
Home >System Tutorial >LINUX >A problem that has troubled me for half a year
A problem that has troubled me for half a year

- PHPzforward
- 2024-01-16 23:33:181551browse
This article will introduce a difficult fault in the virtualization environment that has troubled the author for nearly half a year. The cause of the fault and the repair method that were finally identified are also ridiculous. Not because this process is complicated, but to share a psychological process, thinking about how to balance business and technology when encountering failures, and how to use search engines correctly.
Fault phenomenonWe have a high-performance proxy cluster that ran stably during the internal testing phase. However, less than half a month after it was officially launched, the hosts that provide proxy services suddenly crashed one after another, causing all services on the hosts to be interrupted.
Fault AnalysisWhen a fault occurs, the host crashes directly, unable to log in remotely, and the computer room responds to on-site keyboard typing. Since the host syslog has been connected to ELK, we collected various syslogs before and after the crash.
Error logBy checking the syslog of the crashed host, we found that the following kernel error was reported before the machine crashed:
Nov 12 15:06:31 hello-worldkernel: [6373724.634681] BUG: unable to handle kernel NULL pointer dereferenceat 0000000000000078 Nov 12 15:06:31 hello-world kernel: [6373724.634718] IP: []pick_next_task_fair+0x6b8/0x820 Nov 12 15:06:31 hello-world kernel: [6373724.634749] PGD 10561e4067 PUDffdb46067 PMD 0 Nov 12 15:06:31 hello-world kernel: [6373724.634780] Oops: 0000 [#1] SMP
It shows that accessing the kernel null pointer triggers a system bug, then causes a series of call stack errors, and finally crashes.
In order to further analyze the fault phenomenon, we first need to understand the architecture of this high-performance proxy cluster.
Architecture Introduction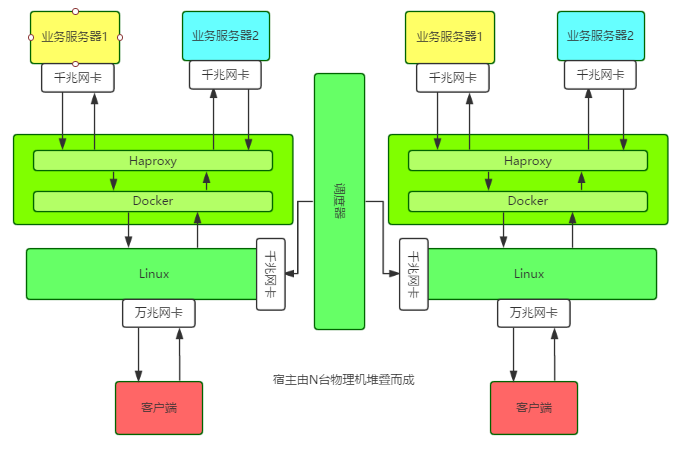
A single node runs a Docker container on a host with a 10G network card, and then runs a Haproxy instance in the container. The configuration information and business information of each node and instance are hosted on the scheduler.
The special thing is that the host uses Linux Bridge to directly configure the IP address for the Docker container. All external service IPs, including the host's own external network IP, are tied to the Linux Bridge.
Application introductionThe operating system, hardware, and Docker version of each host are all consistent. The operating system and Docker version are as follows:
[操作系统] System : Linux Kernel : 3.16.0-4-amd64 Version : 8.5 Arch : x86_64 [Docker版本] Docker version 1.12.1, build 6b644ecinitial analysis
The host configuration of this cluster is consistent, and the fault symptoms are also consistent. There are three doubts:
1. The Docker version is incompatible with the host kernel versionThe environments of the three hosts were originally the same, but one host ran the service stably and crashed after 2 months, one host ran the service and crashed after one month, and the other host ran the service online and crashed within a week.
It was found that in addition to the abnormal log of crash, each host also has the same error log:
time=”2016-09-07T20:22:19.450573015+08:00″level=warning msg=”Your kernel does not support cgroup memory limit” time=”2016-09-07T20:22:19.450618295+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs period” time=”2016-09-07T20:22:19.450640785+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs quotas” time=”2016-09-07T20:22:19.450769672+08:00″ level=warningmsg=”mountpoint for pids not found”
According to the above tips, it should be caused by the operating system kernel version not supporting certain functions for this version of Docker. However, searching on a search engine does not affect the functionality of Docker, nor does it affect system stability.
for example:
time=”2017-01-19T18:16:30+08:00″level=error msg=”containerd: notify OOM events” error=”openmemory.oom_control: no such file or directory” time=”2017-01-19T18:22:41.368392532+08:00″level=error msg=”Handler for POST /v1.23/containers/338016c68da6/stopreturned error: No such container: 338016c68da6″
is a problem that has existed since Docker 1.9 and has been fixed in 1.12.3.
For example, someone on Github replied:
“I have been update my docker from 1.11.2 to 1.12.3, This issue is fixed. BTW, this error message can be ignored, it should really just be a warning.”
But what is mentioned here are only the problems that can be fixed by version v1.12.2. After we upgraded the Docker version, we found that the crash was still the same.
So, we then confirmed many problems with the same fault phenomenon as ours through various Googles, and initially confirmed the correlation between the fault and Docker. Based on the official issue, we also initially confirmed that the Docker version is incompatible with the system kernel version and can cause downtime. The correlation; then, through the official changelog and issue, we confirmed that the Docker version used by the host is incompatible with the system kernel version. Out of a trial mentality, we upgraded the Docker version to 1.12.2, but the crash still occurred without any accidents.
2. Using Linux bridge to modify the host network card may trigger bugsI found a host that would crash after running the service for a week, stopped running Docker, and only modified the network. It ran stably for a week and no abnormalities were found.
3. Using pipework to configure IP for Docker containers may trigger bugsSince we used the open source pipework script when assigning IP to the container, we suspected that there was a bug in the working principle of pipework, so we tried not to use pipework to assign IP addresses, but found that the host still crashed.
So the initial troubleshooting was in trouble. It was very frustrating to see the host crash at least once a month.
故障定位因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
原因:从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri “unable to handle kernel NULL pointer dereference” * arch/tile/mm/fault.c:530: pr_alert(“Unable to handlekernel NULL pointer dereference/n”); arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT “Unable to handle kernel NULL pointerdereference in mna handler”); arch/sparc/mm/fault_32.c:44: “Unable to handle kernel NULL pointer dereference/n”); arch/m68k/mm/fault.c:47: pr_alert(“Unable tohandle kernel NULL pointer dereference”); arch/ia64/mm/fault.c:292: printk(KERN_ALERT “Unable tohandle kernel NULL pointer dereference (address %016lx)/n”, address); debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
故障处理下面是整个故障处理过程中,我们进行的一些操作。
升级操作系统内核对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
/proxy/bin#ls /var/lib/dpkg/info/docker-engine. docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm docker-engine.list docker-engine.postinst docker-engine.preinst #Getthe latest Docker package. $curl -fsSL https://get.docker.com/ | sh #启动 nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
apt-get install docker-engine
然后在早些时候,还有使用下面的安装方式:
apt-get install lxc-docker
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
验证16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15 docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
总结这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质运维要具有预见性、长期规划,而不能仅仅满足于眼前:
- Emergency plan: Summarize the types of failures that may occur after the system goes online, and provide an emergency plan.
- Getting through the service: Give priority to getting through the service, and then handle the fault.
- Technical selection issues such as application version selection: Special attention needs to be paid to various versions when deploying the environment and selecting applications. It is best to use versions that are common in the community or have been tested or verified to be feasible by other students in the company.
- Operating system kernel: To upgrade the kernel reasonably, only by locating the problems in the specific version can the kernel version be upgraded in a targeted manner, otherwise everything will be in vain.
- In our original design, different user schedulers did not have a locking mechanism for simultaneous operations on the same container, nor did they follow the source judgment principle. Migration failures have also occurred. During migration, it is judged whether the destination address to be migrated is the local address. If it is a local address, the operation should be rejected. I wonder if this question sounds familiar to you. I have found that many people often fail to judge the input source or the source status of the operation during program development, resulting in various bugs.
In the process of dealing with this fault, you will find that different people search for different things using Google. Why? I think this is where search engines are full of flaws, or flexible. For this fault, I used Linux Docker Unable to handle kernel NULL pointer dereference to search, but the results were different from others using "Unable to handle kernel NULL pointer dereference". The reason is that after adding "", the search becomes more precise. About the correct way to open Google.
The above is the detailed content of A problem that has troubled me for half a year. For more information, please follow other related articles on the PHP Chinese website!