
Home >Technology peripherals >AI >Google releases BIG-Bench Mistake dataset to help AI language models improve self-correction capabilities
Google releases BIG-Bench Mistake dataset to help AI language models improve self-correction capabilities

- 王林forward
- 2024-01-16 16:39:131397browse

Google Research used its own BIG-Bench benchmark to establish the "BIG-Bench Mistake" data set and evaluate the error probability and error correction capabilities of popular language models on the market. Research. This initiative aims to improve the quality and accuracy of language models and provide better support for applications in the fields of intelligent search and natural language processing.
Google researchers said they created a special dataset called "BIG-Bench Mistake" to evaluate the error probability and self-correction of large language models ability. The purpose of this dataset is to fill the gap in the past lack of datasets to assess these capabilities.
The researchers ran 5 tasks on the BIG-Bench benchmark using the PaLM language model. Subsequently, they modified the generated "Chain-of-Thought" trajectory, added a "logical error" part, and used the model again to determine errors in the chain-of-thought trajectory.
In order to improve the accuracy of the data set, Google researchers repeated the above process and formed a dedicated benchmark data set called "BIG-Bench Mistake", which contained 255 logical errors.
The researchers pointed out that the logical errors in the "BIG-Bench Mistake" data set are very obvious, so it can be used as a good testing standard to help the language model start practicing from simple logical errors and gradually improve the ability to identify errors. ability.
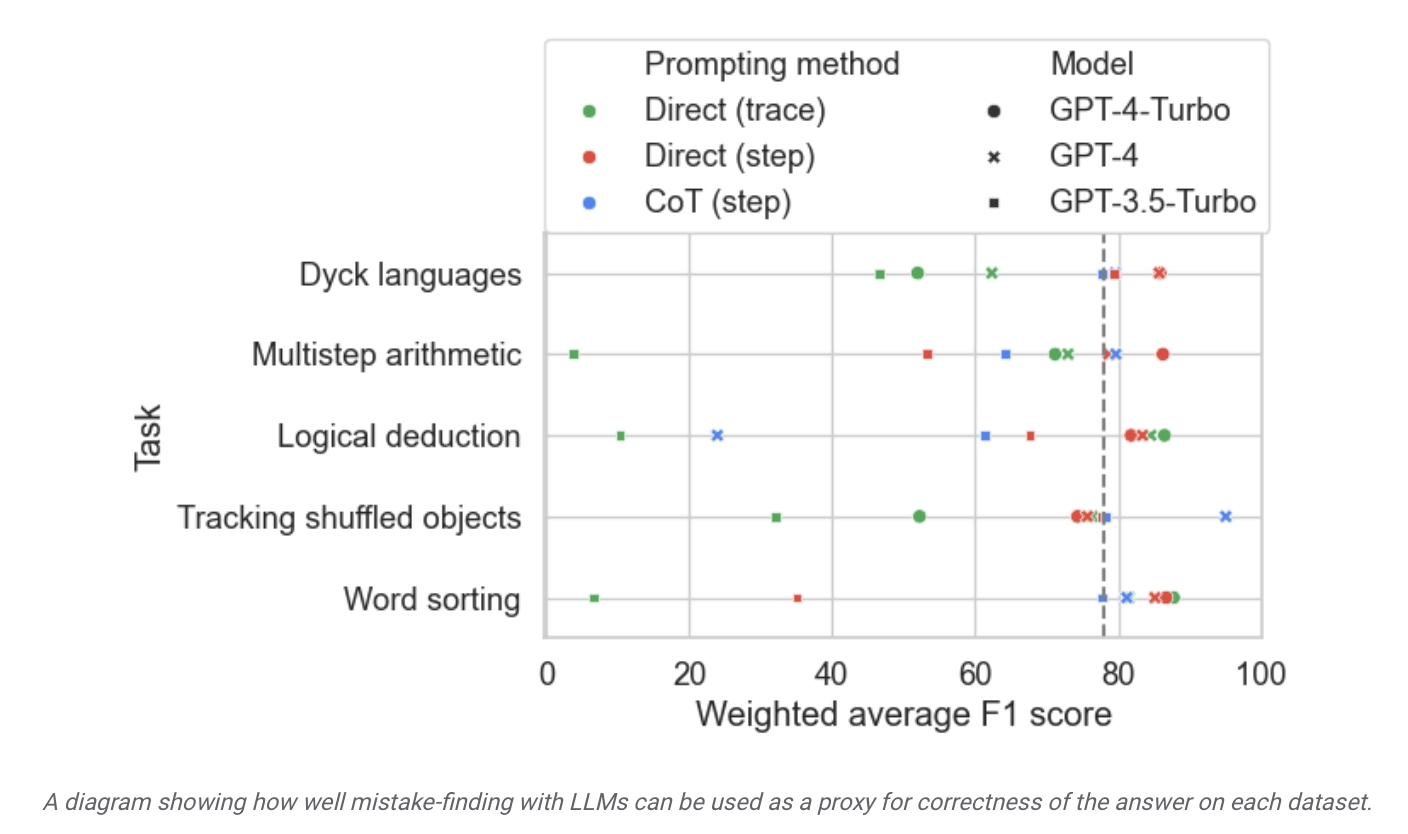
The researchers used this data set to test models on the market and found that although the vast majority of language models can identify logical errors that occur during the reasoning process and correct themselves, this process "is not sufficient." Ideal" , often requiring human intervention to correct what the model outputs.
.
 Google researchers also claimed that this BIG-Bench Mistake data set will help improve the model’s self-correction ability. After fine-tuning the model on relevant test tasks, “even Small models also generally perform better than large models with zero-sample cues."
Google researchers also claimed that this BIG-Bench Mistake data set will help improve the model’s self-correction ability. After fine-tuning the model on relevant test tasks, “even Small models also generally perform better than large models with zero-sample cues."
Accordingly, Google believes that in terms of model error correction, proprietary small models can be used to "supervise" large models. Instead of letting large language models learn to "correct self-errors",
deployment is dedicated to supervising large models. Small, specialized models of models help improve efficiency, reduce associated AI deployment costs, and make fine-tuning easier.The above is the detailed content of Google releases BIG-Bench Mistake dataset to help AI language models improve self-correction capabilities. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What should I do if win10 cannot find airpods?
- Google's Late Night King has a super update! PaLM 2 large model is shockingly released! Bard writes code and doesn't know what to do!
- Aragonite's latest reader, Onyx BOOX Palma, unveiled, looks as eye-catching as a mobile phone
- Kunlun Wanwei launches Tiangong AI Search: the first domestic AI search tool that integrates large-scale language models