

 Technology peripheralsAINeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2Real
Technology peripheralsAINeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2RealNeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2Real

Written in front&The author's personal summary
Bird eye's view (BEV) detection is a method of detection by fusing multiple surround-view cameras. Most of the current algorithms are trained and evaluated on the same data set, which causes these algorithms to overfit to the unchanged camera internal parameters (camera type) and external parameters (camera placement). This paper proposes a BEV detection framework based on implicit rendering, which can solve the problem of object detection in unknown domains. The framework uses implicit rendering to establish the relationship between the 3D position of the object and the perspective position of a single view, which can be used to correct perspective bias. This method achieves significant performance improvements in domain generalization (DG) and unsupervised domain adaptation (UDA). This method is the first attempt to use only virtual data sets for training and evaluation of BEV detection in real scenarios, which can break the barriers between virtual and real to complete closed-loop testing.
- Paper link: https://arxiv.org/pdf/2310.11346.pdf
- Code link: https://github.com/EnVision-Research/Generalizable-BEV

BEV detection domain generalization problem background
Multi-camera detection refers to the use of multiple cameras to detect objects in three-dimensional space. Object detection and localization tasks. By combining information from different viewpoints, multi-camera 3D object detection can provide more accurate and robust object detection results, especially in situations where targets from certain viewpoints may be occluded or partially visible. In recent years, the Bird eye's view (BEV) method has received great attention in multi-camera detection tasks. Although these methods have advantages in multi-camera information fusion, the performance of these methods may be severely degraded when the test environment is significantly different from the training environment.
Currently, most BEV detection algorithms are trained and evaluated on the same data set, which causes these algorithms to be too sensitive to changes in internal and external camera parameters and urban road conditions, leading to serious over-fitting problems. However, in practical applications, BEV detection algorithms often need to adapt to different new models and new cameras, which leads to the failure of these algorithms. Therefore, it is important to study the generalizability of BEV detection. In addition, closed-loop simulation is also very important for autonomous driving, but currently it can only be evaluated in virtual engines such as Carla. Therefore, it is necessary to solve the problem of domain differences between the virtual engine and the real scene. Domain generalization (DG) and unsupervised domain adaptation (UDA) are the ways to alleviate the distribution shift. Two promising directions. DG methods often decouple and eliminate domain-specific features, thereby improving generalization performance in unseen domains. For UDA, recent methods mitigate domain shift by generating pseudo-labels or latent feature distribution alignment. However, learning viewpoint- and environment-independent features for pure visual perception is very challenging without using data from different viewpoints, camera parameters, and environments.
Observations show that 2D detection from a single perspective (camera plane) often has stronger generalization capabilities than 3D target detection from multiple perspectives, as shown in the figure. Some studies have explored integrating 2D detection into BEV detection, such as fusing 2D information into 3D detectors or establishing 2D-3D consistency. 2D information fusion is a learning-based method rather than a mechanism modeling method, and is still severely affected by domain migration. Existing 2D-3D consistency methods project the 3D results onto a two-dimensional plane and establish consistency. This constraint may harm the semantic information in the target domain instead of modifying the geometric information of the target domain. Furthermore, this 2D-3D consistency approach makes a unified approach for all detection heads challenging.
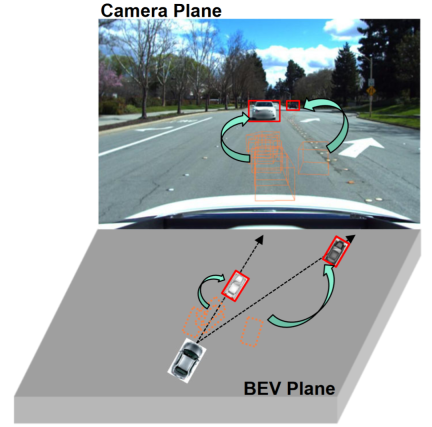
This paper proposes a generalized BEV detection based on perspective debiasing framework, which not only helps the model learn perspective and context-invariant features in the source domain, but also utilizes 2D detectors to further correct spurious geometric features in the target domain.
- This paper is the first attempt to study unsupervised domain adaptation in BEV detection and establishes a benchmark. State-of-the-art results are achieved on both UDA and DG protocols.
- This paper explores for the first time training on a virtual engine without real scene annotations to achieve real-world BEV detection tasks.
Problem definition
The research mainly focuses on enhancing the generalization of BEV detection change. To achieve this goal, this paper explores two protocols with widespread practical application, namely domain generalization (DG) and unsupervised domain adaptation (UDA):
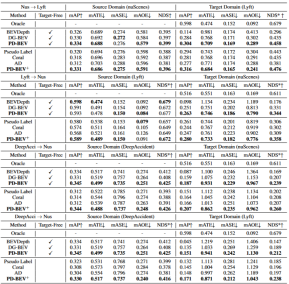
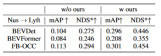
Domain generalization (DG) of BEV detection:Train a BEV detection algorithm in an existing data set (source domain) to improve the detection performance in an unknown data set (target domain). For example, training a BEV detection model in a specific vehicle or scenario can directly generalize to a variety of different vehicles and scenarios. Unsupervised domain adaptation (UDA) for BEV detection: Train a BEV detection algorithm on an existing data set (source domain), and use unlabeled data in the target domain to improve detection performance. For example, in a new vehicle or city, just collecting some unsupervised data can improve the performance of the model in the new vehicle and new environment. It is worth mentioning that the only difference between DG and UDA is whether unlabeled data of the target domain can be utilized. In order to detect the unknown L=[x,y,z] of the object, most BEV detection will have two key parts (1) acquisition Image features from different viewing angles; (2) Fuse these image features into the BEV space and obtain the final prediction result: The above formula describes that domain deviation may originate from the feature extraction stage or the BEV fusion stage. Then this article pushed forward in the appendix, and obtained the viewing angle deviation of the final 3D prediction result projected to the 2D result: where k_u, b_u, k_v and b_v are related to the domain offset of the BEV encoder, d(u,v) is the final predicted depth information of the model. c_u and c_v represent the coordinates of the camera's optical center on the uv image plane. The above equation provides several important corollaries: (1) The existence of final position offset will lead to perspective bias, which shows that optimizing perspective bias can help alleviate domain offset. (2) Even the position of the point on the camera's optical center ray on the single-view imaging plane will shift. Intuitively, domain shift changes the position of BEV features, which is overfitting due to limited training data viewpoints and camera parameters. To alleviate this problem, it is crucial to re-render new view images from BEV features, thereby enabling the network to learn view- and environment-independent features. In view of this, this research aims to solve the perspective deviation related to different rendering viewpoints to improve the generalization ability of the model PD-BEV in total It is divided into three parts: semantic rendering, source domain debiasing and target domain debiasing as shown in Figure 1. Semantic rendering explains how to establish the perspective relationship between 2D and 3D through BEV features. Source domain debiasing describes how to improve model generalization capabilities through semantic rendering in the source domain. Target domain debiasing describes the use of unlabeled data in the target domain to improve model generalization capabilities through semantic rendering. Since many algorithms will compress the BEV volume into 2D features, we first use the BEV decoder to BEV features are converted into a volume: The above formula actually improves the BEV plane and adds a height dimension. Then the internal and external parameters of the camera can be sampled in this Volume to become a 2D feature map, and then the 2D feature map and the internal and external parameters of the camera are sent to a RenderNet to predict the heatmap and object properties of the corresponding perspective. Through such operations similar to Nerf, a bridge between 2D and 3D can be established. To improve the generalization performance of the model, there are several key points that need to be improved in the source domain. First, the 3D box of the source domain can be utilized to monitor the heatmap and properties of the newly rendered view to reduce perspective bias. Secondly, normalized depth information can be used to help image encoders better learn geometric information. These improvements will help improve the generalization performance of the model Perspective semantic supervision: Based on semantic rendering, heatmaps and attributes are rendered from different perspectives (output of RenderNet). At the same time, a camera's internal and external parameters are randomly sampled, and the object's box is projected from the 3D coordinates into the two-dimensional camera plane using these internal and external parameters. Then use Focal loss and L1 loss to constrain the projected 2Dbox and rendering results: Through this operation, overfitting of internal and external parameters of the camera can be reduced and the robustness to new perspectives can be improved. . It is worth mentioning that this paper converts supervised learning from RGB images to heat maps of object centers to avoid the shortcomings of the lack of new perspective RGB supervision in the field of unmanned driving Geometry Supervision:Providing clear depth information can effectively improve the performance of multi-camera 3D object detection. However, the depth of network predictions tends to overfit the intrinsic parameters. Therefore, this paper draws on a virtual depth method: where BCE() represents the binary cross-entropy loss, and D_{pre} represents the prediction depth of DepthNet. f_u and f_v are the u and v focal lengths of the image plane respectively, and U is a constant. It is worth noting that the depth here is the foreground depth information provided by using 3D boxes rather than point clouds. By doing this, DepthNet is more likely to focus on the depth of foreground objects. Finally, the virtual depth is converted back to the actual depth when the semantic features are lifted to the BEV plane using the actual depth information. There is no annotation in the target domain, so 3D box supervision cannot be used to improve the generalization ability of the model. So this paper explains that 2D detection results are more robust than 3D results. Therefore, this paper uses the 2D pre-trained detector in the source domain as the supervision of the rendered perspective, and also uses the pseudo-label mechanism: This operation can effectively utilize accurate 2D detection to correct the foreground target position in BEV space, which is an unsupervised regularization of the target domain. In order to further enhance the correction ability of 2D prediction, a pseudo method is used to enhance the confidence of the predicted heat map. This paper provides mathematical proofs in 3.2 and supplementary materials to explain the cause of 2D projection errors in 3D results. It also explains why bias can be removed in this way. For details, please refer to the original paper. Although some networks have been added in this article to aid training, these networks are not necessary during inference. In other words, our method is applicable to the situation where most BEV detection methods learn perspective-invariant features. To test the effectiveness of our framework, we choose to use BEVDepth for evaluation. The original loss of BEVDepth is used on the source domain as the main 3D detection supervision. In short, the final loss of the algorithm is: Table 1 shows the performance of different methods in domain generalization (DG) and unsupervised domain adaptation (UDA) ) Comparison of effects under the agreement. Among them, Target-Free represents the DG protocol, and Pseudo Label, Coral and AD are some common UDA methods. As can be seen from the graph, these methods all achieve significant improvements in the target domain. This suggests that semantic rendering serves as a bridge to help learn perspective-invariant features against domain shifts. Furthermore, these methods do not sacrifice the performance of the source domain and even provide some improvements in most cases. It should be mentioned in particular that DeepAccident is developed based on the Carla virtual engine. After training on DeepAccident, the algorithm has achieved satisfactory generalization capabilities. In addition, other BEV detection methods have been tested, but their generalization performance is very poor without special design. In order to further verify the ability to utilize unsupervised data sets in the target domain, a UDA benchmark was also established and UDA methods (including Pseudo Label, Coral and AD) were applied on DG-BEV. Experiments show that these methods have significant performance improvements. Implicit rendering makes full use of 2D detectors with better generalization performance to correct the false geometric information of 3D detectors. Furthermore, it is found that most algorithms tend to degrade the performance of the source domain, while our method is relatively mild. It is worth mentioning that AD and Coral show significant improvements when moving from virtual to real datasets, but show performance degradation in real tests. This is because these two algorithms are designed to handle style changes, but in scenes with small style changes, they may destroy semantic information. As for the Pseudo Label algorithm, it can improve the generalization performance of the model by increasing the confidence in some relatively good target domains, but blindly increasing the confidence in the target domain will actually make the model worse. The experimental results prove that the algorithm in this paper has achieved significant performance improvement in DG and UDA. The ablation experimental results on the three key components are shown in Table 2: 2D detection Device pre-training (DPT), source domain debiasing (SDB) and target domain debiasing (TDB). The experimental results show that each component has achieved improvements, among which SDB and TDB show relatively significant effects Table 3 shows the algorithm that can be migrated to BEVFormer and FB- On the OCC algorithm. Because this algorithm only requires additional operations on image features and BEV features, it can improve algorithms with BEV features. Figure 5 shows the detected unlabeled objects. The first row is the 3D box of the label, and the second row is the detection result of the algorithm. Blue boxes indicate that the algorithm can detect some unlabeled boxes. This shows that the method can even detect unlabeled samples in the target domain, such as vehicles that are too far away or in buildings on both sides of the street. This paper proposes a general multi-camera 3D object detection framework based on perspective depolarization, which can solve the object detection problem in unknown fields. The framework achieves consistent and accurate detection by projecting 3D detection results onto a 2D camera plane and correcting perspective bias. In addition, the framework also introduces a perspective debiasing strategy to enhance the robustness of the model by rendering images from different perspectives. Experimental results show that this method achieves significant performance improvements in domain generalization and unsupervised domain adaptation. In addition, this method can also be trained on virtual data sets without the need for real scene annotation, which provides convenience for real-time applications and large-scale deployment. These highlights demonstrate the method's challenges and potential in solving multi-camera 3D object detection. This paper attempts to use Nerf's ideas to improve the generalization ability of BEV, and can also use labeled source domain data and unlabeled target domain data. In addition, the experimental paradigm of Sim2Real was tried, which has potential value for autonomous driving closed loop. There are very good results from both qualitative and quantitative results, and the open source code is worth a look Original link: https://mp.weixin.qq.com/ s/GRLu_JW6qZ_nQ9sLiE0p2gViewing angle deviation definition
Detailed explanation of PD-BEV algorithm
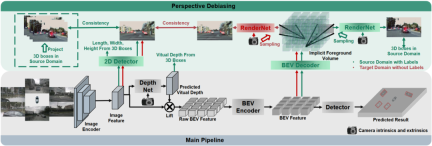
Semantic Rendering
Source domain debiasing
Debiasing the target domain
Overall Supervision
Cross-domain experimental results
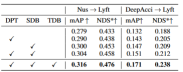
Summary

The above is the detailed content of NeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2Real. For more information, please follow other related articles on the PHP Chinese website!

 Cooking Up Innovation: How Artificial Intelligence Is Transforming Food ServiceApr 12, 2025 pm 12:09 PM
Cooking Up Innovation: How Artificial Intelligence Is Transforming Food ServiceApr 12, 2025 pm 12:09 PMAI Augmenting Food Preparation While still in nascent use, AI systems are being increasingly used in food preparation. AI-driven robots are used in kitchens to automate food preparation tasks, such as flipping burgers, making pizzas, or assembling sa
 Comprehensive Guide on Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PM
Comprehensive Guide on Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PMIntroduction Understanding the namespaces, scopes, and behavior of variables in Python functions is crucial for writing efficiently and avoiding runtime errors or exceptions. In this article, we’ll delve into various asp
 A Comprehensive Guide to Vision Language Models (VLMs)Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)Apr 12, 2025 am 11:58 AMIntroduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 MediaTek Boosts Premium Lineup With Kompanio Ultra And Dimensity 9400Apr 12, 2025 am 11:52 AM
MediaTek Boosts Premium Lineup With Kompanio Ultra And Dimensity 9400Apr 12, 2025 am 11:52 AMContinuing the product cadence, this month MediaTek has made a series of announcements, including the new Kompanio Ultra and Dimensity 9400 . These products fill in the more traditional parts of MediaTek’s business, which include chips for smartphone
 This Week In AI: Walmart Sets Fashion Trends Before They Ever HappenApr 12, 2025 am 11:51 AM
This Week In AI: Walmart Sets Fashion Trends Before They Ever HappenApr 12, 2025 am 11:51 AM#1 Google launched Agent2Agent The Story: It’s Monday morning. As an AI-powered recruiter you work smarter, not harder. You log into your company’s dashboard on your phone. It tells you three critical roles have been sourced, vetted, and scheduled fo
 Generative AI Meets PsychobabbleApr 12, 2025 am 11:50 AM
Generative AI Meets PsychobabbleApr 12, 2025 am 11:50 AMI would guess that you must be. We all seem to know that psychobabble consists of assorted chatter that mixes various psychological terminology and often ends up being either incomprehensible or completely nonsensical. All you need to do to spew fo
 The Prototype: Scientists Turn Paper Into PlasticApr 12, 2025 am 11:49 AM
The Prototype: Scientists Turn Paper Into PlasticApr 12, 2025 am 11:49 AMOnly 9.5% of plastics manufactured in 2022 were made from recycled materials, according to a new study published this week. Meanwhile, plastic continues to pile up in landfills–and ecosystems–around the world. But help is on the way. A team of engin
 The Rise Of The AI Analyst: Why This Could Be The Most Important Job In The AI RevolutionApr 12, 2025 am 11:41 AM
The Rise Of The AI Analyst: Why This Could Be The Most Important Job In The AI RevolutionApr 12, 2025 am 11:41 AMMy recent conversation with Andy MacMillan, CEO of leading enterprise analytics platform Alteryx, highlighted this critical yet underappreciated role in the AI revolution. As MacMillan explains, the gap between raw business data and AI-ready informat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

