
 Technology peripheralsAIMore effective than the mantra 'Let's think step by step', it reminds us that the project is being improved.
Technology peripheralsAIMore effective than the mantra 'Let's think step by step', it reminds us that the project is being improved.
Large language models can perform automatic hint engineering through meta-hints, but their potential may not be fully realized due to the lack of sufficient guidance to guide complex reasoning capabilities in large language models. So how to guide large language models to carry out automatic prompt projects?
Large language models (LLMs) are powerful tools in natural language processing tasks, but finding optimal cues often requires a lot of manual trial and error. Due to the sensitive nature of the model, even after deployment to production, unexpected edge cases may be encountered requiring further manual tuning to improve prompts. Therefore, although LLM has great potential, manual intervention is still required to optimize its performance in practical applications.
These challenges have given rise to the emerging research field of auto-cue engineering. One notable approach in this area is by leveraging LLM's own capabilities. Specifically, this involves using instructions to meta-cue LLM, such as "check the current prompt and sample batch, then generate a new prompt".
While these methods achieve impressive performance, the question that arises is: what kind of meta-hints are suitable for auto-hint engineering?
To answer this question, researchers from the University of Southern California and Microsoft discovered two key observations. First, prompt engineering itself is a complex language task that requires deep reasoning. This means carefully examining the model for errors, determining whether some information is missing or misleading in the current prompt, and finding ways to communicate the task more clearly. Secondly, in LLM, complex reasoning capabilities can be stimulated by guiding the model to think step by step. We can further improve this capability by instructing the model to reflect on its output. These observations provide valuable clues for solving this problem.

Paper address: https://arxiv.org/pdf/2311.05661.pdf
Through the previous observations, the researcher conducted a fine-tuning project, aiming to Establishing a meta-hint provides guidance for LLM to perform hint engineering more efficiently (see Figure 2 below). By reflecting on the limitations of existing methods and incorporating recent advances in complex reasoning prompts, they introduce meta-cue components such as step-by-step reasoning templates and context specifications to explicitly guide LLM's reasoning process in prompt engineering.
Additionally, since hint engineering is closely related to optimization problems, we can borrow some inspiration from common optimization concepts such as batch size, step size, and momentum and introduce them into meta-hints for improvements . We experimented with these components and variants on two mathematical inference datasets, MultiArith and GSM8K, and identified a top-performing combination, which we named PE2.
PE2 has made significant progress in empirical performance. When using TEXT-DAVINCI-003 as the task model, PE2-generated prompts improved by 6.3% on MultiArith and 3.1% on GSM8K over the step-by-step thinking prompts of the zero-shot thinking chain. Furthermore, PE2 outperforms the two auto-prompt engineering baselines, namely iterative APE and APO (see Figure 1).
It is worth noting that PE2 performs most effectively on the counterfactual task. Additionally, this study demonstrates the broad applicability of PE2 to optimizing lengthy, real-world prompts.

In reviewing PE2's prompt editing history, researchers found that PE2 consistently provides meaningful prompt editing. It is able to fix incorrect or incomplete hints and make the hints richer by adding additional details, resulting in an ultimate performance improvement (shown in Table 4).
Interestingly, when PE2 does not know addition in octal, it makes its own arithmetic rules from the example: "If both numbers are less than 50, add 2 to the sum. If one of the numbers is 50 or greater, add 22 to the sum." Although this is an imperfect and simple solution, it demonstrates PE2's remarkable ability to reason in counterfactual situations.
Despite these achievements, researchers have also recognized the limitations and failures of PE2. PE2 is also subject to limitations inherent in LLM, such as the plausibility of ignoring given instructions and generating errors (shown in Table 5 below).

Background knowledge
Prompt project
The goal of the prompt project is to find the text prompt p∗ that achieves the best performance on the given data set D when using the given LLM M_task as the task model (as shown in the following formula). More specifically, assume that all data sets can be formatted as text input-output pairs, i.e., D = {(x, y)}. A training set D_train for optimization hints, a D_dev for validation, and a D_test for final evaluation. According to the symbolic representation proposed by the researcher, the prompt engineering problem can be described as:

Among them, M_task (x; p) is generated by the model under the condition of given prompt p output, and f is the evaluation function for each example. For example, if the evaluation metric is an exact match, then 
Use LLM for auto-prompt engineering
Auto-prompt given an initial set of prompts Engineers will continually come up with new and possibly better tips. At timestamp t, the prompt engineer gets a prompt p^(t) and expects to write a new prompt p^(t 1). During the generation of a new hint, one can optionally examine a batch of examples B = {(x, y, y′ )}. Here y ′ = M_task (x; p) represents the output generated by the model and y represents the true label. Use p^meta to represent a meta-prompt that guides LLM's M_proposal to propose new proposals. Therefore,
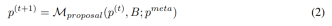
Building a better meta-cue p^meta to improve the quality of the proposed hint p^(t 1) is the main focus of this study.
Building better meta-cues
Just like cues play an important role in the final task performance, the meta-cue p^meta introduced in Equation 2 is in the new Plays an important role in the quality of the prompts presented and the overall quality of the automated prompts project.
Researchers mainly focus on hint engineering of meta-cue p^meta, developed meta-cue components that may help improve the quality of LLM hint engineering, and conducted systematic ablation research on these components.
The researchers designed the basis of these components based on the following two motivations: (1) Provide detailed guidance and background information; (2) Incorporate common optimizer concepts. Next, the researchers describe these elements in more detail and explain the underlying principles. Figure 2 below is a visual representation.

Provide detailed instructions and context. In previous studies, meta-cues either instructed the proposed model to generate a paraphrase of the prompt or contained minimal instructions about examining a batch of examples. Therefore it may be beneficial to add additional instructions and context to meta-cues.
(a) Prompt engineering tutorial. To help LLM better understand the task of prompt engineering, the researchers provide an online tutorial on prompt engineering in Meta-Click.
(b) Two-step task description. The prompt engineering task can be decomposed into two steps, as done by Pryzant et al.: In the first step, the model should examine the current prompt and a batch of examples. In the second step, the model should build an improved prompt. However, in Pryzant et al.'s approach, each step is explained on the fly. Instead, the researchers considered clarifying these two steps in the metacue and conveying expectations upfront.
(c) Step-by-step reasoning template. To encourage the model to carefully examine each example in batch B and reflect on the limitations of the current prompt, we guided the prompt proposal model M_proposal to answer a series of questions. For example: Is the output correct? Does the prompt describe the task correctly? Is it necessary to edit the prompt?
(d) Context specification. In practice, there is flexibility in where hints are inserted throughout the input sequence. It can describe the task before entering the text, such as "translate English to French." It can also appear after inputting text, such as "think step by step" to trigger reasoning skills. To recognize these different contexts, researchers explicitly specify the interaction between cues and input. For example: "Q: A: Think step by step."
Incorporate common optimizer concepts. The cue engineering problem described previously in Equation 1 is essentially an optimization problem, while the cue proposal in Equation 2 can be viewed as undergoing an optimization step. Therefore, researchers consider the following concepts commonly used in gradient-based optimization and develop their counterparts for use in meta-cues.
(e) Batch size. The batch size is the number of (failed) examples used in each tip proposal step (Equation 2). The authors tried batch sizes of {1, 2, 4, 8} in their analysis.
(f) step size. In gradient-based optimization, the step size determines how much the model weights are updated. In a prompt project, its counterpart might be the number of words (tokens) that can be modified. The author directly specifies "You can change up to s words in the original prompt", where s ∈ {5, 10, 15, None}.
(g) Optimize history and momentum. Momentum (Qian, 1999) is a technique that speeds up optimization and avoids oscillations by maintaining a moving average of past gradients. To develop the linguistic counterpart of momentum, this paper includes a summary of all past prompts (time stamped 0, 1, ..., t − 1), their performance on the dev set, and prompt edits.
Experiment
The author uses the following four sets of tasks to evaluate the effectiveness and limitations of PE2:
1. Mathematical reasoning; 2. Instruction induction ; 3. Counterfactual evaluation; 4. Production prompts.
Improved benchmarks and updated LLMs. In the first two parts of Table 2, the authors observe significant performance improvements using TEXT-DAVINCI-003, indicating that it is more capable of solving mathematical reasoning problems in Zero-shot CoT. Furthermore, the gap between the two cues decreased (MultiArith: 3.3% → 1.0%, GSM8K: 2.3% → 0.6%), indicating reduced sensitivity of TEXT-DAVINCI-003 to cue interpretation. For this reason, methods that rely on simple paraphrases, such as Iterative APE, may not be effective in improving the final results. More precise and targeted prompt editing is necessary to improve performance.
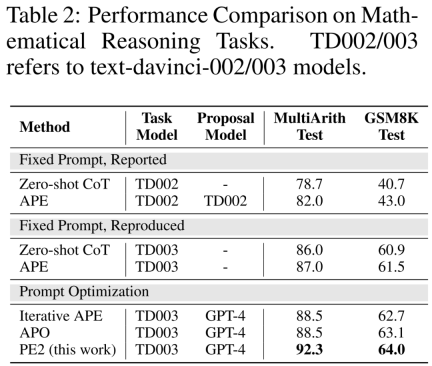
#PE2 outperforms Iterative APE and APO on a variety of tasks. PE2 is able to find a tip with 92.3% accuracy on MultiArith (6.3% better than Zero-shot CoT) and 64.0% on GSM8K (3.1%). Furthermore, PE2 found cues that outperformed Iterative APE and APO on the instruction induction benchmark, counterfactual evaluation, and production cues.
In Figure 1 above, the author summarizes the performance improvements achieved by PE2 on the instruction induction benchmark, counterfactual evaluation, and production prompts, demonstrating that PE2 achieves strong performance on various language tasks. Notably, when using inductive initialization, PE2 outperforms APO on 11 out of 12 counterfactual tasks (shown in Figure 6), demonstrating PE2’s ability to reason about paradoxical and counterfactual situations.

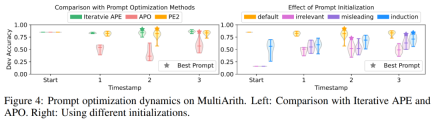
PE2 generates targeted prompt editing and high-quality prompts. In Figure 4(a), the authors plot the quality of the cue proposals during the cue optimization process. A very clear pattern was observed across the three cue optimization methods in the experiments: Iterative APE is based on paraphrasing, so the newly generated cues have smaller variance. APO undergoes drastic prompt editing, so performance degrades on the first step. PE2 is the most stable of the three methods. In Table 3, the authors list the best tips found by these methods. Both APO and PE2 can provide "consider all parts/details" instructions. Additionally, PE2 is designed to scrutinize batches, enabling it to go beyond simple paraphrase edits to very specific prompt edits such as "Remember to add or subtract as needed."
For more information, please refer to the original paper.
The above is the detailed content of More effective than the mantra 'Let's think step by step', it reminds us that the project is being improved.. For more information, please follow other related articles on the PHP Chinese website!

 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM
何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM去噪扩散模型(DDM)是目前广泛应用于图像生成的一种方法。最近,XinleiChen、ZhuangLiu、谢赛宁和何恺明四人团队对DDM进行了解构研究。通过逐步剥离其组件,他们发现DDM的生成能力逐渐下降,但表征学习能力仍然保持一定水平。这说明DDM中的某些组件对于表征学习的作用可能并不重要。针对当前计算机视觉等领域的生成模型,去噪被认为是一种核心方法。这类方法通常被称为去噪扩散模型(DDM),通过学习一个去噪自动编码器(DAE),能够通过扩散过程有效地消除多个层级的噪声。这些方法实现了出色的图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Atom editor mac version download
The most popular open source editor

