
 Technology peripheralsAINeurIPS23 | 'Brain Reading' decodes brain activity and reconstructs the visual world
Technology peripheralsAINeurIPS23 | 'Brain Reading' decodes brain activity and reconstructs the visual world
In this NeurIPS23 paper, researchers from the University of Leuven, the National University of Singapore, and the Institute of Automation of the Chinese Academy of Sciences proposed a visual "brain reading technology" that can learn from human brain activity. High resolution resolution of the image seen by the human eye.
In the field of cognitive neuroscience, people realize that human perception is not only affected by objective stimuli, but also deeply affected by past experiences. These factors work together to create complex activity in the brain. Therefore, decoding visual information from brain activity becomes an important task. Among them, functional magnetic resonance imaging (fMRI), as an efficient non-invasive technology, plays a key role in recovering and analyzing visual information, especially image categories
However, due to the noise of fMRI signals Due to the complexity of the characteristics and visual representation of the brain, this task faces considerable challenges. To address this problem, this paper proposes a two-stage fMRI representation learning framework, which aims to identify and remove noise in brain activity, and focuses on parsing neural activation patterns that are crucial for visual reconstruction, successfully reconstructing high-level images from brain activity. resolution and semantically accurate images.

Paper link: https://arxiv.org/abs/2305.17214
Project link: https://github.com/soinx0629/vis_dec_neurips/
The method proposed in the paper is based on dual contrast learning, cross-modal information intersection and diffusion models. It has achieved nearly 40% improvement in evaluation indicators on relevant fMRI data sets compared to the previous best models. In generating images Compared with existing methods, the quality, readability and semantic relevance have been improved perceptibly by the naked eye. This work helps to understand the visual perception mechanism of the human brain and is beneficial to promoting research on visual brain-computer interface technology. The relevant codes have been open source.
Although functional magnetic resonance imaging (fMRI) is widely used to analyze neural responses, accurately reconstructing visual images from its data remains challenging, mainly because fMRI data contain noise from multiple sources, which may obscure Neural activation mode, increasing the difficulty of decoding. In addition, the neural response process triggered by visual stimulation is complex and multi-stage, making the fMRI signal present a nonlinear complex superposition that is difficult to reverse and decode.
Traditional neural decoding methods, such as ridge regression, although used to associate fMRI signals with corresponding stimuli, often fail to effectively capture the nonlinear relationship between stimuli and neural responses. Recently, deep learning techniques, such as generative adversarial networks (GANs) and latent diffusion models (LDMs), have been adopted to model this complex relationship more accurately. However, isolating vision-related brain activity from noise and accurately decoding it remains one of the main challenges in the field.
To address these challenges, this work proposes a two-stage fMRI representation learning framework, which can effectively identify and remove noise in brain activities and focus on parsing neural activation patterns that are critical for visual reconstruction. . This method generates high-resolution and semantically accurate images with a Top-1 accuracy of 39.34% for 50 categories, exceeding the existing state-of-the-art technology.
A method overview is a brief description of a series of steps or processes. It is used to explain how to achieve a specific goal or complete a specific task. The purpose of a method overview is to provide the reader or user with an overall understanding of the entire process so that they can better understand and follow the steps within it. In a method overview, you usually include the sequence of steps, materials or tools needed, and problems or challenges that may be encountered. By describing the method overview clearly and concisely, the reader or user can more easily understand and successfully complete the required task
fMRI Representation Learning (FRL)

First stage: Pre-training dual contrast mask autoencoder (DC-MAE)
In order to distinguish shared brain activity patterns and individual noise among different groups of people, this paper introduces DC-MAE technology to pre-train fMRI representations using unlabeled data. DC-MAE consists of an encoder  and a decoder
and a decoder  , where
, where  takes the masked fMRI signal as input and
takes the masked fMRI signal as input and  is trained to predict the unmasked fMRI signal. The so-called “double contrast” means that the model optimizes the contrast loss in fMRI representation learning and participates in two different contrast processes.
is trained to predict the unmasked fMRI signal. The so-called “double contrast” means that the model optimizes the contrast loss in fMRI representation learning and participates in two different contrast processes.
In the first stage of contrastive learning, the samples  in each batch containing n fMRI samples v are randomly masked twice, generating two different masked versions
in each batch containing n fMRI samples v are randomly masked twice, generating two different masked versions  and
and  , as a positive sample pair for comparison. Subsequently, 1D convolutional layers convert these two versions into embedded representations, which are fed into the fMRI encoder respectively. The decoder receives these encoded latent representations and produces predictions
, as a positive sample pair for comparison. Subsequently, 1D convolutional layers convert these two versions into embedded representations, which are fed into the fMRI encoder respectively. The decoder receives these encoded latent representations and produces predictions  and
and  . Optimize the model through the first contrast loss calculated by the InfoNCE loss function, that is, the cross-contrast loss:
. Optimize the model through the first contrast loss calculated by the InfoNCE loss function, that is, the cross-contrast loss:

In the second stage of contrastive learning, each unmasked original image  and its corresponding masked image
and its corresponding masked image  form a pair of natural positive samples. The
form a pair of natural positive samples. The  here represents the image predicted by the decoder . The second contrast loss, which is the self-contrast loss, is calculated according to the following formula:
here represents the image predicted by the decoder . The second contrast loss, which is the self-contrast loss, is calculated according to the following formula:

Optimizing the self-contrast loss can achieve occlusion reconstruction. Whether it is
can achieve occlusion reconstruction. Whether it is  or
or  , the negative sample
, the negative sample  comes from the same batch of instances.
comes from the same batch of instances.  and are jointly optimized as follows:
and are jointly optimized as follows:  , where the hyperparameters
, where the hyperparameters  and
and  are used to adjust the weight of each loss item.
are used to adjust the weight of each loss item.
Phase 2: Adjustment using cross-modal guidance
Given the low signal-to-noise ratio and highly convolutional nature of fMRI recordings , it is crucial for fMRI feature learners to focus on brain activation patterns that are most relevant to visual processing and most informative for reconstruction
After the first stage of pre-training, the fMRI autoencoder is adjusted with image assistance to achieve fMRI reconstruction, and the second stage also follows this process. Specifically, a sample  and its corresponding fMRI recorded neural response
and its corresponding fMRI recorded neural response  are selected from a batch of n samples.
are selected from a batch of n samples.  and
and  are transformed into
are transformed into  and
and  respectively after blocking and random masking processing, and then are input to the image encoder
respectively after blocking and random masking processing, and then are input to the image encoder  and fMRI encoder respectively to generate
and fMRI encoder respectively to generate  and
and  . To reconstruct fMRI, use the cross attention module to merge
. To reconstruct fMRI, use the cross attention module to merge  and
and  :
:

W and b represent the weight and bias of the corresponding linear layer respectively.  is the scaling factor,
is the scaling factor,  is the dimension of the key vector. CA is the abbreviation of cross-attention. After
is the dimension of the key vector. CA is the abbreviation of cross-attention. After  is added to
is added to  , it is input into the fMRI decoder to reconstruct , and
, it is input into the fMRI decoder to reconstruct , and  is obtained:
is obtained:

The image autoencoder is also performed Similar calculations, the output  of the image encoder
of the image encoder  is merged with the output of
is merged with the output of  through the cross attention module , and then used to decode the image
through the cross attention module , and then used to decode the image  , resulting in
, resulting in  :
: 
fMRI and image autoencoders are trained together by optimizing the following loss function:

When generating images, a latent diffusion model (LDM) can be used

After completing the first and second stages of FRL training, use the fMRI feature learner's encoder to drive a latent diffusion model (LDM) to generate images from brain activity. As shown in the figure, the diffusion model includes a forward diffusion process and a reverse denoising process. The forward process gradually degrades the image into normal Gaussian noise by gradually introducing Gaussian noise with varying variance.
This study generates images by extracting visual knowledge from a pre-trained label-to-image latent diffusion model (LDM) and using fMRI data as a condition. A cross-attention mechanism is employed here to incorporate fMRI information into LDM, following recommendations from stable diffusion studies. In order to strengthen the role of conditional information, the methods of cross attention and time step conditioning are used here. In the training phase, the VQGAN encoder and the fMRI encoder trained by the first and second stages of FRL are used to process the image u and fMRI v, and the fMRI encoder is fine-tuned while keeping the LDM unchanged. The loss The function is:
and the fMRI encoder trained by the first and second stages of FRL are used to process the image u and fMRI v, and the fMRI encoder is fine-tuned while keeping the LDM unchanged. The loss The function is: 
where,  is the noise plan of the diffusion model. In the inference phase, the process starts with standard Gaussian noise at time step T, and the LDM sequentially follows the inverse process to gradually remove the noise of the hidden representation, conditioned on the given fMRI information. When time step zero is reached, the hidden representation is converted into an image using the VQGAN decoder.
is the noise plan of the diffusion model. In the inference phase, the process starts with standard Gaussian noise at time step T, and the LDM sequentially follows the inverse process to gradually remove the noise of the hidden representation, conditioned on the given fMRI information. When time step zero is reached, the hidden representation is converted into an image using the VQGAN decoder. 
Experiment
Reconstruction results
 ##By working with DC-LDM, IC- Comparison of previous studies such as GAN and SS-AE, and evaluation on the GOD and BOLD5000 data sets show that the model proposed in this study significantly exceeds these models in accuracy, which is improved compared to DC-LDM and IC-GAN respectively. 39.34% and 66.7%
##By working with DC-LDM, IC- Comparison of previous studies such as GAN and SS-AE, and evaluation on the GOD and BOLD5000 data sets show that the model proposed in this study significantly exceeds these models in accuracy, which is improved compared to DC-LDM and IC-GAN respectively. 39.34% and 66.7%
 Evaluation on the other four subjects of the GOD dataset shows that even when DC-LDM is allowed to adjust on the test set In this case, the model proposed in this study is also significantly better than DC-LDM in the Top-1 classification accuracy of 50 ways, proving the reliability and superiority of the proposed model in reconstructing brain activity of different subjects.
Evaluation on the other four subjects of the GOD dataset shows that even when DC-LDM is allowed to adjust on the test set In this case, the model proposed in this study is also significantly better than DC-LDM in the Top-1 classification accuracy of 50 ways, proving the reliability and superiority of the proposed model in reconstructing brain activity of different subjects.
The research results show that using the proposed fMRI representation learning framework and pre-trained LDM can better reconstruct the brain's visual activity, far exceeding the current baseline level. This work helps further explore the potential of neural decoding models
The above is the detailed content of NeurIPS23 | 'Brain Reading' decodes brain activity and reconstructs the visual world. For more information, please follow other related articles on the PHP Chinese website!

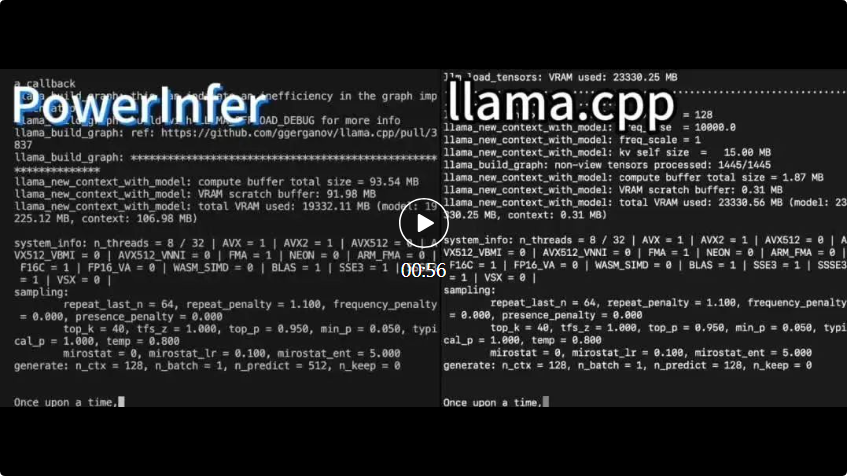 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
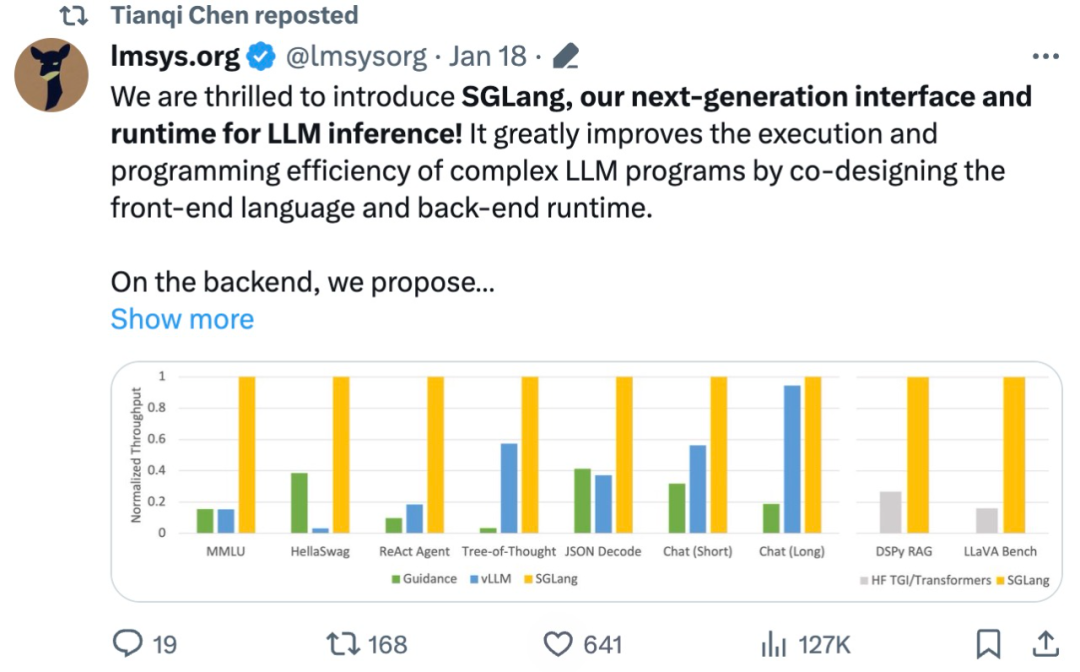 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM
何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM去噪扩散模型(DDM)是目前广泛应用于图像生成的一种方法。最近,XinleiChen、ZhuangLiu、谢赛宁和何恺明四人团队对DDM进行了解构研究。通过逐步剥离其组件,他们发现DDM的生成能力逐渐下降,但表征学习能力仍然保持一定水平。这说明DDM中的某些组件对于表征学习的作用可能并不重要。针对当前计算机视觉等领域的生成模型,去噪被认为是一种核心方法。这类方法通常被称为去噪扩散模型(DDM),通过学习一个去噪自动编码器(DAE),能够通过扩散过程有效地消除多个层级的噪声。这些方法实现了出色的图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 Mac version
God-level code editing software (SublimeText3)

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver CS6
Visual web development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

