effective model fusion mechanism, and introducing model structures and algorithms that adapt to the sequential nature of robot operations. Additionally, there is a need to develop richer robotics datasets to train and evaluate these models. Through continuous research and innovation, language-based robot operations are expected to play a greater role in practical applications and provide more intelligent and convenient services to humans.
In order to solve these problems, ByteDance Research's robotics research team fine-tuned the existing open source VLM (Visual Language Model) - OpenFlamingo, and designed a new visual language Operational framework, called RoboFlamingo. The characteristic of this framework is that it uses VLM to achieve single-step visual language understanding and processes historical information through an additional policy head module. Through simple fine-tuning methods, RoboFlamingo can be adapted to language-based robot operation tasks. The introduction of this framework is expected to solve a series of problems existing in current robot operations.
RoboFlamingo was verified on the language-based robot operation data set CALVIN. The experimental results show that RoboFlamingo only utilizes 1% of the language-annotated data, that is, in a series of robot operation tasks The performance of SOTA has been achieved (the task sequence success rate of multi-task learning is 66%, the average number of task completions is 4.09, the baseline method is 38%, the average number of task completions is 3.06; the success rate of the zero-shot task is 24%, The average number of task completions is 2.48 (the baseline method is 1%, the average number of task completions is 0.67), and it can achieve real-time response through open-loop control and can be flexibly deployed on lower-performance platforms. These results demonstrate that RoboFlamingo is an effective robot manipulation method and can provide a useful reference for future robotic applications.
method
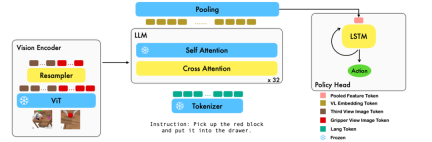
This work uses the existing visual language basic model based on image-text pairs to generate the relative actions of each step of the robot through training in an end-to-end manner. The model consists of three main modules: Vision encoder, Feature fusion decoder and Policy head. In the Vision encoder module, the current visual observation is first input into ViT, and then the token output by ViT is down sampled through the resampler. This step helps reduce the input dimension of the model, thereby improving training efficiency. The Feature fusion decoder module takes text tokens as input and uses the output of the visual encoder as a query through a cross-attention mechanism, achieving the fusion of visual and language features. In each layer, the feature fusion decoder first performs the cross-attention operation and then performs the self-attention operation. These operations help extract correlations between language and visual features to better generate robot actions. Based on the current and historical token sequences output by the Feature fusion decoder, the Policy head directly outputs the current 7 DoF relative actions, including the 6-dim robot arm end pose and the 1-dim gripper open/close. Finally, perform max pooling on the feature fusion decoder and send it to the Policy head to generate relative actions. In this way, our model is able to effectively fuse visual and linguistic information together to generate accurate robot movements. This has broad application prospects in fields such as robot control and autonomous navigation.
During the training process, RoboFlamingo utilizes the pre-trained ViT, LLM and Cross Attention parameters and only fine-tunes the parameters of resampler, cross attention and policy head.
Experimental results
Data set:

CALVIN (Composing Actions from Language and Vision) is an open source simulation benchmark for learning language-based long-horizon operation tasks. Compared with existing visual-linguistic task datasets, CALVIN's tasks are more complex in terms of sequence length, action space, and language, and support flexible specification of sensor inputs. CALVIN is divided into four splits ABCD, each split corresponds to a different context and layout.
Quantitative analysis:
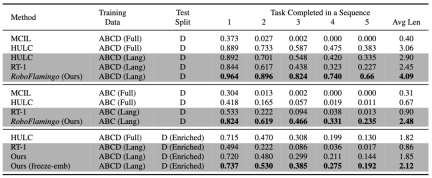
RoboFlamingo has the best performance in every setting and indicator. It shows that it has strong imitation ability, visual generalization ability and language generalization ability. Full and Lang indicate whether the model was trained using unpaired visual data (i.e. visual data without language pairing); Freeze-emb refers to freezing the embedding layer of the fused decoder; Enriched indicates using GPT-4 enhanced instructions.
Ablation experiment:
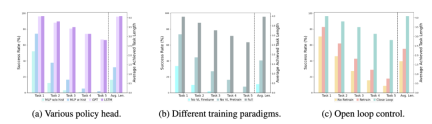
##Different policy heads:
The experiment examined four different policy heads: MLP w/o hist, MLP w hist, GPT and LSTM. Among them, MLP w/o hist directly predicts history based on current observations, and its performance is the worst. MLP w hist fuses historical observations at the vision encoder end and predicts actions, and the performance is improved; GPT and LSTM are explicitly stated at the policy head. , implicitly maintains historical information, and its performance is the best, which illustrates the effectiveness of historical information fusion through policy head.
The impact of visual-language pre-training:
Pre-training plays a key role in improving the performance of RoboFlamingo. Experiments show that RoboFlamingo performs better on robotic tasks by pre-training on a large visual-linguistic dataset.
Model size and performance:
While generally larger models lead to better performance, experimental results show that even Smaller models can also compete with larger models on some tasks.
The impact of instruction fine-tuning:
Instruction fine-tuning is a powerful technique, and experimental results show that it can further improve the performance of the model.
Qualitative results
Compared with the baseline method, RoboFlamingo not only completely executed 5 consecutive subtasks, but also successfully executed the first two subtasks on the baseline page. RoboFlamingo also takes significantly fewer steps.

Summary
This work provides a novel reality-based robot operation strategy for language interaction. There are open source VLMs frameworks that can achieve excellent results with simple fine-tuning. RoboFlamingo provides robotics researchers with a powerful open source framework that can more easily realize the potential of open source VLMs. The rich experimental results in the work may provide valuable experience and data for the practical application of robotics and contribute to future research and technology development.
The above is the detailed content of The potential of open source VLMs is unleashed by the RoboFlamingo framework. For more information, please follow other related articles on the PHP Chinese website!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。
 强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM
强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM引入密集强化学习,用 AI 验证 AI。 自动驾驶汽车 (AV) 技术的快速发展,使得我们正处于交通革命的风口浪尖,其规模是自一个世纪前汽车问世以来从未见过的。自动驾驶技术具有显着提高交通安全性、机动性和可持续性的潜力,因此引起了工业界、政府机构、专业组织和学术机构的共同关注。过去 20 年里,自动驾驶汽车的发展取得了长足的进步,尤其是随着深度学习的出现更是如此。到 2015 年,开始有公司宣布他们将在 2020 之前量产 AV。不过到目前为止,并且没有 level 4 级别的 AV 可以在市场


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SublimeText3 Mac version
God-level code editing software (SublimeText3)

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

