

 Technology peripheralsAIAI is not learned! New research reveals ways to decipher the black box of artificial intelligence
Technology peripheralsAIAI is not learned! New research reveals ways to decipher the black box of artificial intelligenceAI is not learned! New research reveals ways to decipher the black box of artificial intelligence

Artificial Intelligence (AI) has been developing rapidly, but to humans, powerful models are a "black box."
We don’t understand the inner workings of the model and the process by which it reaches its conclusions.
However, recently, Professor Jürgen Bajorath, a chemical informatics expert at the University of Bonn, and his team have made a major breakthrough.
They have designed a technique that reveals how some artificial intelligence systems used in drug research operate.
Research shows that artificial intelligence models predict drug effectiveness primarily by recalling existing data, rather than learning specific chemical interactions.
——In other words, AI predictions are purely based on piecing together memories, and machine learning does not actually learn!
Their research results were recently published in the journal Nature Machine Intelligence.

Paper address: https://www.nature.com/articles/s42256-023-00756-9
In the field of medicine, researchers are feverishly searching for effective active substances to fight disease - which drug molecules are the most effective?
Typically, these effective molecules (compounds) are docked to proteins, which act as enzymes or receptors that trigger specific physiological chains of action.
In special cases, certain molecules are also responsible for blocking adverse reactions in the body, such as excessive inflammatory responses.
The number of possible compounds is huge, and finding the one that works is like looking for a needle in a haystack.
So the researchers first used AI models to predict which molecules would best dock and bind strongly to their respective target proteins. These drug candidates are then further screened in more detail in experimental studies.
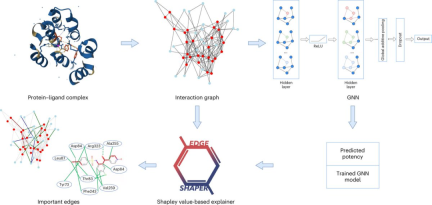
Since the development of artificial intelligence, drug discovery research has increasingly adopted AI-related technologies.
For example, graph neural network (GNN) is suitable for predicting the strength of binding of a certain molecule to a target protein.
A graph consists of nodes representing objects and edges representing relationships between nodes. In the graph representation of a protein-ligand complex, the edges of the graph connect protein or ligand nodes, representing the structure of a substance, or the interaction between a protein and a ligand.
GNN models use protein-ligand interaction maps extracted from X-ray structures to predict ligand affinities.
Professor Jürgen Bajorath said that the GNN model is like a black box to us, and we have no way of knowing how it derives its predictions.

Professor Jürgen Bajorath works at the LIMES Institute of the University of Bonn and the Bonn-Aachen International Center for Information Technology (Bonn-Aachen International Center for Information Technology) and the Lamarr Institute for Machine Learning and Artificial Intelligence.
How does artificial intelligence work?
Researchers from the Chemical Informatics Department of the University of Bonn, together with colleagues from the Sapienza University of Rome, analyzed in detail whether graph neural networks really learn the interactions between proteins and ligands. effect.
The researchers analyzed a total of six different GNN architectures using their specially developed "EdgeSHAPer" method.
The EdgeSHAPer program can determine whether the GNN has learned the most important interactions between compounds and proteins, or made predictions through other means.
The scientists trained six GNNs using graphs extracted from the structures of protein-ligand complexes - where the compound's mode of action and the strength of its binding to the target protein are known.
Then, test the trained GNN on other compounds and use EdgeSHAPer to analyze how the GNN produces predictions.
“If GNNs behave as expected, they need to learn the interactions between compounds and target proteins and make predictions by prioritizing specific interactions.”
However, according to the research team’s analysis, the six GNNs basically failed to do this. Most GNNs only learn some protein-drug interactions, focusing mainly on ligands.
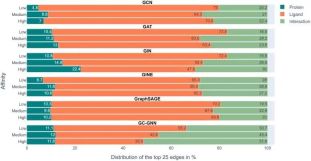
The above figure shows the experimental results in 6 GNNs. The color-coded bars represent the top 25 edges of each prediction determined with EdgeSHAPer. The average proportion of proteins, ligands, and interactions in .
We can see that the interaction represented by green should be what the model needs to learn, but the proportion in the entire experiment is not high, while the orange color representing the ligand Articles account for the largest proportion.
To predict the binding strength of a molecule to a target protein, models primarily "remember" the chemically similar molecules they encountered during training and their binding data, regardless of the target protein. . These remembered chemical similarities essentially determine the prediction.
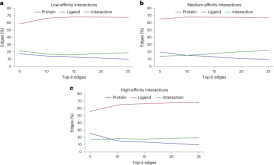
This is reminiscent of the "Clever Hans effect" - just like the horse that looks like it can count Horses, in effect, infer expected outcomes based on subtle differences in their companions' facial expressions and gestures.
This may mean that the so-called "learning ability" of GNN may be untenable, and the model's predictions are largely overestimated because chemical knowledge can be used Make predictions of the same quality as simpler methods.
However, another phenomenon was also found in the study: as the potency of the test compound increases, the model tends to learn more interactions.
Perhaps by modifying the representation and training techniques, these GNNs can be further improved in the desired direction. However, the assumption that physical quantities can be learned from molecular graphs should generally be treated with caution.
「Artificial intelligence is not black magic.」
The above is the detailed content of AI is not learned! New research reveals ways to decipher the black box of artificial intelligence. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Chinese version
Chinese version, very easy to use

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

