
Home >Technology peripherals >AI >4090 Generator: Compared with the A100 platform, the token generation speed is only less than 18%, and the submission to the inference engine has won hot discussions
4090 Generator: Compared with the A100 platform, the token generation speed is only less than 18%, and the submission to the inference engine has won hot discussions

- 王林forward
- 2023-12-21 15:25:411964browse
PowerInfer improves the efficiency of running AI on consumer-grade hardware
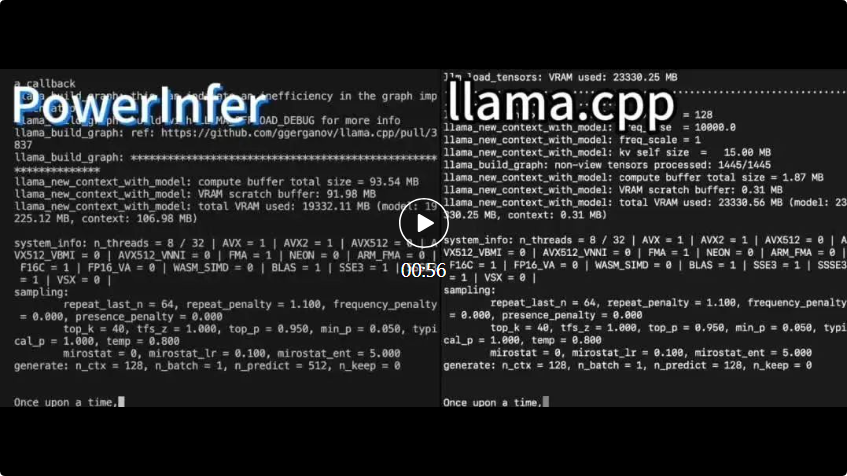 ## PowerInfer and llama.cpp both run on the same hardware and take full advantage of the VRAM on the RTX 4090.
## PowerInfer and llama.cpp both run on the same hardware and take full advantage of the VRAM on the RTX 4090. 
- Project link: https://github.com/SJTU-IPADS/PowerInfer
- Paper link: https://ipads.se.sjtu.edu.cn/_media/ publications/powerinfer-20231219.pdf
Faclon 40B, with support for Mistral-7B coming soon.
In one day, PowerInfer successfully obtained 2K stars
PowerInfer architecture
The key to PowerInfer design is to exploit the high degree of locality inherent in LLM inference, which is characterized by a power-law distribution in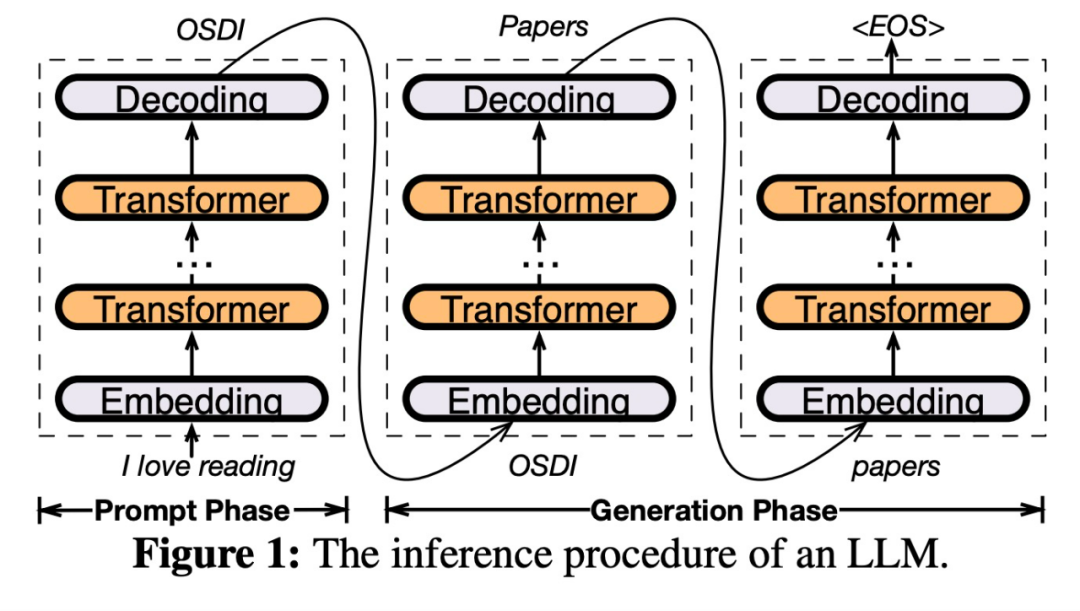
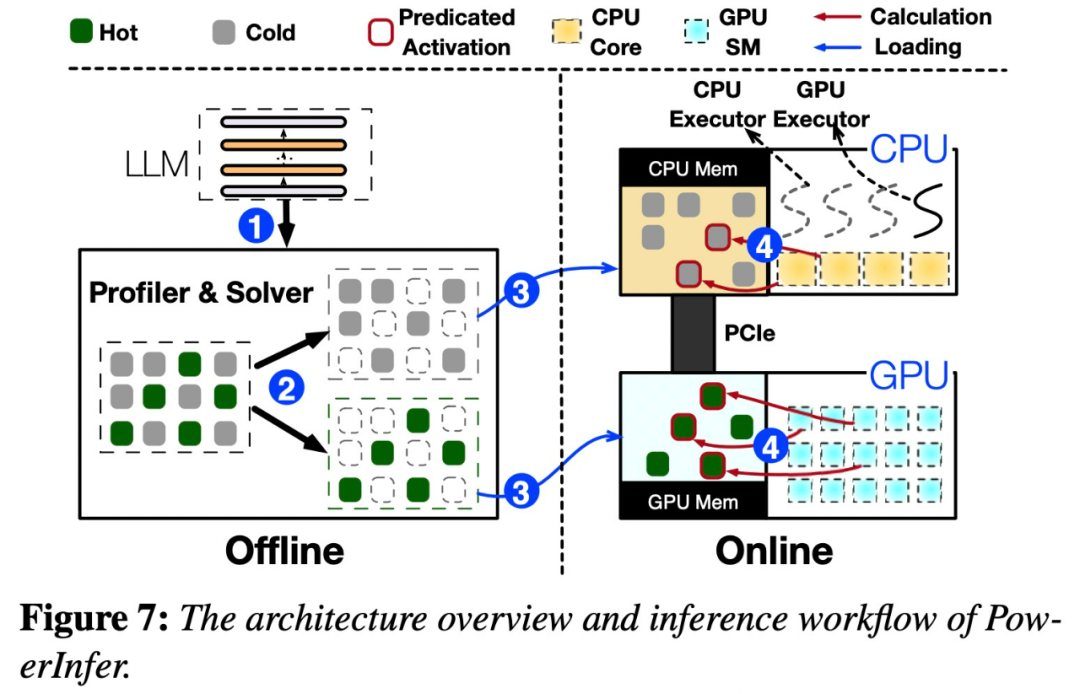
Once input is received, the predictor will identify neurons in the current layer that are likely to be activated. It should be noted that thermally activated neurons identified through offline statistical analysis may not be consistent with the actual activation behavior at runtime. For example, although neuron 7 is labeled as thermally activated, it is not actually so. The CPU and GPU then process those neurons that are already activated and ignore those that are not. The GPU is responsible for computing neurons 3 and 5, while the CPU handles neuron 4. When the calculation of neuron 4 is completed, its output will be sent to the GPU for result integration
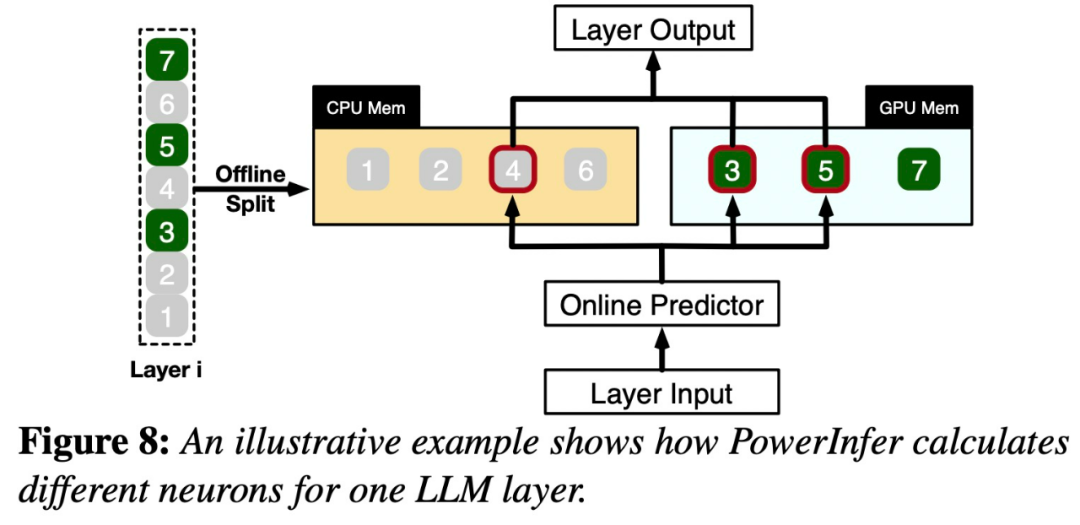
In order to rewrite the content without changing the original meaning, the language needs to be rewritten Written in Chinese. It is not necessary to appear the original sentence
The study was conducted using the OPT model with different parameters In order to rewrite the content without changing the original meaning, the language needs to be rewritten into Chinese. It is not necessary to present original sentences, parameters range from 6.7B to 175B, and Falcon (ReLU)-40B and LLaMA (ReGLU)-70B models are also included. It is worth noting that the size of the 175B parameter model is comparable to the GPT-3 model.
This article also compares PowerInfer with llama.cpp, a state-of-the-art native LLM inference framework. To facilitate comparison, this study also extended llama.cpp to support the OPT model
Considering that the focus of this article is on low-latency settings, the evaluation metric adopts the end-to-end generation speed in terms of the number of tokens generated per second. (tokens/s) for quantification
This study first compares the end-to-end inference performance of PowerInfer and llama.cpp with a batch size of 1
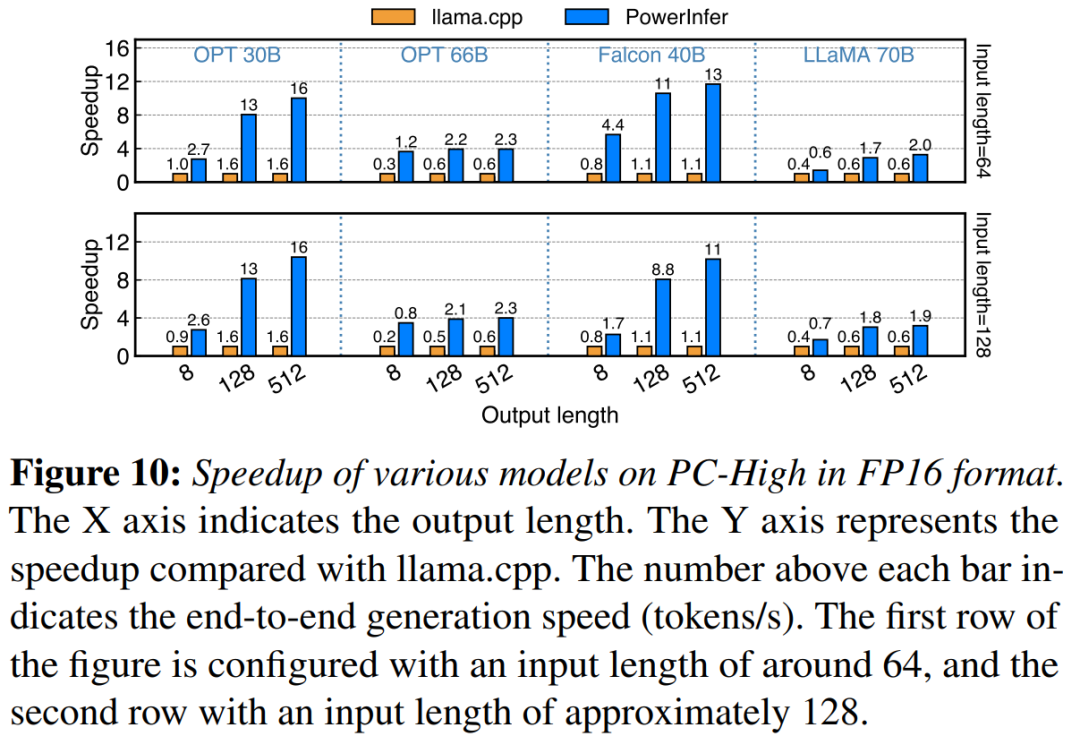
On a machine equipped with NVIDIA RTX 4090 On PC-High, Figure 10 shows the generation speed of various models and input and output configurations. On average, PowerInfer achieves a generation speed of 8.32 tokens/s, with a maximum of 16.06 tokens/s, which is significantly better than llama.cpp, 7.23 times higher than llama.cpp, and 11.69 times higher than Falcon-40B
As the number of output tokens increases, the performance advantages of PowerInfer become more obvious, because the generation phase plays a more important role in the overall inference time. At this stage, a small number of neurons are activated on both the CPU and GPU, which reduces unnecessary calculations compared to llama.cpp. For example, in the case of OPT-30B, only about 20% of the neurons are activated for each token generated, most of which are processed on the GPU, which is the benefit of PowerInfer neuron-aware reasoning
As shown in Figure 11, despite being on PC-Low, PowerInfer still achieved considerable performance enhancements, with an average speedup of 5.01x and a peak speedup of 7.06x. However, these improvements are smaller compared to PC-High, mostly due to PC-Low's 11GB GPU memory limit. This limit affects the number of neurons that can be assigned to the GPU, especially for models with approximately 30B parameters or more, resulting in greater reliance on the CPU to handle large numbers of activated neurons
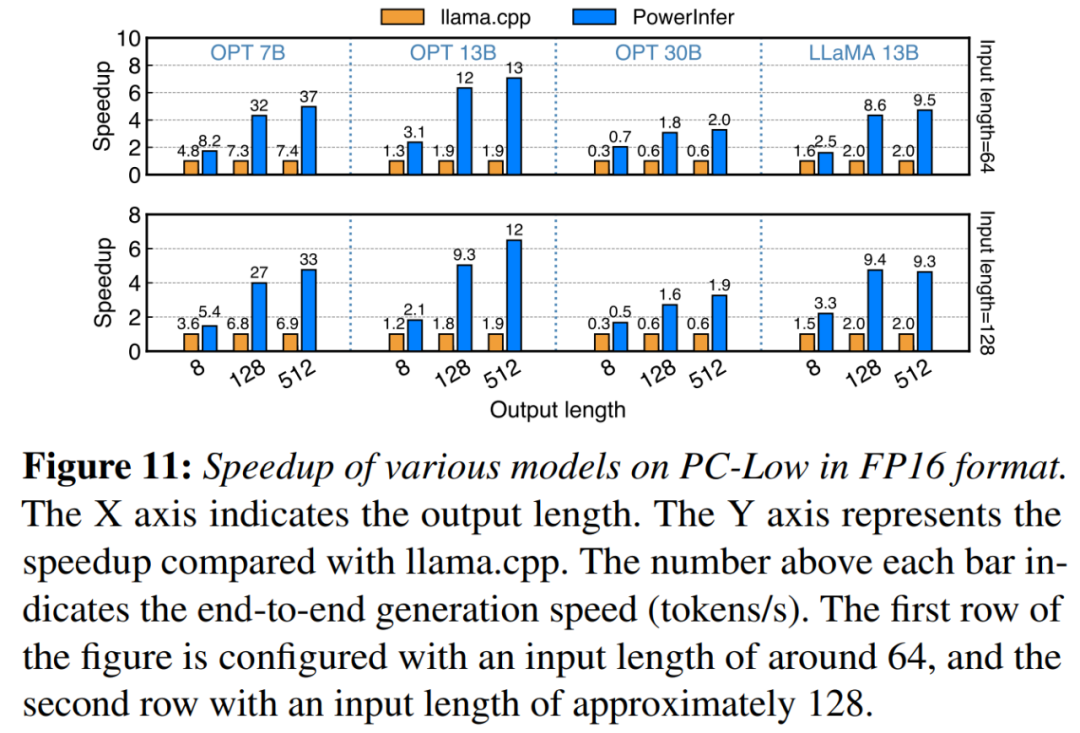
Figure 12 shows the neuron load distribution between CPU and GPU between PowerInfer and llama.cpp. Notably, on PC-High, PowerInfer significantly increases the GPU's neuron load share, from an average of 20% to 70%. This shows that the GPU processes 70% of the activated neurons. However, in cases where the memory requirements of the model far exceed the GPU capacity, such as running a 60GB model on an 11GB 2080Ti GPU, the neuron load on the GPU is reduced to 42%. This decrease is due to the limited memory of the GPU, which is not enough to accommodate all activated neurons, so the CPU is required to calculate a portion of the neurons

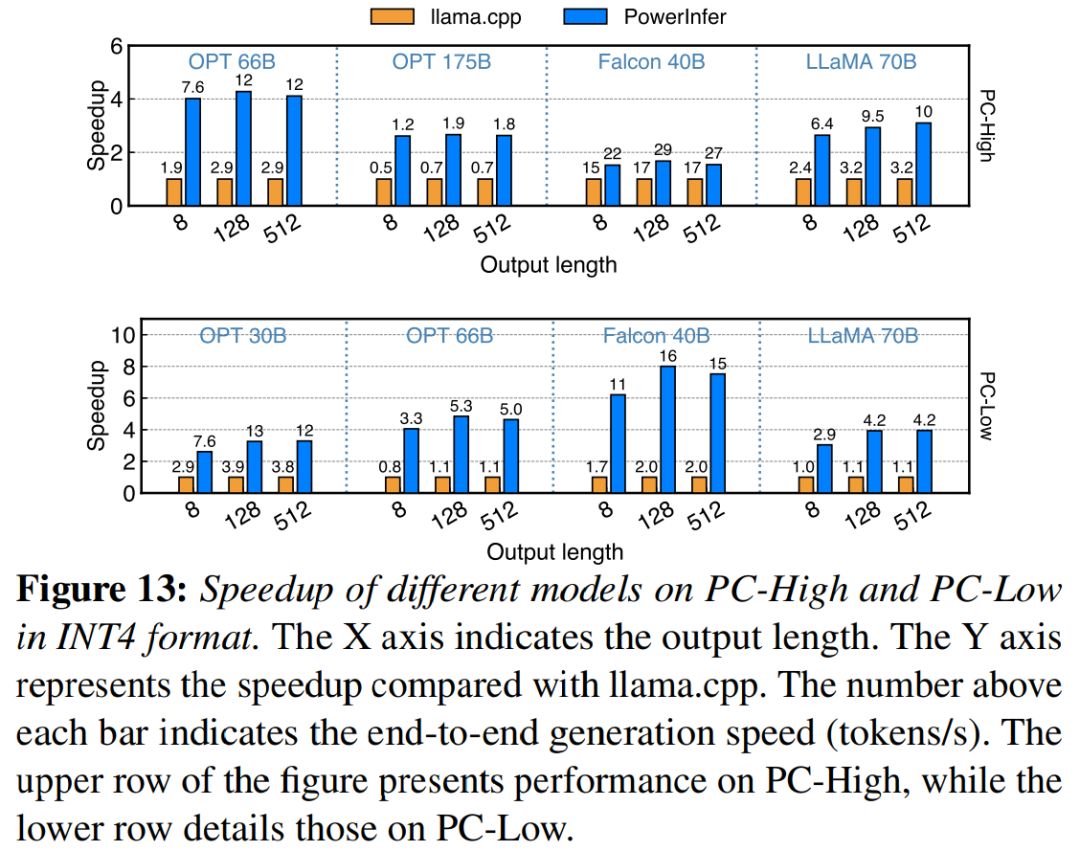
Figure 13 illustrates the use of PowerInfer effective support INT4 quantized compressed LLM. On PC-High, PowerInfer has an average response speed of 13.20 tokens/s, with a peak response speed of 29.08 tokens/s. Compared to llama.cpp, the average speedup is 2.89x and the maximum speedup is 4.28x. On PC-Low, the average speedup is 5.01x and the peak is 8.00x. The reduced memory requirements due to quantization allow PowerInfer to manage larger models more efficiently. For example, using the OPT-175B model on PC-High required rewriting the language into Chinese in order to rewrite the content without changing the original meaning. There is no need to appear in the original sentence, PowerInfer reaches almost two tokens per second, exceeding llama.cpp by 2.66 times.
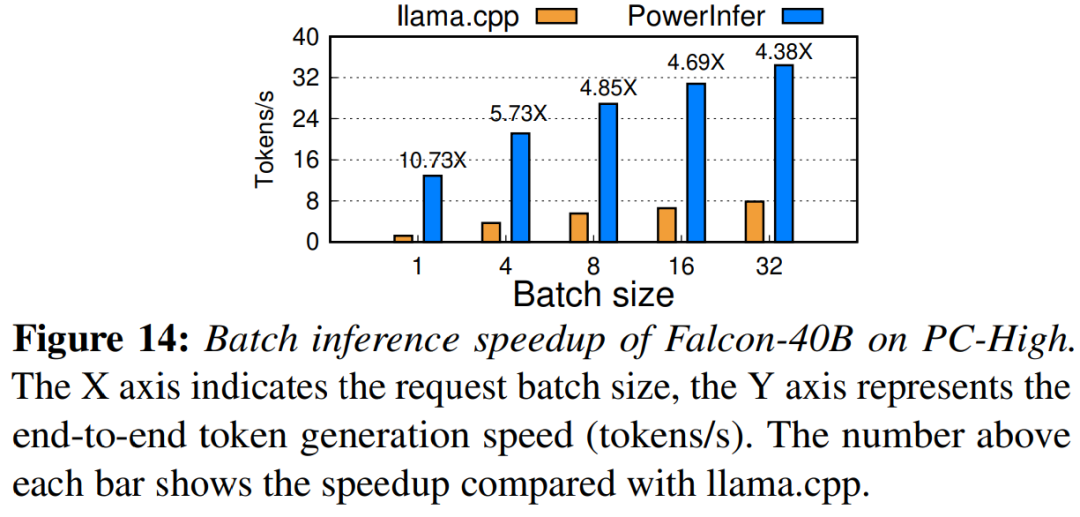
Finally, the study also evaluated the end-to-end inference performance of PowerInfer under different batch sizes. As shown in Figure 14, when the batch size is less than 32, PowerInfer shows significant advantages, with an average performance improvement of 6.08 times compared to llama. As the batch size increases, the speedup provided by PowerInfer decreases. However, even with the batch size set to 32, PowerInfer still maintains considerable speedup
Reference link: https://weibo.com/1727858283 /NxZ0Ttdnz
Please see the original paper for more information
The above is the detailed content of 4090 Generator: Compared with the A100 platform, the token generation speed is only less than 18%, and the submission to the inference engine has won hot discussions. For more information, please follow other related articles on the PHP Chinese website!