
 Technology peripheralsAILarge model + robot, a detailed review report is here, with the participation of many Chinese scholars
Technology peripheralsAILarge model + robot, a detailed review report is here, with the participation of many Chinese scholarsLarge model + robot, a detailed review report is here, with the participation of many Chinese scholars

The outstanding capabilities of large models are obvious to all, and if they are integrated into robots, it is expected that robots will have a more intelligent brain, bringing new possibilities to the field of robotics, such as autonomous driving, home robots, industrial robots, and assistance Robots, medical robots, field robots and multi-robot systems.
Pre-trained Large Language Model (LLM), Large Vision-Language Model (VLM), Large Audio-Language Model (ALM) and Large Visual Navigation Model (VNM) can be used to better handle robots various tasks in the field. Integrating basic models into robotics is a rapidly growing field, and the robotics community has recently begun to explore the use of these large models in robotics areas that need to be rewritten: perception, prediction, planning, and control.
Recently, a joint research team composed of Stanford University, Princeton University, NVIDIA, Google DeepMind and other companies released a review report summarizing the development and future of basic models in the field of robotics research. Challenge

Paper address: https://arxiv.org/pdf/2312.07843.pdf
The rewritten content is: Paper library: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
There are many Chinese scholars we are familiar with among the team members , including Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu, etc.
The basic model is extensively pre-trained using large-scale data and can be applied to various downstream tasks after fine-tuning. These basic models have made major breakthroughs in the fields of vision and language processing, including related models such as BERT, GPT-3, GPT-4, CLIP, DALL-E and PaLM-E
Before the emergence of the basic models, Traditional deep learning models for robotics are trained using limited data sets collected for different tasks. In contrast, base models are pre-trained using a wide range of diverse data and have demonstrated adaptability, generalization, and overall performance in other areas such as natural language processing, computer vision, and healthcare. Eventually, the basic model is also expected to show its potential in the field of robotics. Figure 1 shows an overview of the basic model in the field of robotics.
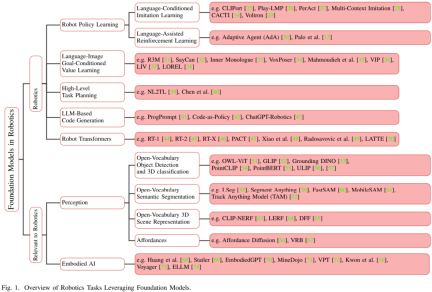
Transferring knowledge from a base model has the potential to reduce training time and computing resources compared to task-specific models. Especially in robotics-related fields, multimodal base models can fuse and align multimodal heterogeneous data collected from different sensors into compact homogeneous representations, which are needed for robot understanding and reasoning. The representations it learns can be used in any part of the automation technology stack, including those that need to be rewritten: perception, decision-making, and control.
Not only that, the basic model can also provide zero-sample learning capabilities, which means that the AI system has the ability to perform tasks without any examples or targeted training. This allows the robot to generalize the knowledge it has learned to new use cases, enhancing the robot's adaptability and flexibility in unstructured environments.
Integrating the basic model into the robot system can improve the robot's ability to perceive the environment and interact with the environment. It is possible to realize the context that needs to be rewritten: the perceptual robot system.
For example, in the field of perception that needs to be rewritten, large-scale visual-language models (VLM) can learn the association between visual and text data, so as to have cross-modal understanding capabilities, thereby assisting zero Tasks such as sample image classification, zero-sample target detection, and 3D classification. As another example, language grounding (i.e., aligning the VLM's contextual understanding with the 3D real world) in the 3D world can enhance the robot's spatial needs by associating utterances with specific objects, locations, or actions in the 3D environment. Rewritten: Perceptual ability. In the field of decision-making or planning, research has found that LLM and VLM can assist robots in specifying tasks involving high-level planning.
By exploiting language cues related to operation, navigation and interaction, robots can perform more complex tasks. For example, for robot policy learning technologies such as imitation learning and reinforcement learning, the basic model seems to have the ability to improve data efficiency and context understanding. In particular, language-driven rewards can guide reinforcement learning agents by providing shaped rewards.
In addition, researchers are already using language models to provide feedback for strategy learning technology. Some studies have shown that the visual question answering (VQA) capabilities of VLM models can be used for robotics use cases. For example, researchers have used VLM to answer questions related to visual content to help robots complete tasks. In addition, some researchers use VLM to help with data annotation and generate description labels for visual content.
Despite the transformative capabilities of the basic model in vision and language processing, generalization and fine-tuning of the basic model for real-world robotic tasks remains challenging.
These challenges include:
1) Lack of data: How to obtain Internet-scale data to support tasks such as robot operation, positioning, and navigation, and how to use these data for self-supervised training;
2) Huge diversity: How to deal with the huge diversity of physical environments, physical robotic platforms, and potential robotic tasks while maintaining the required generality of the underlying model;
3) Uncertain Quantitative issues: How to solve instance-level uncertainties (such as language ambiguity or LLM illusion), distribution-level uncertainties and distribution shift problems, especially the distribution shift problem caused by closed-loop robot deployment.
4) Safety assessment: How to rigorously test the robot system based on the basic model before deployment, during the update process, and during the work process.
5) Real-time performance: How to deal with the long inference time of some basic models - this will hinder the deployment of basic models on robots, and how to accelerate the inference of basic models - this is the key to online decision-making required.
This review paper summarizes the current use of basic models in the field of robotics. The researchers survey current methods, applications, and challenges and propose future research directions to address these challenges. They also pointed out the potential risks that may exist in using the base model to achieve robot autonomy
Background knowledge of the base model
The base model has billions of parameters , and uses Internet-level large-scale data for pre-training. Training such a large and complex model is very expensive. The cost of acquiring, processing and managing data can also be high. Its training process requires a large amount of computing resources, requires the use of dedicated hardware such as GPU or TPU, and also requires software and infrastructure for model training, which all require financial investment. In addition, the training time of the base model is also very long, which also leads to high costs. Therefore, these models are often used as pluggable modules, that is, the base model can be integrated into various applications without extensive customization work
Table 1 gives the details of commonly used base models.
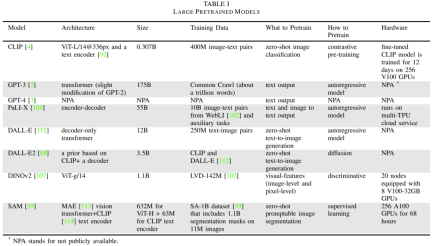
This section will focus on LLM, visual Transformer, VLM, embodied multi-modal language model and visual generative model. In addition, different training methods used to train the base model will also be introduced
They first introduce some related terminology and mathematical knowledge, which involves tokenization, generative models, discriminative models, Transformer architecture, autoregressive models, Masked automatic encoding, contrastive learning, and diffusion models.
They then introduce examples and historical background of large language models (LLMs). Afterwards, the visual Transformer, multimodal vision-language model (VLM), embodied multimodal language model, and visual generation model were highlighted.
Robot Research
This section focuses on robot decision-making, planning and control. In this area, both large language models (LLM) and visual language models (VLM) have the potential to be used to enhance the capabilities of robots. For example, LLM can facilitate the task specification process so that robots can receive and interpret high-level instructions from humans.
VLM is also expected to contribute to this area. VLM excels at analyzing visual data. For robots to make informed decisions and perform complex tasks, visual understanding is crucial. Now, robots can use natural language cues to enhance their ability to perform tasks related to manipulation, navigation, and interaction.
Goal-based visual-linguistic policy learning (whether through imitation learning or reinforcement learning) is expected to be improved by basic models. Language models can also provide feedback for policy learning techniques. This feedback loop helps continuously improve the robot's decision-making capabilities, as the robot can optimize its actions based on the feedback it receives from the LLM.
This section focuses on the application of LLM and VLM in the field of robot decision-making.
This section is divided into six parts. The first part introduces policy learning for decision-making and control and robots, including language-based imitation learning and language-assisted reinforcement learning.
The second part is goal-based language-image value learning.
The third part introduces the use of large-scale language models to plan robot tasks, which includes explaining tasks through language instructions and using language models to generate code for task planning.
The fourth part is contextual learning (ICL) for decision-making.
The next one to introduce is Robot Transformers
The sixth part is the robot navigation and operation of the open vocabulary library.
Table 2 gives some basic robot-specific models, reporting model size and architecture, pre-training tasks, inference time, and hardware setup.
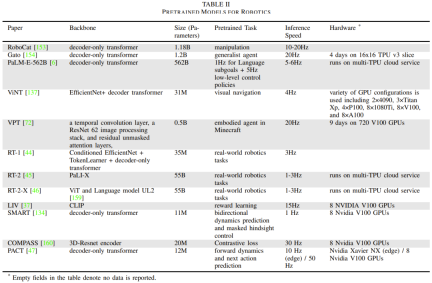
What needs to be rewritten is: perception
Robots that interact with their surrounding environment receive sensory information in different modalities, such as images, videos, audio, and language. This high-dimensional data is critical for robots to understand, reason, and interact with their environment. Basic models can transform these high-dimensional inputs into abstract structured representations that are easy to interpret and manipulate. In particular, multimodal base models allow robots to integrate input from different senses into a unified representation that contains semantic, spatial, temporal, and affordance information. These multimodal models require cross-modal interactions, often requiring alignment of elements from different modalities to ensure consistency and mutual correspondence. For example, image description tasks require alignment of text and image data.
This section will focus on what robots need to rewrite: a series of tasks related to perception that can be improved by using basic models to align modalities. The emphasis is on vision and language.
This section is divided into five parts, first is the target detection and 3D classification of the open vocabulary, then is the semantic segmentation of the open vocabulary, then is the 3D scene and target representation of the open vocabulary, and then are the learned affordances, and finally the predictive model.
Embodied AI
Recently, some studies have shown that LLM can be successfully used in the field of embodied AI, where "embodied" usually refers to the Virtual embodiment in a world simulator rather than having a physical robotic body.
Some interesting frameworks, data sets and models have emerged in this area. Of particular note is the use of the Minecraft game as a platform for training embodied agents. For example, Voyager uses GPT-4 to guide agents exploring Minecraft environments. It can interact with GPT-4 through contextual prompt design without the need to fine-tune GPT-4's model parameters.
Reinforcement learning is an important research direction in the field of robot learning. Researchers are trying to use basic models to design reward functions to optimize reinforcement learning
For robots to perform high-level planning, researchers have been Use basic models to assist in exploration. In addition, some researchers are trying to apply thinking chain-based reasoning and action generation methods to embodied intelligence
Challenges and future directions
This section will Challenges associated with using base models for robotics are given. The team will also explore future research directions that may address these challenges.
The first challenge is to overcome the data scarcity issue when training base models for robots, including:
1. Using unstructured game data and unlabeled human videos To expand robot learning
2. Use image inpainting (Inpainting) to enhance data
3. Overcome the problem of lack of 3D data when training 3D basic models
4. By High-fidelity simulation to generate synthetic data
5. Use VLM for data augmentation Using VLM for data augmentation is an effective method
6. The physical skills of the robot are limited by the distribution of skills
The second challenge is related to real-time performance, of which the key is the foundation Model inference time.
The third challenge involves the limitations of multimodal representation.
The fourth challenge is how to quantify uncertainty at different levels, such as the instance level and the distribution level. It also involves the problem of how to calibrate and deal with distribution shifts.
The fifth challenge involves security assessment, including security testing before deployment and runtime monitoring and detection of out-of-distribution situations.
The sixth challenge involves how to choose: use an existing base model or build a new base model for the robot?
The seventh challenge involves the high variability in the robot setup.
The eighth challenge is how to benchmark and ensure reproducibility in a robot setting.
For more research details, please refer to the original paper.
The above is the detailed content of Large model + robot, a detailed review report is here, with the participation of many Chinese scholars. For more information, please follow other related articles on the PHP Chinese website!

 Cooking Up Innovation: How Artificial Intelligence Is Transforming Food ServiceApr 12, 2025 pm 12:09 PM
Cooking Up Innovation: How Artificial Intelligence Is Transforming Food ServiceApr 12, 2025 pm 12:09 PMAI Augmenting Food Preparation While still in nascent use, AI systems are being increasingly used in food preparation. AI-driven robots are used in kitchens to automate food preparation tasks, such as flipping burgers, making pizzas, or assembling sa
 Comprehensive Guide on Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PM
Comprehensive Guide on Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PMIntroduction Understanding the namespaces, scopes, and behavior of variables in Python functions is crucial for writing efficiently and avoiding runtime errors or exceptions. In this article, we’ll delve into various asp
 A Comprehensive Guide to Vision Language Models (VLMs)Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)Apr 12, 2025 am 11:58 AMIntroduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 MediaTek Boosts Premium Lineup With Kompanio Ultra And Dimensity 9400Apr 12, 2025 am 11:52 AM
MediaTek Boosts Premium Lineup With Kompanio Ultra And Dimensity 9400Apr 12, 2025 am 11:52 AMContinuing the product cadence, this month MediaTek has made a series of announcements, including the new Kompanio Ultra and Dimensity 9400 . These products fill in the more traditional parts of MediaTek’s business, which include chips for smartphone
 This Week In AI: Walmart Sets Fashion Trends Before They Ever HappenApr 12, 2025 am 11:51 AM
This Week In AI: Walmart Sets Fashion Trends Before They Ever HappenApr 12, 2025 am 11:51 AM#1 Google launched Agent2Agent The Story: It’s Monday morning. As an AI-powered recruiter you work smarter, not harder. You log into your company’s dashboard on your phone. It tells you three critical roles have been sourced, vetted, and scheduled fo
 Generative AI Meets PsychobabbleApr 12, 2025 am 11:50 AM
Generative AI Meets PsychobabbleApr 12, 2025 am 11:50 AMI would guess that you must be. We all seem to know that psychobabble consists of assorted chatter that mixes various psychological terminology and often ends up being either incomprehensible or completely nonsensical. All you need to do to spew fo
 The Prototype: Scientists Turn Paper Into PlasticApr 12, 2025 am 11:49 AM
The Prototype: Scientists Turn Paper Into PlasticApr 12, 2025 am 11:49 AMOnly 9.5% of plastics manufactured in 2022 were made from recycled materials, according to a new study published this week. Meanwhile, plastic continues to pile up in landfills–and ecosystems–around the world. But help is on the way. A team of engin
 The Rise Of The AI Analyst: Why This Could Be The Most Important Job In The AI RevolutionApr 12, 2025 am 11:41 AM
The Rise Of The AI Analyst: Why This Could Be The Most Important Job In The AI RevolutionApr 12, 2025 am 11:41 AMMy recent conversation with Andy MacMillan, CEO of leading enterprise analytics platform Alteryx, highlighted this critical yet underappreciated role in the AI revolution. As MacMillan explains, the gap between raw business data and AI-ready informat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

