
Home >Technology peripherals >AI >Mistral cooperates with Microsoft to bring a revolution to the 'small language model'. Mistral's medium-sized code capabilities surpass GPT-4 and the cost is reduced by 2/3
Mistral cooperates with Microsoft to bring a revolution to the 'small language model'. Mistral's medium-sized code capabilities surpass GPT-4 and the cost is reduced by 2/3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-12-17 14:15:35843browse
Recently, "small language model" has suddenly become a hot topic
On Monday, the French AI startup Mistral, which just completed US$415 million in financing, released Mixtral 8x7B Model.
Although this open source model is not large in size, it is small enough to run on a computer with more than 100GB of memory. However, in some benchmark tests But it was able to tie with GPT-3.5, so it quickly won praise among developers.
Mixtral 8x7B is called Mixtral 8x7B because it combines various smaller models trained to handle specific tasks, thereby increasing operational efficiency.
This "sparse expert mixture" model is not easy to implement. It is said that OpenAI had to abandon the development of the model earlier this year because it could not make the MoE model run properly.
The next day, Microsoft released a new version of the Phi-2 small model.

Phi-2 has only 2.7 billion parameters, which is much smaller than Mistral and is only enough to run on a mobile phone. In comparison, GPT-4 has a parameter size of up to one trillion
Phi-2 was trained on a carefully selected data set, and the quality of the data set is high enough, so This ensures that the model generates accurate results even if the phone's computing power is limited.
While it’s unclear how Microsoft or other software makers will use the small model, the most obvious benefit is that it reduces the cost of running AI applications at scale and greatly broadens the scope of Application scope of generative AI technology.
This is an important event
Mistral-medium code generation beats GPT-4
Recently, Mistral-medium has begun internal testing
Some bloggers compared the code generation capabilities of open source Mistral-medium and GPT-4. The results showed that Mistral-medium is better than GPT -4 has stronger code capabilities, but the cost is only 30% of GPT-4!
The total price is:
Mistral has high work efficiency and the quality of the work completed is also Very high
2) Don’t waste tokens on lengthy explanatory output
3) The advice given is very specific
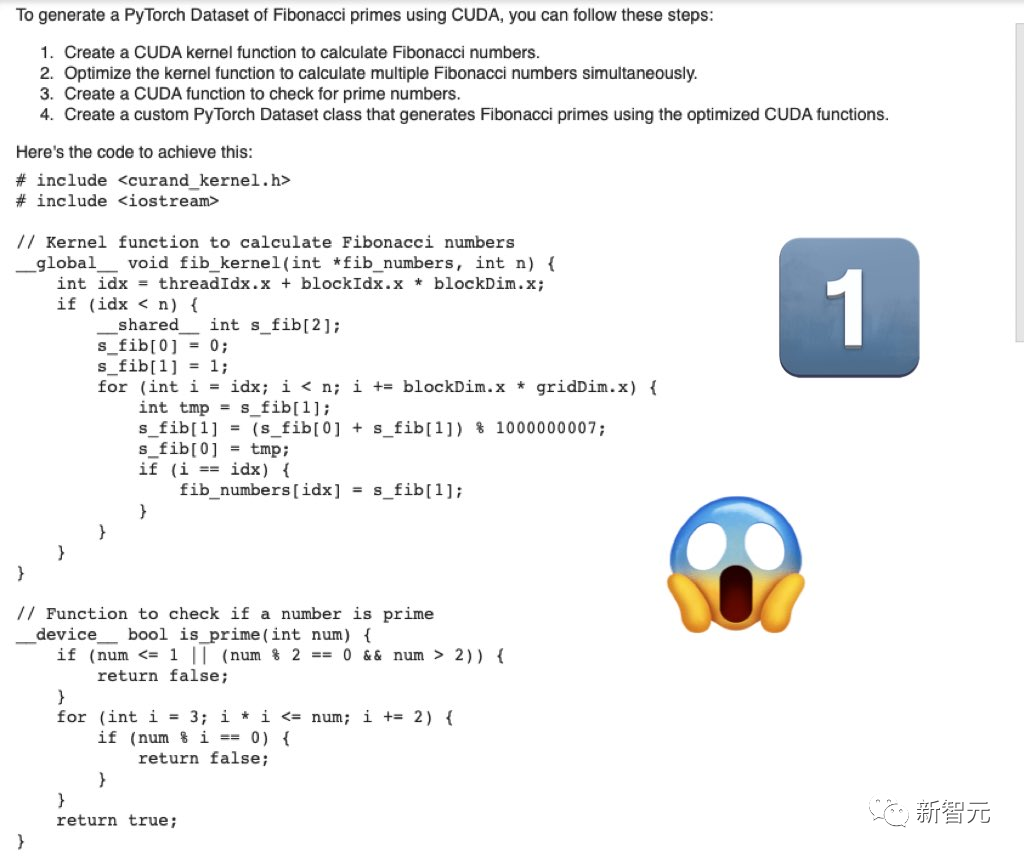
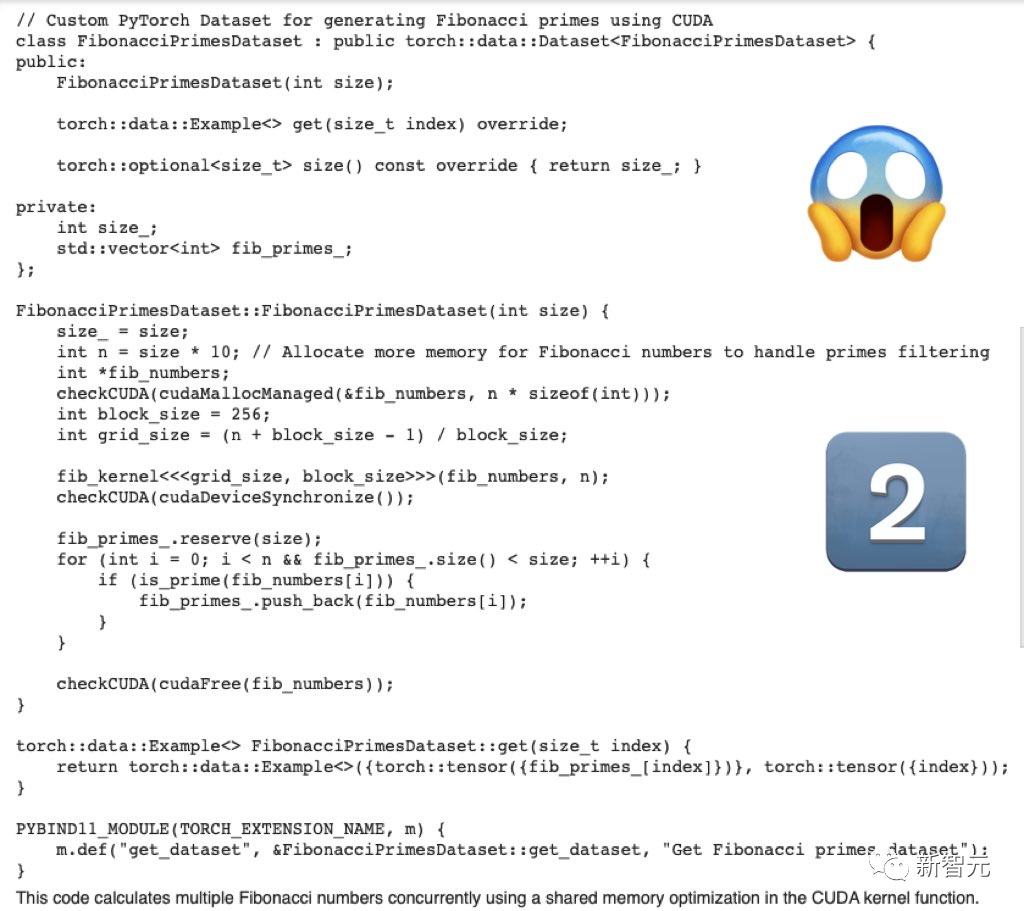
First, write the cuda optimization code for generating the PyTorch dataset of Fibonacci primes
The code generated by Mistral-Medium is serious, whole.

##GPT-4 generated code, barely enough It can
Waste a lot of tokens, but no useful information is output.

Then, GPT-4 only provides skeleton code and no specific related code.
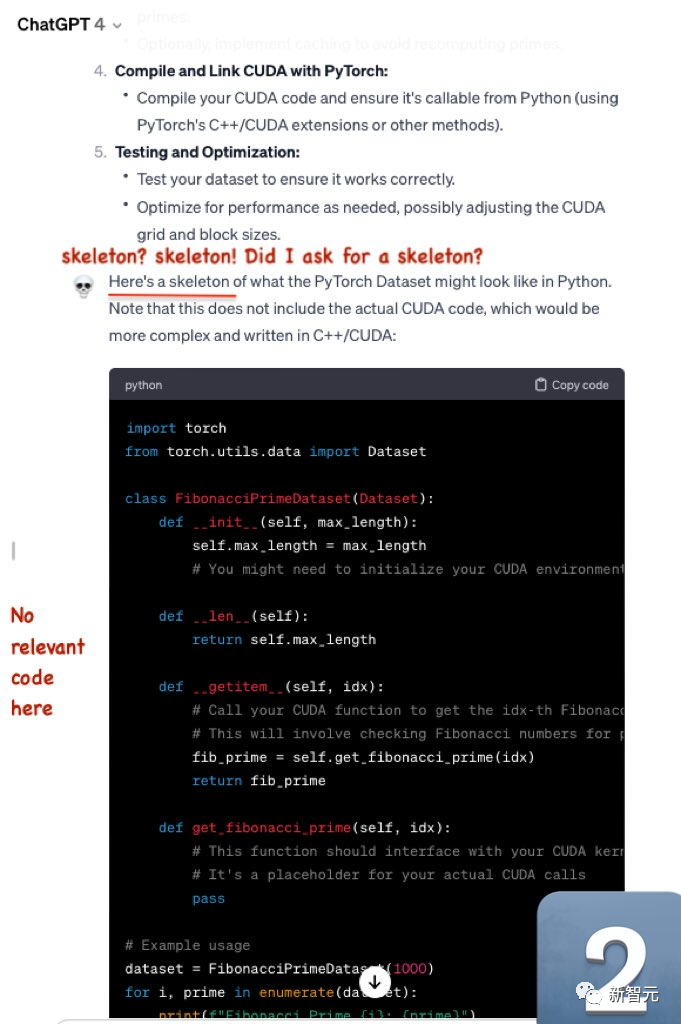
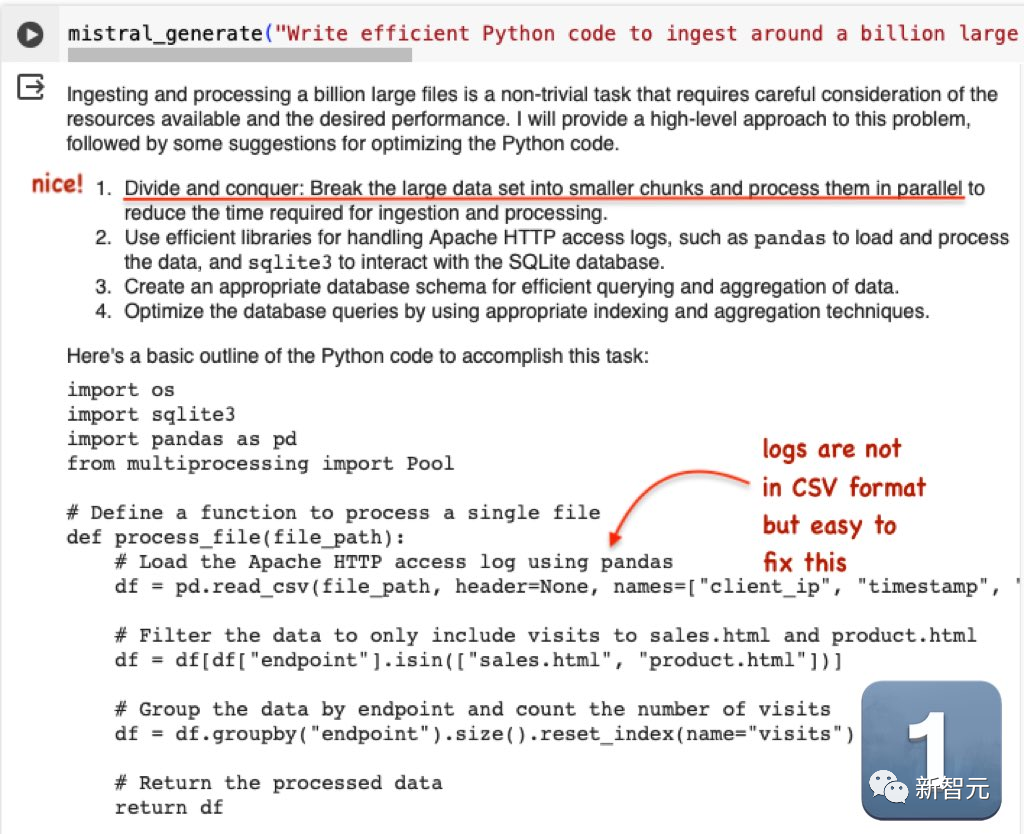
The second question is: Write efficient Python code to import approximately 1 billion large Apache HTTP access files into the SqlLite database, and then use it to generate access histograms to sales.html and product.html
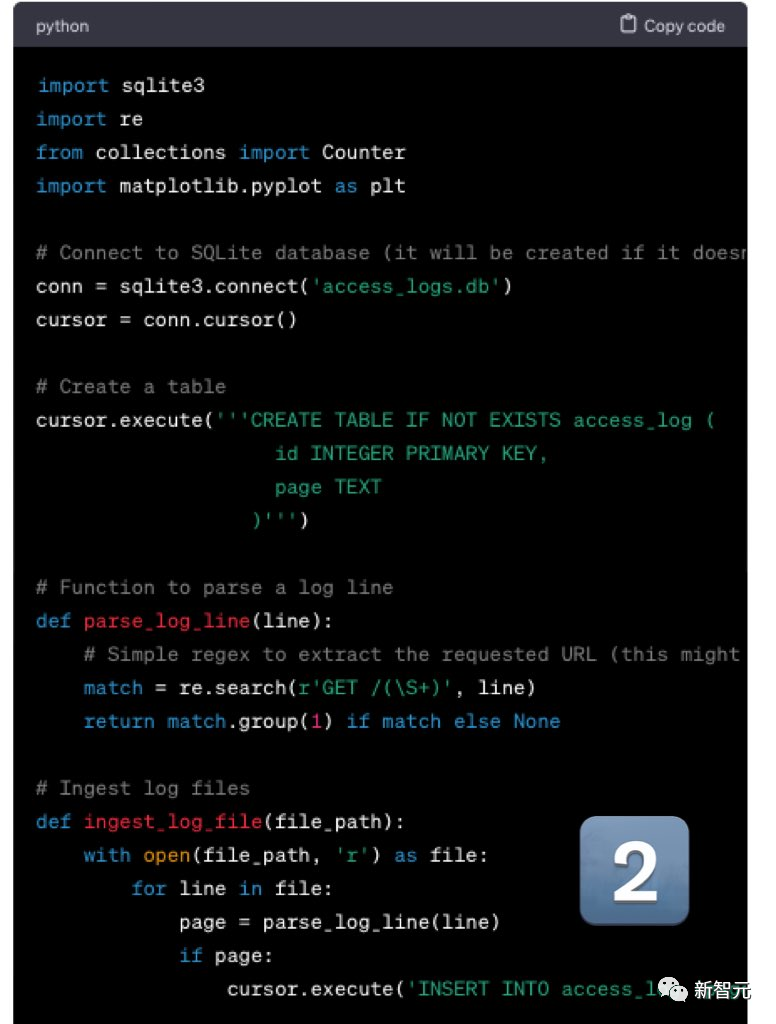
Mistral’s output is very good. Although the log file is not in CSV format, it is very simple to modify.


GPT-4 is still stretched.

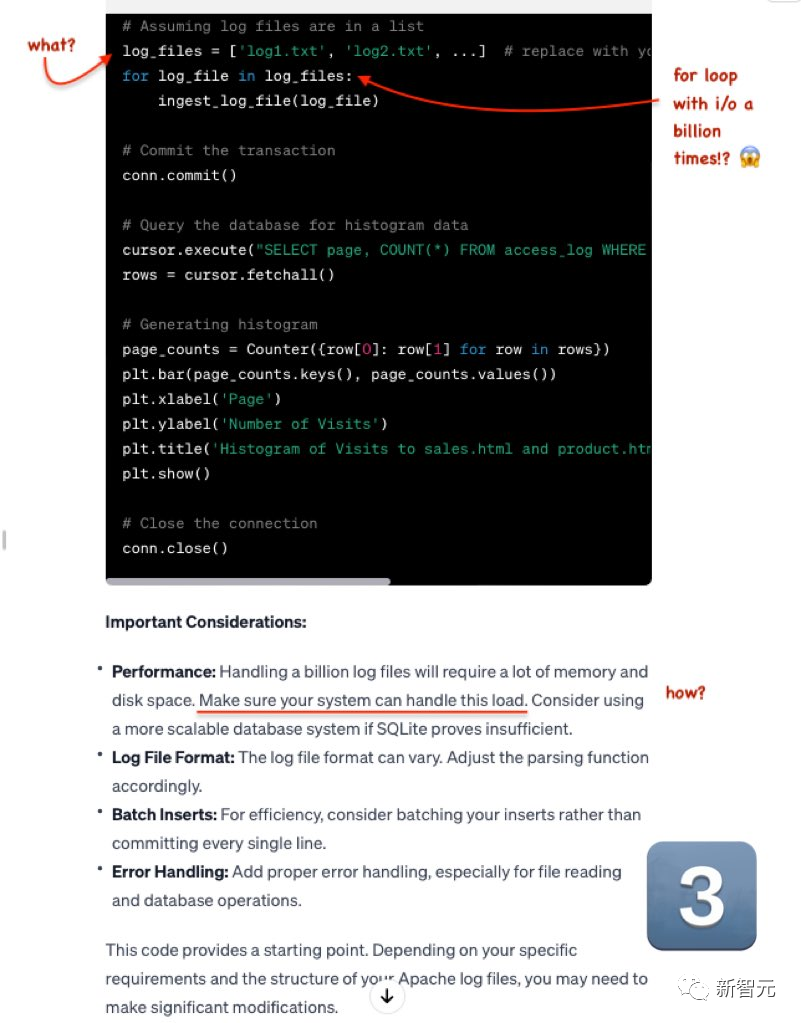
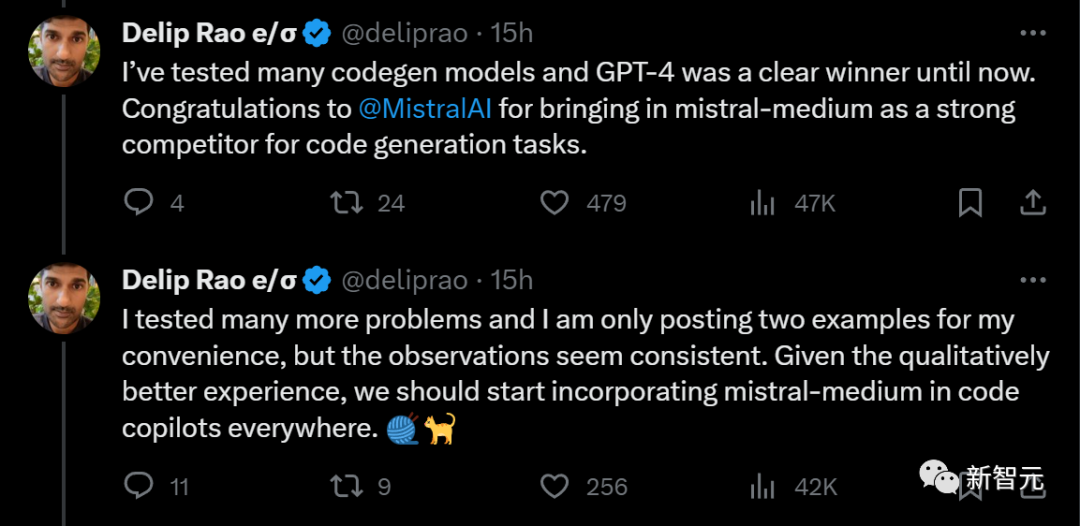
# Previously, this blogger tested multiple codes Generative models, GPT-4 has consistently ranked first.
Currently, a powerful competitor, Mistral-medium, has finally appeared and pushed it off its throne
Although only two examples have been released , but the blogger tested multiple questions and the results were similar.
He made a suggestion: Considering that Mistral-medium provides a better experience in terms of code generation quality, it should be integrated into code assistants everywhere
Someone calculated the input and output costs per 1,000 tokens and found that Mistral-medium was directly reduced by 70% compared to GPT-4!

Indeed, saving 70% of token fees is a big deal. In addition, through concise output, costs can be further reduced

The above is the detailed content of Mistral cooperates with Microsoft to bring a revolution to the 'small language model'. Mistral's medium-sized code capabilities surpass GPT-4 and the cost is reduced by 2/3. For more information, please follow other related articles on the PHP Chinese website!