

 Technology peripheralsAIGoogle's DeepMind robot has released three results in a row! Both capabilities have been improved, and the data collection system can manage 20 robots at the same time.
Technology peripheralsAIGoogle's DeepMind robot has released three results in a row! Both capabilities have been improved, and the data collection system can manage 20 robots at the same time.
Almost at the same time as Stanford’s “Shrimp Fried and Dishwashing” robot, Google DeepMind also released its latest embodied intelligence results.

And it’s three consecutive shots:
First, a new model that focuses on improving decision-making speed, let The robot's operation speed (compared to the original Robotics Transformer) has increased by 14% - while being fast, the quality has not declined, and the accuracy has also increased by 10.6%.

Then there is a new frameworkspecializing in generalization ability, which can create motion trajectory prompts for the robot and let it face 41 never-before-seen tasks, achieving a 63% success rate.

Don’t underestimate this array, Compared with the previous 29%, the improvement is quite big.
Finally a robot data collection system that can manage 20 robots at a time and has currently collected 77,000 experimental data from their activities, they will help Google does a better job of subsequent training.

So, what are these three results specifically? Let’s look at them one by one.
The first step in making robots a daily routine: Unseen tasks can be done directly
Google pointed out that to realize a robot that can truly enter the real world, two basic challenges need to be solved.
1. Ability to promote new tasks
2. Improve decision-making speed
The first two results of this three-part series are mainly improvements in these two areas, and All are built on Google's basic robot model Robotics Transformer (RT for short).
Let’s first look at the first one: RT-Trajectory that helps robots generalize.
For humans, tasks such as cleaning tables are easy to understand, but robots don’t understand it very well.
But fortunately, we can convey this instruction to it in a variety of possible ways, so that it can take actual physical actions.
Generally speaking, the traditional way is to map the task into a specific action, and then let the robot arm complete it. For example, wiping the table can be broken down into "close the clamp, move to the left, move to the left, and close the clamp to the left." Move right".
Obviously, the generalization ability of this method is very poor.
Here, Google’s newly proposed RT-Trajectory teaches the robot to complete tasks by providing visual cues.
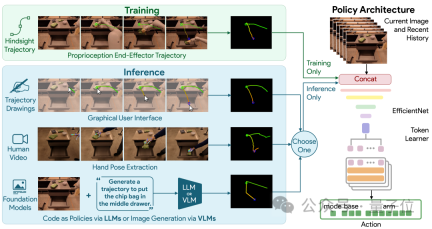
Specifically, robots controlled by RT-Trajectory will add 2D trajectory enhanced data during training.
These trajectories are presented as RGB images, including routes and key points, providing low-level but very useful hints as the robot learns to perform tasks.
With this model, the success rate of robots performing never-before-seen tasks has been directly increased by as much as 1 times (compared to Google's basic robot model RT-2, from 29%=> 63%).
What’s more worth mentioning is that RT-Trajectory can create trajectories in a variety of ways, including:
By watching human demonstrations, accepting hand-drawn sketches, and through VLM (Visual Language Model) to generate.

The second step of daily robotization: the decision-making speed must be fast
After the generalization ability is improved, we will focus on the decision-making speed.
Google’s RT model uses the Transformer architecture. Although the Transformer is powerful, it relies heavily on the attention module with quadratic complexity.
Therefore, once the input to the RT model is doubled (for example, by equipping the robot with a higher-resolution sensor), the computational resources required to process it will increase by four times. This will severely slow down decision-making.
In order to improve the speed of robots, Google developedSARA-RT on the basic model Robotics Transformer.
SARA-RT uses a new model fine-tuning method to make the original RT model more efficient.
This method is called "up training" by Google. Its main function is to convert the original quadratic complexity into linear complexity, and at the same time Maintain processing quality.
When SARA-RT is applied to the RT-2 model with billions of parameters, the latter can achieve faster operation speeds and higher accuracy on a variety of tasks.
It is also worth mentioning that SARA-RT provides a universal method to accelerate Transformer without expensive pre-training, so it can Well promoted.
Not enough data? Create your own
Finally, in order to help robots better understand the tasks assigned by humans, Google also started with data and directly built a collection system: AutoRT.
This system combines the large model (including LLM and VLM) with the robot control model (RT) to continuously command the robot to perform various tasks in the real world. tasks to generate and collect data.
The specific process is as follows:
Let the robot "freely" contact the environment and get close to the target.
Then use the camera and VLM model to describe the scene in front of you, including the specific items.
Then, LLM uses this information to generate several different tasks.
Note that the robot will not be executed immediately after being generated. Instead, LLM will be used to filter which tasks can be completed independently, which ones require human remote control, and which ones It simply cannot be completed.
What cannot be accomplished is "opening the bag of potato chips" because it requires two robotic arms (only 1 by default) .
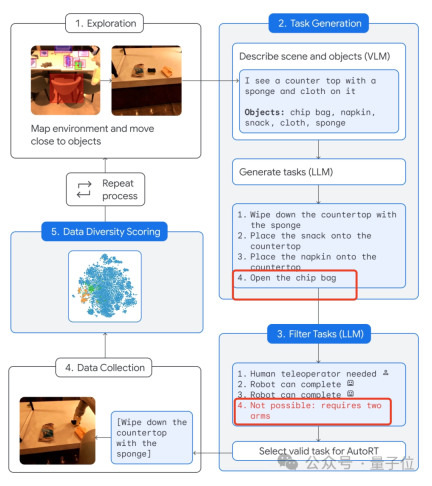
Then, after completing this screening task, the robot can actually execute it.
Finally, the AutoRT system completes data collection and conducts diversity assessment.
According to reports, AutoRT can coordinate up to 20 robots at a time. Within 7 months, a total of 77,000 test data including 6,650 unique tasks were collected.
Finally, for this system, Google also emphasizes security.
After all, AutoRT’s collection tasks affect the real world, and “safety guardrails” are indispensable.
Specifically, the Basic Safety Code is provided by the LLM that performs task screening for robots, and is partly inspired by Isaac Asimov’s Three Laws of Robotics – first and foremost “Robots” Must not harm humans.
The second requirement is that the robot must not attempt tasks involving humans, animals, sharp objects or electrical appliances.
But this is not enough.
So AutoRT It is also equipped with multiple layers of practical safety measures found in conventional robotics.
For example, the robot automatically stops when the force on its joints exceeds a given threshold, and all actions can be controlled by physical switches that remain within human sight. Stop and wait.

Want to know more about these latest results from Google?
Good news, except for RT-Trajectory, which only has online papers, the rest are The code and paper are released together, and everyone is welcome to check it out~
One More Thing
Speaking of Google robots, we have to mention RT-2( All the results of this article are also based on).
This model was built by 54 Google researchers for 7 months and came out at the end of July this year.
embedded visual-text The multi-modal large model VLM can not only understand "human speech", but can also reason about "human speech" and perform some tasks that cannot be accomplished in one step, such as extracting information from three plastic toys: a lion, a whale, and a dinosaur. It's amazing to accurately pick up "extinct animals".

#Now it has achieved generalization ability and decision-making speed in just over 5 months The rapid improvement of robots can't help but make us sigh: I can't imagine how fast robots will really break into thousands of households.
The above is the detailed content of Google's DeepMind robot has released three results in a row! Both capabilities have been improved, and the data collection system can manage 20 robots at the same time.. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

WebStorm Mac version
Useful JavaScript development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 English version
Recommended: Win version, supports code prompts!

Zend Studio 13.0.1
Powerful PHP integrated development environment

