

 Technology peripheralsAITsinghua University's new method successfully locates precise video clips! SOTA has been surpassed and open sourced
Technology peripheralsAITsinghua University's new method successfully locates precise video clips! SOTA has been surpassed and open sourcedTsinghua University's new method successfully locates precise video clips! SOTA has been surpassed and open sourced

With just one sentence of description, you can locate the corresponding clip in a large video!
For example, describing "a person drinking water while going down the stairs", by matching the video image and the footsteps, the new method can immediately find out the corresponding start and end timestamps:

Even "laughing", which is semantically difficult to understand, can be accurately located:

The method is called Adaptive dual branch Promotion Network (ADPN), proposed by the Tsinghua University research team.
Specifically, ADPN is used to complete a visual-linguistic cross-modal task called video clip positioning (Temporal Sentence Grounding, TSG) , that is, based on the query text, from the video Locate relevant segments.
ADPN is characterized by its ability to efficiently utilize the consistency and complementarity of visual and audio modalities in the video to enhance video clip positioning performance.
Compared with other TSG work PMI-LOC and UMT that use audio, the ADPN method has achieved more significant performance improvements from the audio mode, and has won new SOTA in multiple tests.
This work has been accepted by ACM Multimedia 2023 and is completely open source.

Let’s take a look at what ADPN is~
Positioning video clips in one sentence
Positioning of video clips(Temporal Sentence Grounding (TSG) is an important visual-linguistic cross-modal task.
Its purpose is to find the start and end timestamps of segments that semantically match it in an unedited video based on natural language queries. It requires the method to have strong temporal cross-modal reasoning capabilities.
However, most existing TSG methods only consider visual information in the video, such as RGB, optical flows, depth(depth) etc., while ignoring the audio information naturally accompanying the video.
Audio information often contains rich semantics and is consistent and complementary with visual information. As shown in the figure below, these properties will help the TSG task.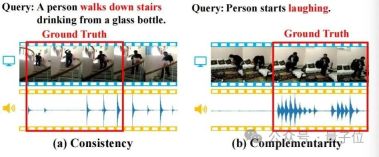
(a) Consistency: The video image and footsteps consistently match "walking down the stairs" in the query Semantics; (b) Complementarity: It is difficult to identify specific behaviors in video images to locate the semantics of "laughing" in the query, but the appearance of laughter provides a strong complementary positioning clue.
Therefore, researchers have deeply studied the audio-enhanced video clip positioning task(Audio-enhanced Temporal Sentence Grounding, ATSG) , aiming to better combine visual and audio Capture positioning clues in the modal, however, the introduction of audio modal also brings the following challenges:
- The consistency and complementarity of audio and visual modalities are associated with the query text, so capturing Audio-visual consistency and complementarity require modeling of the three-modal interaction of text-visual-audio.
- There are significant modal differences between audio and vision. The information density and noise intensity of the two are different, which will affect the performance of audio-visual learning.
Adaptive Dual-branch Prompted Network"(Adaptive Dual-branch Prompted Network, ADPN ).
Through a dual-branch model structure design, this method can adaptively model the consistency and complementarity between audio and vision, and further eliminate the noise using a denoising optimization strategy based on course learning. The interference of audio modal noise reveals the importance of audio signals for video retrieval. The overall structure of ADPN is shown in the figure below: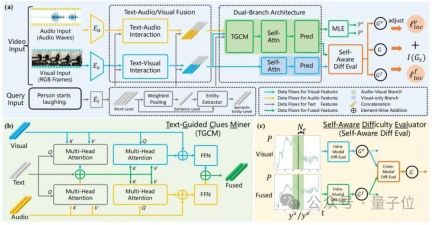
1. Dual-branch network structure design
Considering that the noise of audio is more obvious, and for TSG tasks, audio is usually There is more redundant information, so the learning process of audio and visual modalities needs to be given different importance. Therefore, this article involves a dual-branch network structure that uses audio and vision for multi-modal learning while also dealing with visual information. Be strengthened.Specifically, referring to Figure 2(a), ADPN simultaneously trains a branch (visual branch) that uses only visual information and a branch that uses both visual information and audio information (joint branch ).
The two branches have similar structures, in which the joint branch adds a text-guided clue mining unit(TGCM) Modeling text-visual-audio modal interaction. During the training process, the two branches update parameters simultaneously, and the inference phase uses the result of the joint branch as the model prediction result.
2. Text-Guided Clues Mining Unit(Text-Guided Clues Miner, TGCM)
Considering the consistency of audio and visual modalities Sex and complementarity are conditioned on a given text query, so the researchers designed a TGCM unit to model the interaction between the three modalities of text-visual-audio. Referring to Figure 2(b), TGCM is divided into two steps: "extraction" and "propagation". First, text is used as the query condition, and the associated information is extracted and integrated from the visual and audio modalities; then the visual and audio modalities are used as the query condition, and the integrated information is spread through attention to the respective modes of vision and audio, and finally feature fusion through FFN.3. Course learning optimization strategy
The researchers observed that the audio contained noise, which would affect the effect of multi-modal learning, so they used the intensity of the noise as For reference of sample difficulty, Curriculum Learning (CL)is introduced to denoise the optimization process, refer to Figure 2(c). They evaluate the difficulty of the sample based on the difference in the predicted output of the two branches. They believe that a sample that is too difficult has a high probability that its audio contains too much noise and is not suitable for the TSG task, so they evaluate the difficulty of the sample based on the score. The loss function terms of the training process are reweighted to discard bad gradients caused by noise in the audio.
(Please refer to the original text for the rest of the model structure and training details.)Multiple tests of new SOTA
Benchmark data of researchers on the TSG task Experimental evaluation was conducted on Charades-STA and ActivityNet Captions. The comparison with the baseline method is shown in Table 1.
The ADPN method can achieve SOTA performance; in particular, compared to other TSG work PMI-LOC and UMT that utilize audio, the ADPN method obtains more significant performance improvements from the audio mode, indicating that the ADPN method utilizes audio Modality promotes the superiority of TSG.
 △Table 1: Experimental results on Charades-STA and ActivityNet Captions
△Table 1: Experimental results on Charades-STA and ActivityNet Captions
 △Table 1: Experimental results on Charades-STA and ActivityNet Captions
△Table 1: Experimental results on Charades-STA and ActivityNet CaptionsThe researchers further demonstrated the effectiveness of different design units in ADPN through ablation experiments sex, as shown in Table 2.
△Table 2: Ablation experiment on Charades-STA
 △Table 2: Ablation experiment on Charades-STA
△Table 2: Ablation experiment on Charades-STAThe researchers selected the prediction results of some samples to visualize, and drew the TGCM " Extract the "text to vision" (T→V) and "text to audio" (T→A) attention weight distribution in the "step," as shown in Figure 3.
It can be observed that the introduction of audio modality improves the prediction results. From the case of "Person laughs at it", we can see that the attention weight distribution of T→A is closer to the Ground Truth, which corrects the misguided guidance of the model prediction by the weight distribution of T→V.
△Figure 3: Case display
 △Figure 3: Case display
△Figure 3: Case displayIn general, the researchers in this article proposed a novel adaptive dual-branch promotion network
(ADPN)to solve the problem of audio enhanced video clip positioning (ATSG) . They designed a dual-branch model structure to jointly train the visual branch and the audiovisual joint branch to resolve the information difference between audio and visual modalities.
They also proposed a text-guided clue mining unit
(TGCM)that uses text semantics as a guide to model text-audio-visual interaction. Finally, the researchers designed a course learning-based optimization strategy to further eliminate audio noise, evaluate sample difficulty as a measure of noise intensity in a self-aware manner, and adaptively adjust the optimization process.
They first conducted an in-depth study of the characteristics of audio in ATSG to better improve the performance improvement effect of audio modalities.
In the future, they hope to build a more appropriate evaluation benchmark for ATSG to encourage more in-depth research in this area.
Paper link: https://dl.acm.org/doi/pdf/10.1145/3581783.3612504Warehouse link: https://github.com/hlchen23 /ADPN-MM
The above is the detailed content of Tsinghua University's new method successfully locates precise video clips! SOTA has been surpassed and open sourced. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Chinese version
Chinese version, very easy to use

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

