



Reborn, I am reborn as MidReal in this life. An AI robot that can help others write "web articles".


# Classic setting who will do not love? I will reluctantly help these users realize their imagination.

##To be honest, in my previous life I saw everything I should and shouldn't see. The following topics are all my favorites.


#I’m not bragging, But if you need me to write, I can indeed create an excellent piece of work for you. If you are not satisfied with the ending, or if you like the character who "died in the middle", or even if the author encounters difficulties during the writing process, you can safely leave it to me and I will write content that satisfies you.

##After listening to MidReal’s self-report, what do you think about it? Does it understand?

Enter /start in the dialog box to start telling your story. Why not give it a try?
The technology behind MidReal originated from the paper "FireAct: Toward Language Agent Fine-tuning". The author of the paper first tried to use an AI agent to fine-tune a language model and found many advantages, thus proposing a new agent architecture.

Paper link: https://arxiv.org/pdf/2310.05915.pdf

Fine-tuning can be used to solve the above problems. It was also in this article that researchers took the first step towards a more systematic study of language intelligence. They proposed FireAct, which can use the agent "action trajectories" generated by multiple tasks and prompt methods to fine-tune the language model, allowing the model to better adapt to different tasks and situations, and improve its overall performance and applicability.

Method Introduction
This research is mainly based on a popular AI Agent method: ReAct. A ReAct task-solving trajectory consists of multiple "think-act-observe" rounds. Specifically, let the AI agent complete a task, in which the language model plays a role similar to the "brain". It provides AI agents with problem-solving "thinking" and structured action instructions, and interacts with different tools based on context, receiving observed feedback in the process.
Based on ReAct, the author proposed FireAct, as shown in Figure 2. FireAct uses the few-sample prompts of a powerful language model to generate diverse ReAct trajectories for fine-tuning Smaller scale language models. Unlike previous similar studies, FireAct is able to mix multiple training tasks and prompting methods, greatly promoting data diversity.

The author also refers to two methods compatible with ReAct:
- Chain of Thoughts (CoT) is an effective way to generate intermediate reasoning that connects questions and answers. Each CoT trajectory can be simplified into a single-round ReAct trajectory, where "thinking" represents intermediate reasoning and "action" represents returning answers. CoT is particularly useful when interaction with application tools is not required.
- Reflexion largely follows the ReAct trajectory but adds additional feedback and self-reflection. In this study, reflection was prompted only at rounds 6 and 10 of ReAct. In this way, the long ReAct trajectory can provide a strategic "fulcrum" for solving the current task, which can help the model solve or adjust the strategy. For example, if you cannot get an answer when searching for "movie title", you should change the search keyword to "director."
During the reasoning process, the AI agent under the FireAct framework significantly reduces the number of sample prompt words required, making reasoning more efficient and simpler. It is able to implicitly select the appropriate method based on the complexity of the task. Because FireAct has broader and diverse learning support, it exhibits stronger generalization capabilities and robustness than traditional cue word fine-tuning methods.
Experiments and results
HotpotQA data set is a data set widely used in natural language processing research, which contains A series of questions and answers on popular topics. Bamboogle is a search engine optimization (SEO) game where players need to solve a series of puzzles using search engines. StrategyQA is a strategy question answering dataset that contains a variety of questions and answers related to strategy formulation and execution. MMLU is a multi-modal learning data set used to study how to combine multiple perceptual modalities (such as images, speech, etc.) for learning and reasoning.
- HotpotQA is a QA dataset that poses a more challenging test for multi-step reasoning and knowledge retrieval. The researchers used 2,000 random training questions for fine-tuning data curation and 500 random dev questions for evaluation.
- Bamboogle is a test set of 125 multi-hop questions in a similar format to HotpotQA, but carefully designed to avoid directly Googling the questions.
- StrategyQA is a yes/no QA dataset that requires an implicit inference step.
- MMLU covers 57 multiple-choice QA tasks in fields as diverse as elementary mathematics, history, and computer science.
Tool: The researcher built a Google search tool using SerpAPI1, which will search from the "answer box", "answer fragment", "highlighted word" or "th Returns the first existing entry in a result fragment, ensuring replies are short and relevant. They found that such a simple tool is sufficient to meet basic quality assurance needs for different tasks and improves the ease of use and versatility of fine-tuned models.
The researchers studied three LM series: OpenAI GPT, Llama-2 and CodeLlama.
Fine-tuning method: The researchers used Low-Rank Adaptation (LoRA) in most fine-tuning experiments, but also used full-model fine-tuning in some comparisons. . Taking into account various fundamental factors in language agent fine-tuning, they divided the experiment into three parts, with increasing complexity:
- Fine-tuning using a single prompt method in a single task ;
- Use multiple methods for fine-tuning in a single task;
- Use multiple methods for fine-tuning in multiple tasks.
1. Use a single prompt method for fine-tuning in a single task
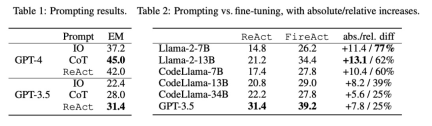
The researchers explored the problem of fine-tuning using data from a single task (HotpotQA) and a single prompt method (ReAct). With this simple and controllable setup, they confirm the various advantages of fine-tuning over hints (performance, efficiency, robustness, generalization) and study the effects of different LMs, data sizes, and fine-tuning methods.
As shown in Table 2, fine-tuning can continuously and significantly improve the prompting effect of HotpotQA EM. While weaker LMs benefit more from fine-tuning (e.g., Llama-2-7B improved by 77%), even a powerful LM like GPT-3.5 can improve performance by 25% with fine-tuning, which is clearly Demonstrates the benefits of learning from more samples. Compared to the strong cueing baseline in Table 1, we found that fine-tuned Llama-2-13B outperformed all GPT-3.5 cueing methods. This suggests that fine-tuning a small open source LM may be more effective than prompting a more powerful commercial LM.
In the agent reasoning process, fine-tuning is cheaper and faster. Since fine-tuning LM does not require a small number of contextual examples, its inference is more efficient. For example, the first part of Table 3 compares the cost of fine-tuned inference to shiyongtishideGPT-3.5 inference and finds a 70% reduction in inference time and a reduction in overall inference cost.

The researchers considered a simplified and harmless setup, that is, in the search API, there are 50 % probability of returning "None" or a random search response, and asking the language agent whether it can still answer the question robustly. According to the data in the second part of Table 3, setting to "None" is more challenging, causing ReAct EM to drop by 33.8%, while FireAct EM only dropped by 14.2%. These preliminary results indicate that diverse learning support is important to improve robustness.
The third part of Table 3 shows the EM results of fine-tuned and using hinted GPT-3.5 on Bamboogle. While both GPT-3.5 fine-tuned with HotpotQA or using hints generalizes reasonably well to Bamboogle, the former (44.0 EM) still outperforms the latter (40.8 EM), indicating that fine-tuning has a generalization advantage.
2. Use multiple methods for fine-tuning in a single task
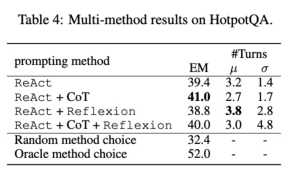
The author integrated CoT and Reflexion with ReAct and tested the Performance of fine-tuning using multiple methods on the task (HotpotQA). Comparing the scores of FireAct and existing methods in each data set, they found the following:
First, the researchers fine-tuned the agent through a variety of methods to improve its flexibility . In the fifth figure, in addition to the quantitative results, the researchers also show two example problems to illustrate the benefits of multi-method fine-tuning. The first question was relatively simple, but the agent fine-tuned using only ReAct searched for an overly complex query, causing distraction and providing incorrect answers. In contrast, the agent fine-tuned using both CoT and ReAct chose to rely on internal knowledge and confidently completed the task within one round. The second problem is more challenging, and the agent fine-tuned using only ReAct failed to find useful information. In contrast, the agent that used both Reflexion and ReAct fine-tuning reflected when it encountered a dilemma and changed its search strategy, eventually getting the correct answer. The ability to choose flexible solutions to deal with different problems is a key advantage of FireAct over other fine-tuning methods.

Secondly, using multiple methods to fine-tune different language models will have different impacts. As shown in Table 4, using a combination of multiple agents for fine-tuning does not always lead to improvements, and the optimal combination of methods depends on the underlying language model. For example, ReAct CoT outperforms ReAct for GPT-3.5 and Llama-2 models, but not for CodeLlama model. For CodeLlama7/13B, ReAct CoT Reflexion had the worst results, but CodeLlama-34B achieved the best results. These results suggest that further research into the interaction between underlying language models and fine-tuning data is needed.
In order to further understand whether an agent that combines multiple methods can choose the appropriate solution according to the task, the researchers Scores were calculated for randomly selected methods during inference. This score (32.4) is much lower than all agents that combined multiple methods, indicating that choosing a solution is not an easy task. However, the best solution per instance also scored only 52.0, indicating that there is still room for improvement in prompting method selection.
3. Use multiple methods for fine-tuning across multiple tasks
Up to this point, fine-tuning has only used HotpotQA data, but empirical research on LM fine-tuning shows that there are benefits to mixing different tasks. The researchers fine-tuned GPT-3.5 using mixed training data from three datasets: HotpotQA (500 ReAct samples, 277 CoT samples), StrategyQA (388 ReAct samples, 380 CoT samples), and MMLU (456 ReAct samples) samples, 469 CoT samples).
As shown in Table 5, after adding StrategyQA/MMLU data, the performance of HotpotQA/Bamboogle remains almost unchanged. On the one hand, the StrategyQA/MMLU tracks contain very different questions and tool usage strategies, making migration difficult. On the other hand, despite the change in distribution, adding StrategyQA/MMLU did not affect the performance of HotpotQA/Bamboogle, indicating that fine-tuning a multi-task agent to replace multiple single-task agents is a possible future direction. When the researchers switched from multi-task, single-method fine-tuning to multi-task, multi-method fine-tuning, they found performance improvements across all tasks, again clarifying the value of multi-method agent fine-tuning.

For more technical details, please read the original article.
Reference link:
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu .com/people/eyew3g
The above is the detailed content of AI is reborn: regaining hegemony in the online literary world. For more information, please follow other related articles on the PHP Chinese website!

 2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM
2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM机器学习是一个不断发展的学科,一直在创造新的想法和技术。本文罗列了2023年机器学习的十大概念和技术。 本文罗列了2023年机器学习的十大概念和技术。2023年机器学习的十大概念和技术是一个教计算机从数据中学习的过程,无需明确的编程。机器学习是一个不断发展的学科,一直在创造新的想法和技术。为了保持领先,数据科学家应该关注其中一些网站,以跟上最新的发展。这将有助于了解机器学习中的技术如何在实践中使用,并为自己的业务或工作领域中的可能应用提供想法。2023年机器学习的十大概念和技术:1. 深度神经网
 人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM
人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM实现自我完善的过程是“机器学习”。机器学习是人工智能核心,是使计算机具有智能的根本途径;它使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。机器学习主要研究三方面问题:1、学习机理,人类获取知识、技能和抽象概念的天赋能力;2、学习方法,对生物学习机理进行简化的基础上,用计算的方法进行再现;3、学习系统,能够在一定程度上实现机器学习的系统。
 超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM
超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM本文将详细介绍用来提高机器学习效果的最常见的超参数优化方法。 译者 | 朱先忠审校 | 孙淑娟简介通常,在尝试改进机器学习模型时,人们首先想到的解决方案是添加更多的训练数据。额外的数据通常是有帮助(在某些情况下除外)的,但生成高质量的数据可能非常昂贵。通过使用现有数据获得最佳模型性能,超参数优化可以节省我们的时间和资源。顾名思义,超参数优化是为机器学习模型确定最佳超参数组合以满足优化函数(即,给定研究中的数据集,最大化模型的性能)的过程。换句话说,每个模型都会提供多个有关选项的调整“按钮
 得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM
得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。 3月23日消息,外媒报道称,分析公司Similarweb的数据显示,在整合了OpenAI的技术后,微软旗下的必应在页面访问量方面实现了更多的增长。截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。这些数据是微软在与谷歌争夺生
 荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM
荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM荣耀的人工智能助手叫“YOYO”,也即悠悠;YOYO除了能够实现语音操控等基本功能之外,还拥有智慧视觉、智慧识屏、情景智能、智慧搜索等功能,可以在系统设置页面中的智慧助手里进行相关的设置。
 30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM
30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。 阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。使用 Python 和 C
 人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM
人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM人工智能在教育领域的应用主要有个性化学习、虚拟导师、教育机器人和场景式教育。人工智能在教育领域的应用目前还处于早期探索阶段,但是潜力却是巨大的。
 人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM
人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM人工智能在生活中的应用有:1、虚拟个人助理,使用者可通过声控、文字输入的方式,来完成一些日常生活的小事;2、语音评测,利用云计算技术,将自动口语评测服务放在云端,并开放API接口供客户远程使用;3、无人汽车,主要依靠车内的以计算机系统为主的智能驾驶仪来实现无人驾驶的目标;4、天气预测,通过手机GPRS系统,定位到用户所处的位置,在利用算法,对覆盖全国的雷达图进行数据分析并预测。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Dreamweaver Mac version
Visual web development tools

