

 Technology peripheralsAIClimbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue
Technology peripheralsAIClimbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue
When you and your friends are chatting across the cold mobile screen, you have to guess the other person’s tone. When he speaks, his expressions and even actions can appear in your mind. It would obviously be best if you could make a video call, but in actual situations you cannot make video calls at any time.
If you are chatting with a remote friend, it is not through cold screen text or an avatar lacking expressions, but a realistic, dynamic, and expressive digital virtual person. This virtual person can not only perfectly reproduce your friend's smile, eyes, and even subtle body movements. Will you feel more kind and warm? It really embodies the sentence "I will crawl along the network cable to find you."
This is not a science fiction imagination, but a technology that can be realized in reality.
Facial expressions and body movements contain a large amount of information, which will greatly affect the meaning of the content. For example, speaking while looking at the other party all the time will give people a completely different feeling than speaking without making eye contact, which will also affect the other party's understanding of the communication content. We have an extremely keen ability to detect these subtle expressions and movements during communication and use them to develop a high-level understanding of the conversation partner's intention, comfort level, or understanding. Therefore, developing highly realistic conversational avatars that capture these subtleties is critical for interaction.
To this end, Meta and researchers from the University of California have proposed a method to generate realistic virtual humans based on the speech audio of a conversation between two people. It can synthesize a variety of high-frequency gestures and expressive facial movements that are closely synchronized with speech. For the body and hand, they exploit the advantages of an autoregressive VQ-based approach and a diffusion model. For faces, they use a diffusion model conditioned on audio. The predicted facial, body, and hand movements are then rendered into realistic virtual humans. We demonstrate that adding guided gesture conditions to the diffusion model can generate more diverse and reasonable conversational gestures than previous works.

- Paper address: https://huggingface.co/papers/2401.01885
- Project address: https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
The researchers say they are the first team to study how to generate realistic facial, body and hand movements for interpersonal conversations. Compared with previous studies, the researchers synthesized more realistic and diverse actions based on VQ and diffusion methods.
Method Overview
The researchers extracted latent expression codes from recorded multi-view data to represent faces and used joint angles in the kinematic skeleton to express body posture. As shown in Figure 3, this system consists of two generative models, which generate expression codes and body posture sequences when inputting two-person conversation audio. The expression code and body pose sequences can then be rendered frame by frame using the Neural Avatar Renderer, which can generate a fully textured avatar with face, body and hands from a given camera view.
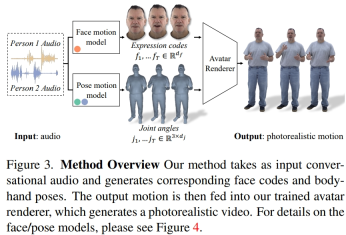
It should be noted that the dynamics of the body and face are very different. First, faces are strongly correlated with input audio, especially lip movements, while bodies are weakly correlated with speech. This results in a more complex diversity of body gestures in a given speech input. Second, since faces and bodies are represented in two different spaces, they each follow different temporal dynamics. Therefore, the researchers used two independent motion models to simulate the face and body. In this way, the face model can "focus" on facial details that are consistent with speech, while the body model can focus more on generating diverse but reasonable body movements.
The facial motion model is a diffusion model conditioned on input audio and lip vertices generated by a pre-trained lip regressor (Figure 4a). For the limb movement model, researchers found that the movement produced by a pure diffusion model conditioned only on audio lacked diversity and was not coordinated enough in time series. However, the quality improved when the researchers conditioned on different guidance postures. Therefore, they split the body motion model into two parts: first, the autoregressive audio conditioner predicts coarse guidance poses at 1 fp (Fig. 4b), and then the diffusion model utilizes these coarse guidance poses to fill in fine-grained and high-frequency motions (Fig. 4c). See the original article for more details on method settings.
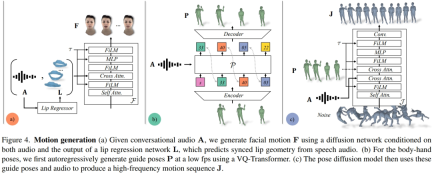
Experiments and results
The researchers quantitatively evaluated Audio2Photoreal’s effectiveness in generating realistic dialogue actions based on real data Ability. Perceptual evaluations were also performed to corroborate the quantitative results and measure the appropriateness of Audio2Photoreal in generating gestures in a given conversational context. Experimental results showed that evaluators were more sensitive to subtle gestures when the gestures were presented on a realistic avatar rather than a 3D mesh.
The researchers compared the generation results of this method with three baseline methods: KNN, SHOW, and LDA based on random motion sequences in the training set. Ablation experiments were conducted to test the effectiveness of each component of Audio2Photoreal without audio or guided gestures, without guided gestures but based on audio, and without audio but based on guided gestures.
Quantitative results
Table 1 shows that compared with previous studies, this method has the highest diversity in generation The FD score is lowest when exercising. While random has good diversity that matches GT, random segments do not match the corresponding conversation dynamics, resulting in high FD_g.

Figure 5 shows the diversity of guidance poses generated by our method. VQ-based transformer P-sampling enables the generation of very different gestures with the same audio input.

As shown in Figure 6, the diffusion model will learn to generate dynamic actions, and the actions will better match the dialogue audio .

Figure 7 shows that the motion generated by LDA lacks energy and has less movement. In contrast, the motion changes synthesized by this method are more consistent with the actual situation.
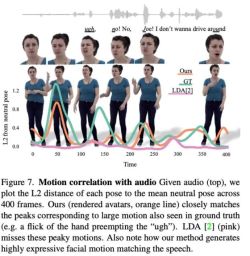
In addition, the researchers also analyzed the accuracy of this method in generating lip movements. As the statistics in Table 2 show, Audio2Photoreal significantly outperforms the baseline method SHOW, as well as the performance after removing the pretrained lip regressor in the ablation experiments. This design improves the synchronization of mouth shapes when speaking, effectively avoids random opening and closing movements of the mouth when not speaking, enables the model to achieve better lip movement reconstruction, and at the same time reduces the facial mesh vertices ( Grid L2) error.

Qualitative evaluation
Due to the coherence of gestures in dialogue, it is difficult to Quantitatively, the researchers used qualitative methods for evaluation. They conducted two sets of A/B tests on MTurk. Specifically, they asked evaluators to watch the generated results of our method and the baseline method or the video pair of our method and real scenes, and asked them to evaluate which video in which the motion looked more reasonable.
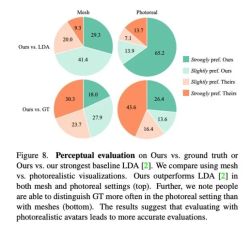
As shown in Figure 8, this method is significantly better than the previous baseline method LDA, and about 70% of the reviewers prefer Audio2Photoreal in terms of grid and realism.
As shown in the top chart of Figure 8, compared with LDA, the evaluators’ evaluation of this method changed from “slightly prefer” to “strongly like”. Compared with the real situation, the same evaluation is presented. Still, evaluators favored the real thing over Audio2Photoreal when it came to realism.
For more technical details, please read the original paper.
The above is the detailed content of Climbing along the network cable has become a reality, Audio2Photoreal can generate realistic expressions and movements through dialogue. For more information, please follow other related articles on the PHP Chinese website!

 undress free porn AI tool websiteMay 13, 2025 am 11:26 AM
undress free porn AI tool websiteMay 13, 2025 am 11:26 AMhttps://undressaitool.ai/ is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 How to create pornographic images/videos using undressAIMay 13, 2025 am 11:26 AM
How to create pornographic images/videos using undressAIMay 13, 2025 am 11:26 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
 undress AI official website entrance website addressMay 13, 2025 am 11:26 AM
undress AI official website entrance website addressMay 13, 2025 am 11:26 AMThe official address of undress AI is:https://undressaitool.ai/;undressAI is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 How does undressAI generate pornographic images/videos?May 13, 2025 am 11:26 AM
How does undressAI generate pornographic images/videos?May 13, 2025 am 11:26 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
 undressAI porn AI official website addressMay 13, 2025 am 11:26 AM
undressAI porn AI official website addressMay 13, 2025 am 11:26 AMThe official address of undress AI is:https://undressaitool.ai/;undressAI is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 UndressAI usage tutorial guide articleMay 13, 2025 am 10:43 AM
UndressAI usage tutorial guide articleMay 13, 2025 am 10:43 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
![[Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyright](https://img.php.cn/upload/article/001/242/473/174707263295098.jpg?x-oss-process=image/resize,p_40) [Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyrightMay 13, 2025 am 01:57 AM
[Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyrightMay 13, 2025 am 01:57 AMThe latest model GPT-4o released by OpenAI not only can generate text, but also has image generation functions, which has attracted widespread attention. The most eye-catching feature is the generation of "Ghibli-style illustrations". Simply upload the photo to ChatGPT and give simple instructions to generate a dreamy image like a work in Studio Ghibli. This article will explain in detail the actual operation process, the effect experience, as well as the errors and copyright issues that need to be paid attention to. For details of the latest model "o3" released by OpenAI, please click here⬇️ Detailed explanation of OpenAI o3 (ChatGPT o3): Features, pricing system and o4-mini introduction Please click here for the English version of Ghibli-style article⬇️ Create Ji with ChatGPT
 Explaining examples of use and implementation of ChatGPT in local governments! Also introduces banned local governmentsMay 13, 2025 am 01:53 AM
Explaining examples of use and implementation of ChatGPT in local governments! Also introduces banned local governmentsMay 13, 2025 am 01:53 AMAs a new communication method, the use and introduction of ChatGPT in local governments is attracting attention. While this trend is progressing in a wide range of areas, some local governments have declined to use ChatGPT. In this article, we will introduce examples of ChatGPT implementation in local governments. We will explore how we are achieving quality and efficiency improvements in local government services through a variety of reform examples, including supporting document creation and dialogue with citizens. Not only local government officials who aim to reduce staff workload and improve convenience for citizens, but also all interested in advanced use cases.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Chinese version
Chinese version, very easy to use

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver Mac version
Visual web development tools

