
Home >Technology peripherals >AI >Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models
Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-14 18:30:201414browse
Hallucinations are a common problem when working with large language models (LLMs). Although LLM can generate smooth and coherent text, the information it generates is often inaccurate or inconsistent. In order to prevent LLM from hallucinations, external knowledge sources, such as databases or knowledge graphs, can be used to provide factual information. In this way, LLM can rely on these reliable data sources, resulting in more accurate and reliable text content.
Vector database and knowledge graph
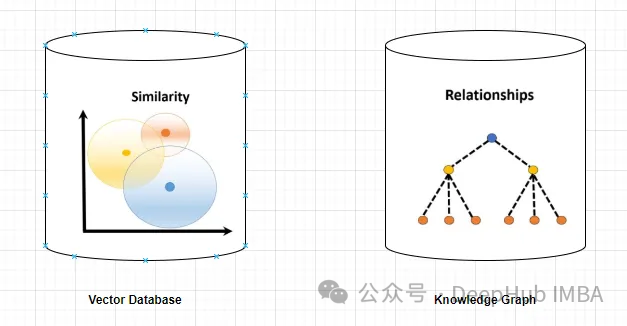
Vector database
A vector database is a set of high-dimensional vectors that represent entities or concepts. They can be used to measure the similarity or correlation between different entities or concepts, calculated through their vector representations.
A vector database can tell you, based on vector distance, that "Paris" and "France" are more related than "Paris" and "Germany".
Querying a vector database usually involves searching for similar vectors or vector retrieval based on specific criteria. The following is a simple example of querying a vector database.
Suppose there is a high-dimensional vector database that stores customer profiles. You want to find customers that are similar to a given reference customer.
First, in order to define a customer as a vector representation, we can extract relevant features or attributes and convert them into vector form.
A similarity search can be performed in a vector database using an appropriate algorithm (such as k-nearest neighbor or cosine similarity) to identify the most similar neighbors.
Retrieve customer profiles corresponding to determined nearest neighbor vectors that represent customers who are similar to a reference customer, according to a defined similarity measure.
Display retrieved customer profiles or related information such as name, demographic data, or purchase history to the user.
Knowledge Graph
A knowledge graph is a collection of nodes and edges that represent entities or concepts and their relationships (such as facts, attributes, or categories). Based on their node and edge attributes, they can be used to query or infer factual information about different entities or concepts.
For example, a knowledge graph can tell you that "Paris" is the capital of "France" based on edge labels.
Querying a graph database involves traversing the graph structure and retrieving nodes, relationships, or patterns based on specific criteria.
Suppose you have a graph database representing a social network, where users are nodes and their relationships are represented as edges connecting the nodes. If a friend of a friend (common connection) is found for a given user, then we should do the following:
1. Identify the node representing the reference user in the graph database. This can be accomplished by querying for a specific user identifier or other relevant criteria.
2. Use a graph query language, such as Cypher (used in Neo4j) or Gremlin, to traverse the graph from the reference user node. Specify patterns or relationships to explore.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fof
This query starts with the reference user, follows the FRIEND relationship to find another node (FRIEND), and then follows another FRIEND relationship to find the friend of a friend (fof).
3. Execute a query on the graph database and retrieve the result nodes (friends of friends) according to the query mode. You can obtain specific attributes or other information about the retrieved nodes.
Graph databases can provide more advanced query functions, including filtering, aggregation, and complex pattern matching. The specific query language and syntax may vary, but the general process involves traversing the graph structure to retrieve nodes and relationships that meet the required criteria.
Advantages of knowledge graphs in solving the "illusion" problem
Knowledge graphs provide more precise and specific information than vector databases. A vector database represents the similarity or correlation between two entities or concepts, while a knowledge graph allows for a better understanding of the relationship between them. For example, the knowledge graph can tell you that "Eiffel Tower" is the landmark of "Paris", while the vector database can only show the similarity of the two concepts, but it does not explain how they are related.
Knowledge graph supports more diverse and complex queries than vector databases. Vector databases can primarily answer queries based on vector distance, similarity, or nearest neighbors, which are limited to direct similarity measures. And the knowledge graph can handle queries based on logical operators, such as "What are all entities with attribute Z?" or "What is the common category of W and V?" This can help LLM generate more diverse and interesting texts.
Knowledge graphs are better for reasoning and inference than vector databases. Vector databases can only provide direct information stored in the database. And knowledge graphs can provide indirect information derived from relationships between entities or concepts. For example, a knowledge graph can infer "The Eiffel Tower is located in Europe" based on the two facts "Paris is the capital of France" and "France is located in Europe". This can help LLM generate more logical and consistent text.
So the knowledge graph is a better solution than the vector database. This provides LLMs with more accurate, relevant, diverse, interesting, logical and consistent information, making them more reliable in generating accurate and authentic text. But the key here is that there needs to be a clear relationship between document documents, otherwise the knowledge graph won’t be able to capture it.
但是,知识图谱的使用并没有向量数据库那么直接简单,不仅在内容的梳理(数据),应用部署,查询生成等方面都没有向量数据库那么方便,这也影响了它在实际应用中的使用频率。所以下面我们使用一个简单的例子来介绍如何使用知识图谱构建RAG。
代码实现
我们需要使用3个主要工具/组件:
1、LlamaIndex是一个编排框架,它简化了私有数据与公共数据的集成,它提供了数据摄取、索引和查询的工具,使其成为生成式人工智能需求的通用解决方案。
2、嵌入模型将文本转换为文本所提供的一条信息的数字表示形式。这种表示捕获了所嵌入内容的语义含义,使其对于许多行业应用程序都很健壮。这里使用“thenlper/gte-large”模型。
3、需要大型语言模型来根据所提供的问题和上下文生成响应。这里使用Zephyr 7B beta模型
下面我们开始进行代码编写,首先安装包
%%capture pip install llama_index pyvis Ipython langchain pypdf
启用日志Logging Level设置为“INFO”,我们可以输出有助于监视应用程序操作流的消息
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
导入依赖项
from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
我们使用Huggingface推理api端点载入LLM
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI(model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
首先载入嵌入模型:
embed_model = LangchainEmbedding(HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
加载数据集
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents)) ####Output### 44
构建知识图谱索引
创建知识图谱通常涉及专业和复杂的任务。通过利用Llama Index (LLM)、KnowledgeGraphIndex和GraphStore,可以方便地任何数据源创建一个相对有效的知识图谱。
#setup the service context service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowlege Graph Undex index = KnowledgeGraphIndex.from_documents( documents=documents,max_triplets_per_chunk=3,service_context=service_context,storage_context=storage_context,include_embeddings=True)
Max_triplets_per_chunk:它控制每个数据块处理的关系三元组的数量
Include_embeddings:切换在索引中包含嵌入以进行高级分析。
通过构建查询引擎对知识图谱进行查询
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True,response_mode ="tree_summarize",embedding_mode="hybrid",similarity_top_k=5,) # message_template =f"""Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer. Question: {query} Helpful Answer: """ # response = query_engine.query(message_template) # print(response.response.split("")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.
可以看到,输出的结果已经很好了,可以说与向量数据库的结果非常一致。
最后还可以可视化我们生成的图谱,使用Pyvis库进行可视化展示
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")
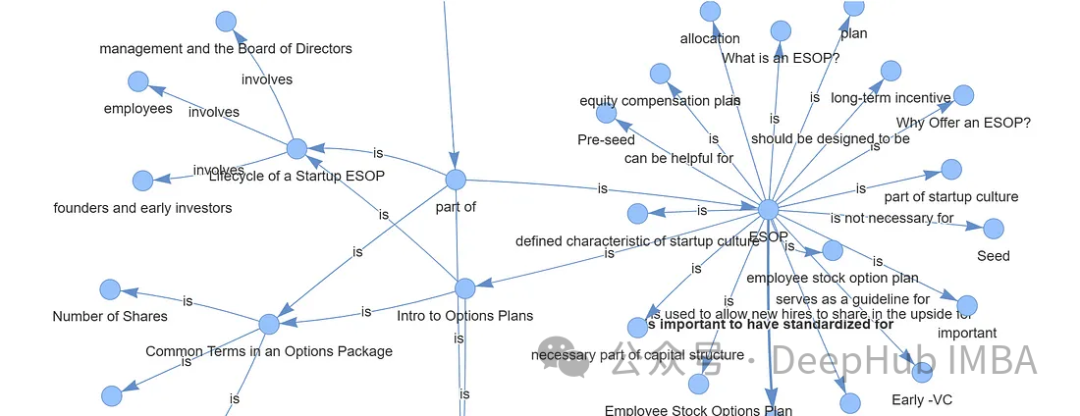

通过上面的代码我们可以直接通过LLM生成知识图谱,这样简化了我们非常多的人工操作。如果需要更精准更完整的知识图谱,还需要人工手动检查,这里就不细说了。
数据存储,通过持久化数据,可以将结果保存到硬盘中,供以后使用。
storage_context.persist()
存储的结果如下:

总结
向量数据库和知识图谱的区别在于它们存储和表示数据的方法。向量数据库擅长基于相似性的操作,依靠数值向量来测量实体之间的距离。知识图谱通过节点和边缘捕获复杂的关系和依赖关系,促进语义分析和高级推理。
对于语言模型(LLM)幻觉,知识图被证明优于向量数据库。知识图谱提供了更准确、多样、有趣、有逻辑性和一致性的信息,减少了LLM产生幻觉的可能性。这种优势源于它们能够提供实体之间关系的精确细节,而不仅仅是表明相似性,从而支持更复杂的查询和逻辑推理。
在以前知识图谱的应用难点在于图谱的构建,但是现在LLM的出现简化了这个过程,使得我们可以轻松的构建出可用的知识图谱,这使得他在应用方面又向前迈出了一大步。对于RAG,知识图谱是一个非常好的应用方向。
The above is the detailed content of Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Introduction to userAgent attribute information of major browsers (PC, mobile)
- How to use averageif function
- It is forbidden to make up large-scale language models randomly, and given some external knowledge, the reasoning is very reliable.
- How to reduce large language model hallucinations
- Lenovo executives revealed: Next year's new moto razr will have more stunning design and AI interaction, and the X series flagship will add large language model capabilities